數據庫高並發情形下反復值寫入的防止 字段組合束縛。本站提示廣大學習愛好者:(數據庫高並發情形下反復值寫入的防止 字段組合束縛)文章只能為提供參考,不一定能成為您想要的結果。以下是數據庫高並發情形下反復值寫入的防止 字段組合束縛正文
10線程同時操作,頻仍湧現拔出異樣數據的成績。固然在拔出數據的時刻應用了:
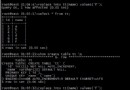
insert inti tablename(fields....) select @t1,@t2,@t3 from tablename where not exists (select id from tablename where t1=@t1,t2=@t2,t3=@t3)
其時照樣在高並發的情形下有效。此語句也包括在存儲進程中。(之前也測驗考試線斷定有沒有記載再看能否寫入,有效)。
是以,關於此類情形照樣須要從數據庫的基本來處理,就是束縛。不然數據庫的原子操作細不到我所須要的層面。
添加束縛的敕令行用得人不多,網上每次找SQL語句都累逝世,照樣寫上去好了。
須要的症結就叫做 字段組合束縛獨一性
alter table tablename add CONSTRAINT NewUniqueName Unique(t1,t2,t3)
如許可以包管三個字段組合不反復
在臨盆體系數據庫的調劑真是锱铢必較。。。。。。
關於數據庫讀操作的反復臨時沒有好的處理辦法,就是讀數據庫某些條目同時將這些條目某個字段修正為1,然後其他過程讀的時刻就不會反復讀取。然則在多線程情形下即便我應用了SQL SERVER 2005最新的特征,就是相似update...output into莅臨時表的辦法:
update tablename set OnCheck=1,LastLockTime=getdate(),LastChecktime=getdate()
output deleted.ID into @newtb
where ID in
(select id from tablename where Oncheck=0)
照樣會形成反復讀。豈非沒有更好的方法了嗎?
假如年夜家有更好的辦法,可以收回來。