mysql基礎知識掃盲。本站提示廣大學習愛好者:(mysql基礎知識掃盲)文章只能為提供參考,不一定能成為您想要的結果。以下是mysql基礎知識掃盲正文
本篇主要介紹關於mysql的一些非常基礎的知識,為後面的sql優化做准備。
一:連接mysql
關於mysql的下載和安裝我在這裡就不說了,第一步我們要連接我們的mysql服務器,打開cmd命令切換到你安裝MySQL Server 的bin目錄下,然後輸入mysql -h localhost -u root -p
其中-h 表示你的主機地址(本機就是localhost,記住不要帶端口號) -u 就是連接數據庫名稱 -p就是連接密碼。出現以下圖就表示連接成功了
二:常用的sql語句
2.1:創建數據庫 create database 數據庫名
2.2:刪除數據庫 drop database 數據庫名
2.3:查詢系統中的數據庫 show databases
2.4:使用數據庫 use 數據庫名
2.5:查詢數據庫的表 show tables
2.6:查詢表結構 desc +表名
2.7:查詢創建表的sql語句 show create table +表名
2.8:刪除表 drop +表名
2.9:一次刪除多條表記錄:delete t1,t2 from t1,t2[where 條件] 如果from後面用別名那麼delete後面也需要用別名
3.0:一次性更新多次表update t1,t2 ...tn set t1.field=expr1,tn.exprn=exprn;
三:查詢
3.1:select普通查詢
在這裡我創建了一個數據放了2個表,看下圖
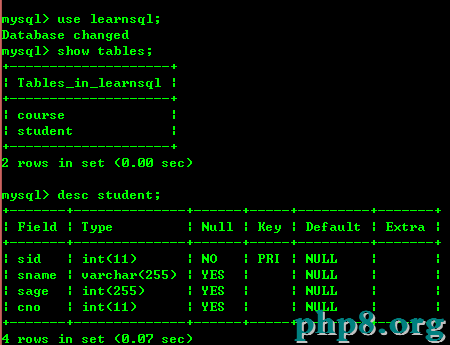
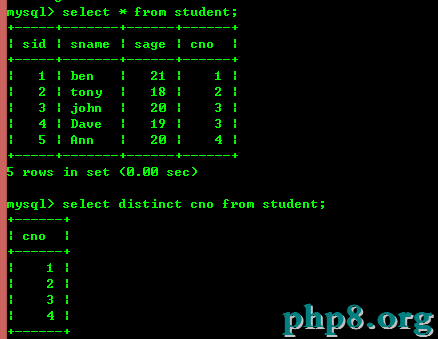
3.2:查詢不重復記錄
用關鍵字distinct如下圖
3.3:排序和限制
用關鍵字order by進行排序desc降序asc升序,limit關鍵字進行限制輸出

order by後面跟字段(order by只寫一次即可先排第一個字段然後第二個以此類推,limit 後面第一個數是索性,第二個是輸出的個數)。
四:聚合操作
很多情況下,用戶都需要進行一些統計,比如統計整個公司的人數或者部門的人數,這時就會用到聚合操作。聚合操作語法入戲下
select 【field1,field2...fieldn】fun_name from 表名
where 條件
group by field1,field2...fieldn
with rollup
having 條件
