一、數值類型:
下面是PostgreSQL所支持的數值類型的列表和簡單說明:
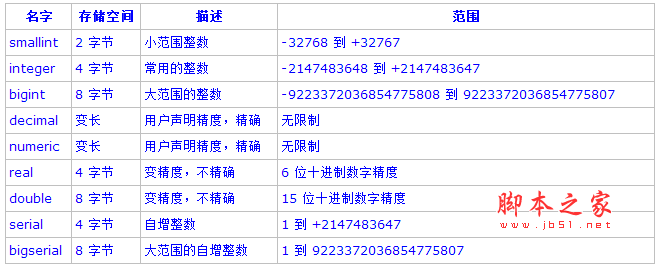
1. 整數類型:
類型smallint、integer和bigint存儲各種范圍的全部是數字的數,也就是沒有小數部分的數字。試圖存儲超出范圍以外的數值將導致一個錯誤。常用的類型是integer,因為它提供了在范圍、存儲空間和性能之間的最佳平衡。一般只有在磁盤空間緊張的時候才使用smallint。而只有在integer的范圍不夠的時候才使用bigint,因為前者(integer)絕對快得多。
2. 任意精度數值:
類型numeric可以存儲最多1000位精度的數字並且准確地進行計算。因此非常適合用於貨幣金額和其它要求計算准確的數量。不過,numeric類型上的算術運算比整數類型或者浮點數類型要慢很多。
numeric字段的最大精度和最大比例都是可以配置的。要聲明一個類型為numeric的字段,你可以用下面的語法:
復制代碼 代碼如下:
NUMERIC(precision,scale)
比如數字23.5141的精度為6,而刻度為4。
在目前的PostgreSQL版本中,decimal和numeric是等效的。
3. 浮點數類型:
數據類型real和double是不准確的、犧牲精度的數字類型。不准確意味著一些數值不能准確地轉換成內部格式並且是以近似的形式存儲的,因此存儲後再把數據打印出來可能顯示一些缺失。
4. Serial(序號)類型:
serial和bigserial類型不是真正的類型,只是為在表中設置唯一標識做的概念上的便利。
復制代碼 代碼如下:
CREATE TABLE tablename (
colname SERIAL
);
等價於
復制代碼 代碼如下:
CREATE SEQUENCE tablename_colname_seq;
CREATE TABLE tablename(
colname integer DEFAULT nextval('tablename_colname_seq') NOT NULL
);
這樣,我們就創建了一個整數字段並且把它的缺省數值安排為從一個序列發生器取值。應用了一個NOT NULL約束以確保空值不會被插入。在大多數情況下你可能還希望附加一個UNIQUE或者PRIMARY KEY約束避免意外地插入重復的數值,但這個不是自動發生的。因此,如果你希望一個序列字段有一個唯一約束或者一個主鍵,那麼你現在必須聲明,就像其它數據類型一樣。
還需要另外說明的是,一個serial類型創建的序列在其所屬字段被刪除時,該序列也將被自動刪除,但是其它情況下是不會被刪除的。因此,如果你想用同一個序列發生器同時給幾個字段提供數據,那麼就應該以獨立對象的方式創建該序列發生器。
二、字符類型:
下面是PostgreSQL所支持的字符類型的列表和簡單說明:
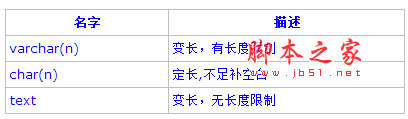
SQL 定義了兩種基本的字符類型,varchar(n)和char(n),這裡的n是一個正整數。兩種類型都可以存儲最多n個字符長的字串,試圖存儲更長的字串到這些類型的字段裡會產生一個錯誤,除非超出長度的字符都是空白,這種情況下該字串將被截斷為最大長度。如果沒有長度聲明,char等於char(1),而varchar則可以接受任何長度的字串。
復制代碼 代碼如下:
MyTest=> CREATE TABLE testtable(first_col varchar(2));
CREATE TABLE
MyTest=> INSERT INTO testtable VALUES('333'); --插入字符串的長度,超過其字段定義的長度,因此報錯。
ERROR: value too long for type character varying(2)
--插入字符串中,超出字段定義長度的部分是空格,因此可以插入,但是空白符被截斷。
MyTest=> INSERT INTO testtable VALUES('33 ');
INSERT 0 1
MyTest=> SELECT * FROM testtable;
first_col
-----------
33
(1 row)
這裡需要注意的是,如果是將數值轉換成char(n)或者varchar(n),那麼超長的數值將被截斷成n個字符,而不會拋出錯誤。
復制代碼 代碼如下:
MyTest=> select 1234::varchar(2);
varchar
---------
12
(1 row)
