PostgreSQL的DISTINCT關鍵字用於與SELECT語句消除所有重復的記錄,並獲取唯一記錄。
有可能的情況下,當你有多個重復的表中的記錄。雖然取這樣的記錄,它更有意義,獲取唯一的記錄,而不是獲取重復記錄。
DISTINCT關鍵字消除重復記錄的基本語法如下:
SELECT DISTINCT column1, column2,.....columnN FROM table_name WHERE [condition]
考慮表COMPANY 有如下記錄:
# select * from COMPANY; id | name | age | address | salary ----+-------+-----+-----------+-------- 1 | Paul | 32 | California| 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall| 45000 7 | James | 24 | Houston | 10000 (7 rows)
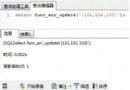
讓我們添加兩個記錄到這個表如下:
INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) VALUES (8, 'Paul', 32, 'California', 20000.00 ); INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY) VALUES (9, 'Allen', 25, 'Texas', 15000.00 );
現在,該公司表中的記錄將是:
id | name | age | address | salary ----+-------+-----+------------+-------- 1 | Paul | 32 | California | 20000 2 | Allen | 25 | Texas | 15000 3 | Teddy | 23 | Norway | 20000 4 | Mark | 25 | Rich-Mond | 65000 5 | David | 27 | Texas | 85000 6 | Kim | 22 | South-Hall | 45000 7 | James | 24 | Houston | 10000 8 | Paul | 32 | California | 20000 9 | Allen | 25 | Texas | 15000 (9 rows)
首先,讓我們來看看下面的SELECT查詢返回重復的工資記錄:
testdb=# SELECT name FROM COMPANY;
這將產生以下結果:
name ------- Paul Allen Teddy Mark David Kim James Paul Allen (9 rows)
現在,讓我們使用DISTINCT關鍵字與上述SELECT查詢看到的結果:
testdb=# SELECT DISTINCT name FROM COMPANY;
我們沒有任何重復的條目,這將產生以下結果:
name ------- Teddy Paul Mark David Allen Kim James (7 rows)