fun_name叫做聚合函數或者聚合操作,常見的有sum(求和)、 count(*)記錄數、 max(最大值)、min(最小值)。
group by 表示要分類聚合的字段,比如按照部門分類統計的員工數量,部門就應該寫在group by後面
with rollup 是可選語法,表示是否對分類聚合後的結合在進行匯總
having 表示對分類後的結果在次進行篩選
4.1:按照課程號進行統計班級的人數
4.2:按年級統計人數,並統計總人數
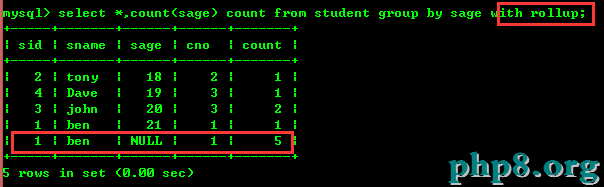
rollup就是進行人數匯總的,從圖中我們可以看出。
4.3:統計年齡不小於20的人數
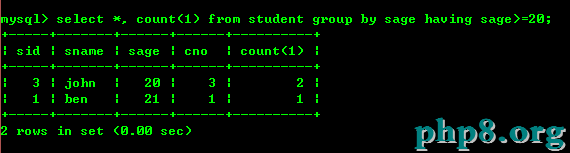
having和where的區別:having是對聚合後的結果進行篩選,而where是在聚合錢就對記錄進行篩選,如果邏輯允許,盡可能使用where先過濾記錄,這樣將減少結果集,對聚合的效率大大的提高,然後在根據having進行過濾。
五:表連接
如果需要同時顯示多個表中的字段的時候,就可以使用表連接來實現這樣的功能。從大類上可以分為內連接和外連接,他們的主要區別是:內連接僅僅篩選出2個表互相匹配的記錄,而外連接會篩選出其他不匹配的記錄,我們經常使用的是內連接。
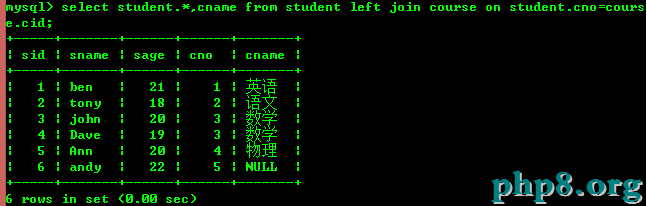
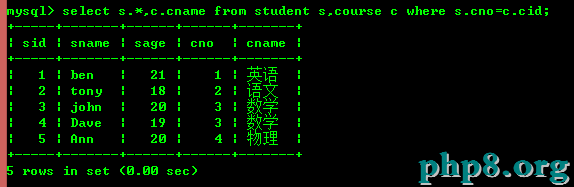
5.1:查詢學生所選擇的課程
外連接又分為左連接和右連接。
左連接(包含所有左邊表中的記錄甚至右邊表中沒有和它匹配的記錄)
右連接(包含所有右邊表中的記錄甚至左邊表中沒有和它匹配的記錄)
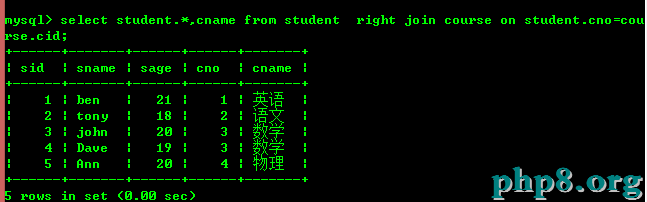
從中可以看出左連接是以左邊的表為主,右連接是以右邊的表為主。
六:子查詢
某些情況下,當進行查詢的時候,需要的條件是另外一個select語句的結果,這個時候就用到了子查詢,用於子查詢的關鍵字主要包括in、not in、=、!=、exist、not exist等
如使用in進行查詢
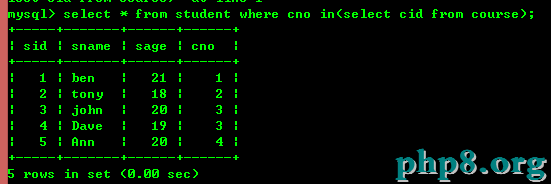
但是使用內連接同樣能達到以上的效果
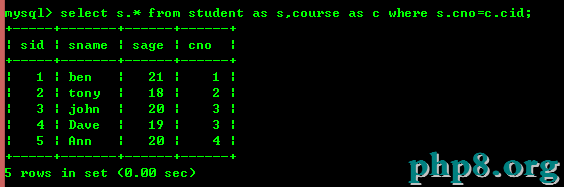
但是內連接的效率在很多情況下都是高於子查詢的,所以如果不影響業務邏輯的前提下優先考慮內聯。
七:聯合
將2個表的數據按照一定規則下查詢出來,將結果合並一起顯示出來。這個時候我們就可以使用union或者union all。具體語法如下