最後需要提示的是,這三種類型之間沒有性能差別,只不過是在使用char類型時增加了存儲尺寸。雖然在某些其它的數據庫系統裡,char(n)有一定的性能優勢,但在PostgreSQL裡沒有。在大多數情況下,應該使用text或者varchar。
三、日期/時間類型:
下面是PostgreSQL所支持的日期/時間類型的列表和簡單說明:
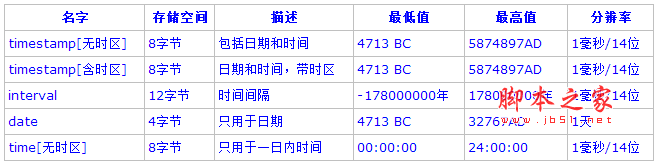
1. 日期/時間輸入:
任何日期或者時間的文本輸入均需要由單引號包圍,就象一個文本字符串一樣。
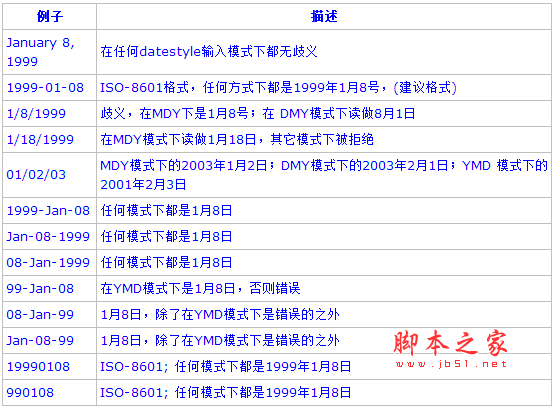
1). 日期:
以下為合法的日期格式列表:
2). 時間:
以下為合法的時間格式列表:
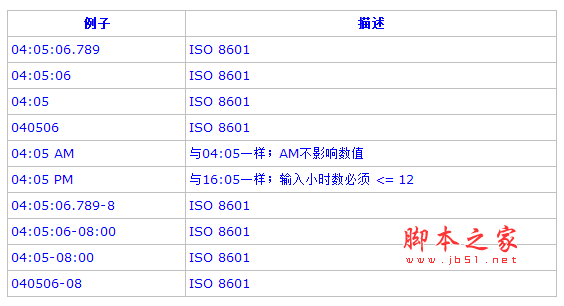
3). 時間戳:
時間戳類型的有效輸入由一個日期和時間的聯接組成,後面跟著一個可選的時區。因此,1999-01-08 04:05:06和1999-01-08 04:05:06 -8:00都是有效的數值。
2. 示例:
1). 在插入數據之前先查看datestyle系統變量的值:
復制代碼 代碼如下:
MyTest=> show datestyle;
DateStyle
-----------
ISO, YMD
(1 row)
2). 創建包含日期、時間和時間戳類型的示例表:
復制代碼 代碼如下:
MyTest=> CREATE TABLE testtable (id integer, date_col date, time_col time, timestamp_col timestamp);
CREATE TABLE
3). 插入數據:
復制代碼 代碼如下:
MyTest=> INSERT INTO testtable(id,date_col) VALUES(1, DATE'01/02/03'); --datestyle為YMD
INSERT 0 1
MyTest=> SELECT id, date_col FROM testtable;
id | date_col
----+------------
1 | 2001-02-03
(1 row)
MyTest=> set datestyle = MDY;
SET
MyTest=> INSERT INTO testtable(id,date_col) VALUES(2, DATE'01/02/03'); --datestyle為MDY
INSERT 0 1
MyTest=> SELECT id,date_col FROM testtable;
id | date_col
----+------------
1 | 2001-02-03
2 | 2003-01-02
MyTest=> INSERT INTO testtable(id,time_col) VALUES(3, TIME'10:20:00'); --插入時間。
INSERT 0 1
MyTest=> SELECT id,time_col FROM testtable WHERE time_col IS NOT NULL;
id | time_col
----+----------
3 | 10:20:00
(1 row)
MyTest=> INSERT INTO testtable(id,timestamp_col) VALUES(4, DATE'01/02/03');
INSERT 0 1
MyTest=> INSERT INTO testtable(id,timestamp_col) VALUES(5, TIMESTAMP'01/02/03 10:20:00');
INSERT 0 1
MyTest=> SELECT id,timestamp_col FROM testtable WHERE timestamp_col IS NOT NULL;
id | timestamp_col
----+---------------------
4 | 2003-01-02 00:00:00
5 | 2003-01-02 10:20:00
(2 rows)
四、布爾類型:
PostgreSQL支持標准的SQL boolean數據類型。boolean只能有兩個狀態之一:真(True)或 假(False)。該類型占用1個字節。
"真"值的有效文本值是:
復制代碼 代碼如下:
TRUE
't'
'true'
'y'
'yes'
'1'
而對於"假"而言,你可以使用下面這些:
復制代碼 代碼如下:
FALSE
'f'
'false'
'n'
