SQLServer性能優化--間接實現函數索引或者Hash索引。本站提示廣大學習愛好者:(SQLServer性能優化--間接實現函數索引或者Hash索引)文章只能為提供參考,不一定能成為您想要的結果。以下是SQLServer性能優化--間接實現函數索引或者Hash索引正文
SQLServer中沒有函數索引,在某些場景下查詢的時候要根據字段的某一部分做查詢或者經過某種計算之後做查詢,如果使用函數或者其他方式作用在字段上之後,就會限制到索引的使用,不過我們可以間接地實現類似於函數索引的功能。
另外一個就是如果查詢字段較大或者字段較多的時候,所建立的索引就顯得有點笨重,效率也不高,就需要考慮使用一個較小的"替代性"字段做等價替換,類似於Hash索引,
本文粗淺地介紹兩種上述兩種問題的解決方式,僅供參考。
1,在計算列上建索引,實現“函數索引”的功能
SQLServer在建表的時候允許使用計算列,可以借助這個計算列來實現函數索引的功能,這裡舉例說明一下
Create Table TestFunctionIndex ( id int identity(1,1), val varchar(50), subval as LOWER(SUBSTRING(val,10,4)) persisted --增加一個持久化計算列 ) GO --在持久化計算列上建立索引 create index idx_subvar on TestFunctionIndex(subval) GO --插入10W行測試數據 insert into TestFunctionIndex(val) values (NEWID()) go 100000
在有索引的字段上使用函數之後,是無法使用索引的
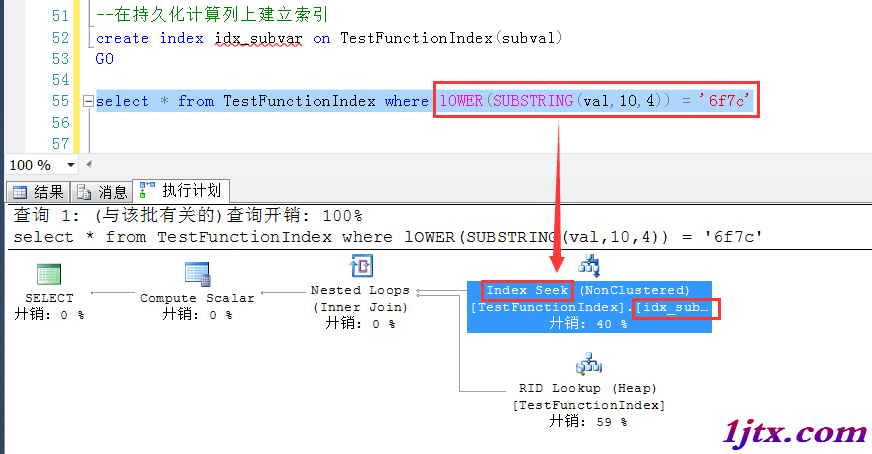
如果直接在計算列上查詢,就可以正常地使用到索引了
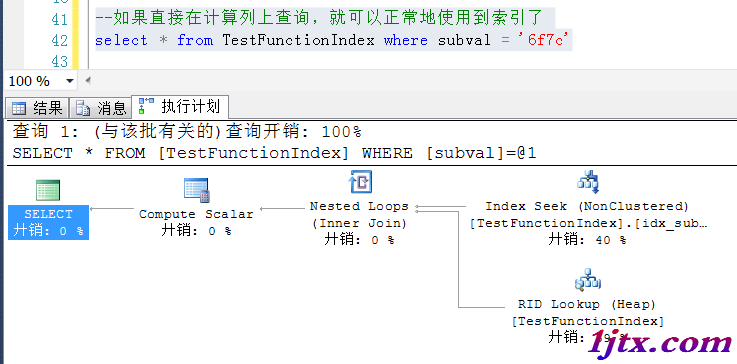
以上通過在計算列上建立一個索引,可以根據計算列上的索引做查找,避免了直接在字段上使用函數或者其他操作,造成即便字段上有索引也用不到的情況
補充:
測試中神奇地發現,如果計算列字段上建立了索引,在原始字段上使用函數與計算列的函數一樣的時候,可以神奇地使用到計算列上的索引。可見SQLServer在我們沒有注意的地方也是下了不少功夫的啊
2,生成較長字段或者多個字段的Hash值替代原始字段做查詢或者連接來提升查詢效率
開發中遇到另外一種常見的情況是經常使用到的查詢條件字段較長,或者是表連接的時候連接條件字段較多,
即便是字段或者查詢條件上有索引,但是因為字段較長或者條件較多,此時有可能會影響到查詢的效率