select * from t1 union\union all select * from t2 union\union all select * from tn;
union和union all的區別在於union是在篩選的結果集去除重復的記錄。
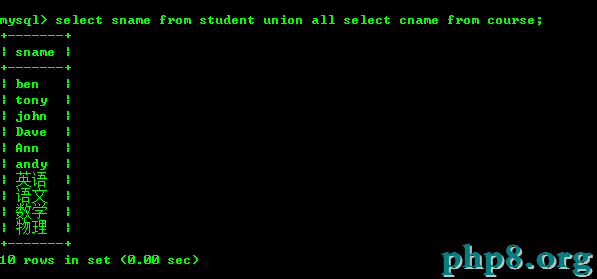
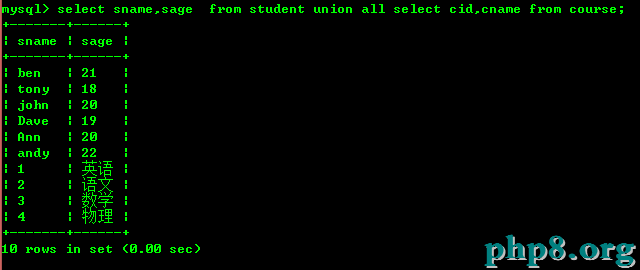
切記不可以2個表不匹配就進行聯合,如下

如果我們每個表都查詢2個字段
八:常見的函數
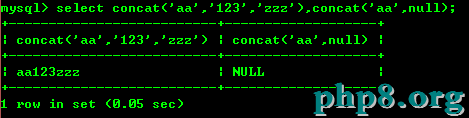
8.1:concat
cancat函數:把傳入的參數連成一個字符串,任何字符串和null進行拼接的結果都是null,如下圖
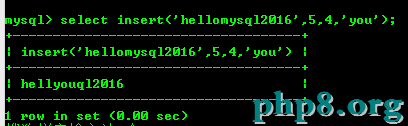
8.2:insert(str,x,y,instr)函數,將字符串str從第X個位置開始,y個字符長的字符串替換成instr下面把字符串hellomysql2016的第5個字符後面的4個字符替換成you
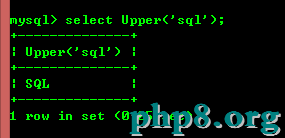
8.3:Lower(Str)和Upper(Str)把字符串轉換成小寫或者大寫。
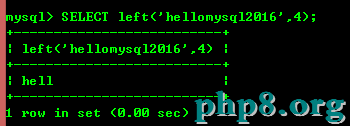
8.4:left(str,x)和right(str,x)分別返回字符串最左邊的x個字符和最右邊的x個字符,如果第二個參數為null,不返回任何字符
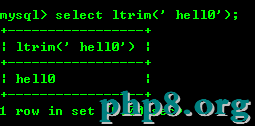
8.5:ltrim(str)和rtrim(str)去掉字符串左邊或者右邊的字符
8.6:repeat(str,x):返回str重復x次的結果
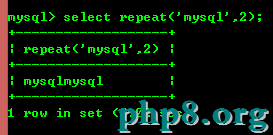
8.7:replace(str,a,b)用字符串b替換字符串str中所有出現字符串a。
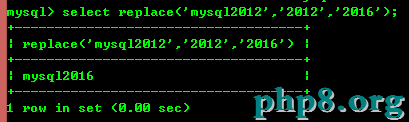
8.8:trim(str)去掉開頭和結尾的空格
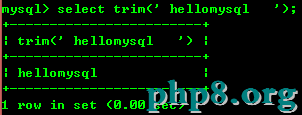
8.9:substring(str,x,y):返回從字符串str中的第x個位置起y個字符串長度的字符串。
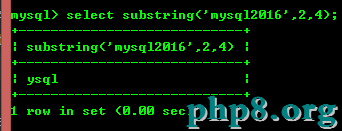
以上就是本文的全部內容,希望本文的內容對大家的學習或者工作能帶來一定的幫助,同時也希望多多支持!
[db:作者簡介][db:原文翻譯及解析]