'no'
'0'
見如下使用方式:
復制代碼 代碼如下:
MyTest=> CREATE TABLE testtable (a boolean, b text);
CREATE TABLE
MyTest=> INSERT INTO testtable VALUES(TRUE, 'sic est');
INSERT 0 1
MyTest=> INSERT INTO testtable VALUES(FALSE, 'non est');
INSERT 0 1
MyTest=> SELECT * FROM testtable;
a | b
---+---------
t | sic est
f | non est
(2 rows)
MyTest=> SELECT * FROM testtable WHERE a;
a | b
---+---------
t | sic est
(1 row)
MyTest=> SELECT * FROM testtable WHERE a = true;
a | b
---+---------
t | sic est
(1 row)
五、位串類型:
位串就是一串1和0的字串。它們可以用於存儲和視覺化位掩碼。我們有兩種類型的SQL位類型:bit(n)和bit varying(n); 這裡的n是一個正整數。bit類型的數據必須准確匹配長度n; 試圖存儲短些或者長一些的數據都是錯誤的。類型bit varying數據是最長n的變長類型;更長的串會被拒絕。寫一個沒有長度的bit等效於bit(1),沒有長度的bit varying相當於沒有長度限制。
針對該類型,最後需要提醒的是,如果我們明確地把一個位串值轉換成bit(n),那麼它的右邊將被截斷或者在右邊補齊零,直到剛好n位,而不會拋出任何錯誤。類似地,如果我們明確地把一個位串數值轉換成bit varying(n),如果它超過n位,那麼它的右邊將被截斷。 見如下具體使用方式:
復制代碼 代碼如下:
MyTest=> CREATE TABLE testtable (a bit(3), b bit varying(5));
CREATE TABLE
MyTest=> INSERT INTO testtable VALUES (B'101', B'00');
INSERT 0 1
MyTest=> INSERT INTO testtable VALUES (B'10', B'101');
ERROR: bit string length 2 does not match type bit(3)
MyTest=> INSERT INTO testtable VALUES (B'10'::bit(3), B'101');
INSERT 0 1
MyTest=> SELECT * FROM testtable;
a | b
-----+-----
101 | 00
100 | 101
(2 rows)
MyTest=> SELECT B'11'::bit(3);
bit
-----
110
(1 row)
六、數組:
1. 數組類型聲明:
1). 創建字段含有數組類型的表。
復制代碼 代碼如下:
CREATE TABLE sal_emp (
name text,
pay_by_quarter integer[] --還可以定義為integer[4]或integer ARRAY[4]
);
2). 插入數組數據:
復制代碼 代碼如下:
MyTest=# INSERT INTO sal_emp VALUES ('Bill', '{11000, 12000, 13000, 14000}');
INSERT 0 1
MyTest=# INSERT INTO sal_emp VALUES ('Carol', ARRAY[21000, 22000, 23000, 24000]);
INSERT 0 1
MyTest=# SELECT * FROM sal_emp;
name | pay_by_quarter
--------+---------------------------
Bill | {11000,12000,13000,14000}
Carol | {21000,22000,23000,24000}
(2 rows)
2. 訪問數組:
和其他語言一樣,PostgreSQL中數組也是通過下標數字(寫在方括弧內)的方式進行訪問,只是PostgreSQL中數組元素的下標是從1開始n結束。
復制代碼 代碼如下:
MyTest=# SELECT pay_by_quarter[3] FROM sal_emp;