這種情況就適當考慮將原始的較長的字段生成一個較小的字段(但是要確保唯一性),或者是講多個字段生成一個較短的數據類型做替代,以提高查詢的效率
舉個例子,假如有這麼一張表,Name字段是我模擬出來的,Name是一個比較長的字段,又要用來做檢索
意思就是查詢字段較長,索引代價太大,此時就需要考慮用一種較小的等價字段來替代
下面通過某種方式計算較長字段的Hash值,來做等價替換
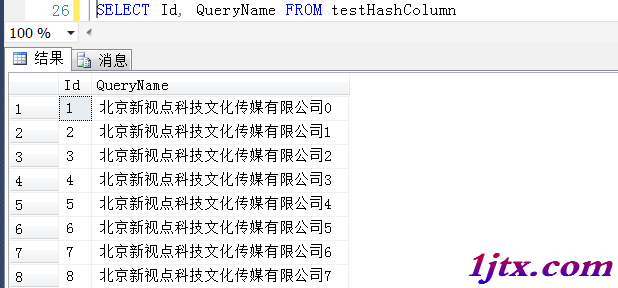
模擬生成一下測試數據
Create table testHashColumn
(
id int identity(1,1),
QueryName nvarchar(100),
HashName AS CAST( HASHBYTES('MD2',QueryName) AS UNIQUEIDENTIFIER) persisted
)
GO
create index idx_HashName ON testHashColumn(HashName)
GO
--這裡模擬生成一個較長的名字字段
DECLARE @i int = 0
while @i<10000
begin
INSERT INTO testHashColumn (QueryName) VALUES (CONCAT('北京新視點科技文化傳媒有限公司',@i))
set @i = @i+1
end
我們知道,Name這個名字是nvarchar(100)的,這個字段做索引不是不可以,如果情況復雜,實際中有可能比這個字段更大,做索引顯得太寬了,造成索引空間過大,在效率上有一定程度的影響。
這裡就可以考慮在Name這個字段上生成一個“替代”字段(上述HashName AS CAST( HASHBYTES('MD2',QueryName) AS UNIQUEIDENTIFIER) persisted這個計算列),
這個字段首選是要跟實際值一一對應的,另外就是要求“替代”的字段類型要求相對較小,當然方法也有多種,比如生成利用checksum函數生成一個校驗值,但是據實際觀察checksum生成的校驗值是有可能重復的,也就是說兩個不同的字符串,生成同一個校驗值
比如這樣,很容易驗證出來這個問題,可以認為是對於不同的字符串,計算之後得到同一個校驗和
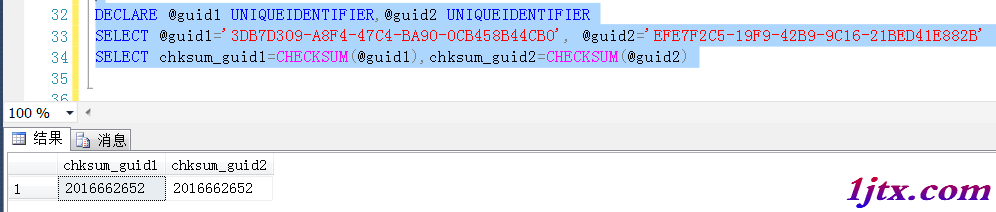
因此在生成“替代”字段的時候,需要考慮計算值的唯一性
這裡使用的是HASHBYTES加密函數,對字符串加密,然後對加密之後的數據生成一個UNIQUEIDENTIFIER,重復的概率就小的多的多了
演示這裡通過CAST( HASHBYTES('MD2','北京新視點科技文化傳媒有限公司999') AS UNIQUEIDENTIFIER)的方式,就可以給這個較長的字段生成一個UNIQUEIDENTIFIER類型的字段,
當然也不一定只有這一種方法,甚至可以做的跟復雜,只要能保證一個唯一的長字段生成的較短的字段也是唯一的就可以達到目的了
參考如下查詢,就可以使用HashName計算出來的值與計算列做比較,在一定程度上可以減少檢索字段索引的大小,又能達到目的的效果
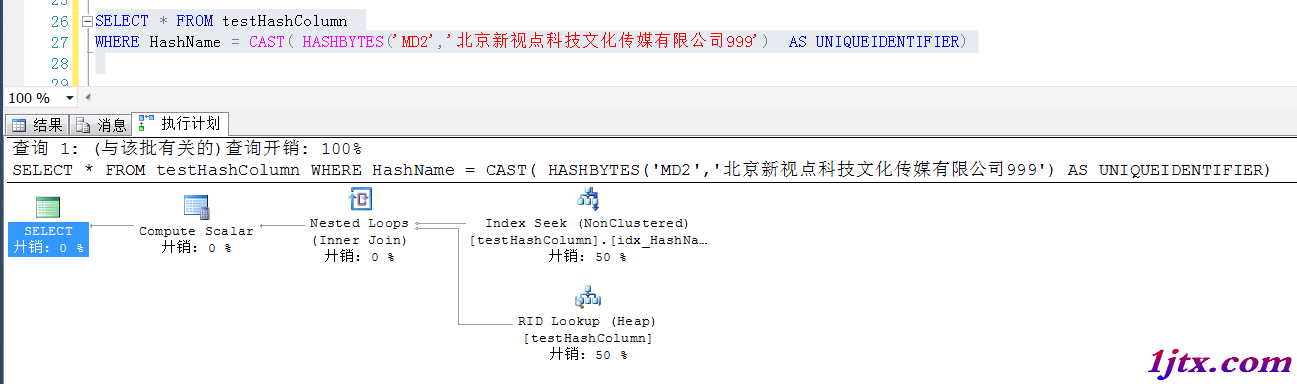
如截圖,就可以使用HashName字段上的索引了,同時也避免了在原始的QueryName這個較長的字段上建索引,節約了空間並提高了查詢效率
3, 邏輯主鍵為多個字段的時候,在多了字段上生成一個“替代”性的唯一字段
某些情況下業務需求或者設計也好(比如沒有達到第三范式,BC范式,第四范式,甚至是第五范式),在表連接的時候往往會有多個字段
比如這種樣子:
SELECT *
FROM TableNameA a
INNER JOIN TableNameB b
ON a.key=b.key
AND a.Type = b.Type
AND a.Status = b.Staus
AND a.CreationTime = b.CreationTime
AND a.***=b.***
where ***
在表關聯的時候,連接條件很多,如果是這樣子,最好的情況就是建立一個較寬的復合索引,但是這樣的話,索引的寬度和體積就變得很大,使用的時候效率也有一定的影響。這種情況就可以考慮在TableNameA 和 TableNameB 上,利用多個連接的字段(Key+Type +Status +CreationTime+***)做了類似於示例2中的一個計算列,在計算列上建立一個索引,然後再表連接的時候就可以用如下的方式替代
SELECT * FROM TableNameA a INNER JOIN TableNameB b ON a.HashValue=b.HashValue WHERE ***
總是,這是一種以空間換時間的思路(冗余存儲一個類似於標識符的字段,提高查詢效率),在生成“替代”字段的思想有兩點,第一要足夠的小,第二要原始值生成替代字段的唯一性
總結:SQLServer 中沒有函數索引和Hash索引,而某些業務需求或者說是為了性能考慮,又需要類似的功能,通過類似於空間換時間的方法來實現,可以變通地來實現類似於函數索引或者Hash索引的功能,已達到其他數據庫中函數索引和Hash索引的效果(雖然原理可能不一樣)。需要注意的就是在生成計算列或者說Hash值替代的時候要注意計算方式,確保生成之後的Key值的唯一性。當然實現方式就可以根據需要自行選擇了,條條大路通羅馬。
以上就是本文的全部內容,希望本文的內容對大家的學習或者工作能帶來一定的幫助,同時也希望多多支持!