pay_by_quarter
----------------
13000
23000
(2 rows)
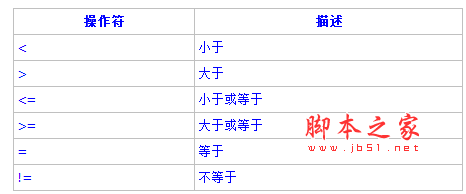
MyTest=# SELECT name FROM sal_emp WHERE pay_by_quarter[1] <> pay_by_quarter[2];
name
------
Bill
Carol
(2 rows)
PostgreSQL中還提供了訪問數組范圍的功能,即ARRAY[腳標下界:腳標上界]。
復制代碼 代碼如下:
MyTest=# SELECT name,pay_by_quarter[1:3] FROM sal_emp;
name | pay_by_quarter
--------+---------------------
Bill | {11000,12000,13000}
Carol | {21000,22000,23000}
(2 rows)
3. 修改數組:
1). 代替全部數組值:
復制代碼 代碼如下:
--UPDATE sal_emp SET pay_by_quarter = ARRAY[25000,25000,27000,27000] WHERE name = 'Carol'; 也可以。
MyTest=# UPDATE sal_emp SET pay_by_quarter = '{31000,32000,33000,34000}' WHERE name = 'Carol';
UPDATE 1
MyTest=# SELECT * FROM sal_emp;
name | pay_by_quarter
--------+---------------------------
Bill | {11000,12000,13000,14000}
Carol | {31000,32000,33000,34000}
(2 rows)
2). 更新數組中某一元素:
復制代碼 代碼如下:
MyTest=# UPDATE sal_emp SET pay_by_quarter[4] = 15000 WHERE name = 'Bill';
UPDATE 1
MyTest=# SELECT * FROM sal_emp;
name | pay_by_quarter
--------+---------------------------
Carol | {31000,32000,33000,34000}
Bill | {11000,12000,13000,15000}
(2 rows)
3). 更新數組某一范圍的元素:
復制代碼 代碼如下:
MyTest=# UPDATE sal_emp SET pay_by_quarter[1:2] = '{37000,37000}' WHERE name = 'Carol';
UPDATE 1
MyTest=# SELECT * FROM sal_emp;
name | pay_by_quarter
--------+---------------------------
Bill | {11000,12000,13000,15000}
Carol | {37000,37000,33000,34000}
(2 rows)
4). 直接賦值擴大數組:
復制代碼 代碼如下:
MyTest=# UPDATE sal_emp SET pay_by_quarter[5] = 45000 WHERE name = 'Bill';
UPDATE 1
MyTest=# SELECT * FROM sal_emp;
name | pay_by_quarter
--------+---------------------------------
Carol | {37000,37000,33000,34000}
Bill | {11000,12000,13000,15000,45000}
(2 rows)
4. 在數組中檢索:
1). 最簡單直接的方法:
復制代碼 代碼如下:
SELECT * FROM sal_emp WHERE pay_by_quarter[1] = 10000 OR
pay_by_quarter[2] = 10000 OR
pay_by_quarter[3] = 10000 OR
pay_by_quarter[4] = 10000;
2). 更加有效的方法:
復制代碼 代碼如下:
SELECT * FROM sal_emp WHERE 10000 = ANY (pay_by_quarter); --數組元素中有任何一個等於10000,where條件將成立。
SELECT * FROM sal_emp WHERE 10000 = ALL (pay_by_quarter); --只有當數組中所有的元素都等於10000時,where條件才成立。
七、復合類型:
PostgreSQL中復合類型有些類似於C語言中的結構體,也可以被視為Oracle中的記錄類型,但是還是感覺復合類型這個命名比較貼切。它實際上只是一個字段名和它們的數據類型的列表。PostgreSQL允許像簡單數據類型那樣使用復合類型。比如,表字段可以聲明為一個復合類型。
1. 聲明復合類型:
下面是兩個簡單的聲明示例:
復制代碼 代碼如下:
CREATE TYPE complex AS (
r double,
i double
);
CREATE TYPE inventory_item AS (
name text,
supplier_id integer,
price numeric
);
和聲明一個數據表相比,聲明類型時需要加AS關鍵字,同時在聲明TYPE時不能定義任何約束。下面我們看一下如何在表中指定復合類型的字段,如:
復制代碼 代碼如下:
CREATE TABLE on_hand (
item inventory_item,
count integer
);
最後需要指出的是,在創建表的時候,PostgreSQL也會自動創建一個與該表對應的復合類型,名字與表字相同,即表示該表的復合類型。
2. 復合類型值輸入:
我們可以使用文本常量的方式表示復合類型值,即在圓括號裡包圍字段值並且用逗號分隔它們。你也可以將任何字段值用雙引號括起,如果值本身包含逗號或者圓括號,那麼就用雙引號括起,對於上面的inventory_item復合類型的輸入如下:
復制代碼 代碼如下:
'("fuzzy dice",42,1.99)'
如果希望類型中的某個字段為NULL,只需在其對應的位置不予輸入即可,如下面的輸入中price字段的值為NULL,
復制代碼 代碼如下:
'("fuzzy dice",42,)'
如果只是需要一個空字串,而非NULL,寫一對雙引號,如:
復制代碼 代碼如下:
'("",42,)'
在更多的場合中PostgreSQL推薦使用ROW表達式來構建復合類型值,使用該種方式相對簡單,無需考慮更多標識字符問題,如:
復制代碼 代碼如下:
ROW('fuzzy dice', 42, 1.99)
ROW('', 42, NULL)
注:對於ROW表達式,如果裡面的字段數量超過1個,那麼關鍵字ROW就可以省略,因此以上形式可以簡化為:
復制代碼 代碼如下:
('fuzzy dice', 42, 1.99)
('', 42, NULL)
3. 訪問復合類型:
訪問復合類型中的字段和訪問數據表中的字段在形式上極為相似,只是為了對二者加以區分,PostgreSQL設定在訪問復合類型中的字段時,類型部分需要用圓括號括起,以避免混淆,如:
復制代碼 代碼如下:
SELECT (item).name FROM on_hand WHERE (item).price > 9.99;
如果在查詢中也需要用到表名,那麼表名和類型名都需要被圓括號括起,如:
復制代碼 代碼如下:
SELECT (on_hand.item).name FROM on_hand WHERE (on_hand.item).price > 9.99;
4. 修改復合類型:
見如下幾個示例:
復制代碼 代碼如下:
--直接插入復合類型的數據,這裡是通過ROW表達式來完成的。
INSERT INTO on_hand(item) VALUES(ROW("fuzzy dice",42,1.99));
--在更新操作中,也是可以通過ROW表達式來完成。
UPDATE on_hand SET item = ROW("fuzzy dice",42,1.99) WHERE count = 0;
--在更新復合類型中的一個字段時,我們不能在SET後面出現的字段名周圍加圓括號,
--但是在等號右邊的表達式裡引用同一個字段時卻需要圓括號。
UPDATE on_hand SET item.price = (item).price + 1 WHERE count = 0;
--可以在插入中,直接插入復合類型中字段。
INSERT INTO on_hand (item.supplier_id, item.price) VALUES(100, 2.2);
該篇博客是對PostgreSQL官方文檔中“數據類型”章節的簡單歸納,這裡之所以用一篇獨立的博客來專門介紹,不僅是為了系統學習,也便於今後需要時的快速查閱。