一、請求應答協議和RTT:
Redis是一種典型的基於C/S模型的TCP服務器。在客戶端與服務器的通訊過程中,通常都是客戶端率先發起請求,服務器在接收到請求後執行相應的任務,最後再將獲取的數據或處理結果以應答的方式發送給客戶端。在此過程中,客戶端都會以阻塞的方式等待服務器返回的結果。見如下命令序列:
復制代碼 代碼如下:
Client: INCR X
Server: 1
Client: INCR X
Server: 2
Client: INCR X
Server: 3
Client: INCR X
Server: 4
在每一對請求與應答的過程中,我們都不得不承受網絡傳輸所帶來的額外開銷。我們通常將這種開銷稱為RTT(Round Trip Time)。現在我們假設每一次請求與應答的RTT為250毫秒,而我們的服務器可以在一秒內處理100k的數據,可結果則是我們的服務器每秒至多處理4條請求。要想解決這一性能問題,我們該如何進行優化呢?
二、管線(pipelining):
Redis在很早的版本中就已經提供了對命令管線的支持。在給出具體解釋之前,我們先將上面的同步應答方式的例子改造為基於命令管線的異步應答方式,這樣可以讓大家有一個更好的感性認識。
復制代碼 代碼如下:
Client: INCR X
Client: INCR X
Client: INCR X
Client: INCR X
Server: 1
Server: 2
Server: 3
Server: 4
從以上示例可以看出,客戶端在發送命令之後,不用立刻等待來自服務器的應答,而是可以繼續發送後面的命令。在命令發送完畢後,再一次性的讀取之前所有命令的應答。這樣便節省了同步方式中RTT的開銷。
最後需要說明的是,如果Redis服務器發現客戶端的請求是基於管線的,那麼服務器端在接受到請求並處理之後,會將每條命令的應答數據存入隊列,之後再發送到客戶端。
三、Benchmark:
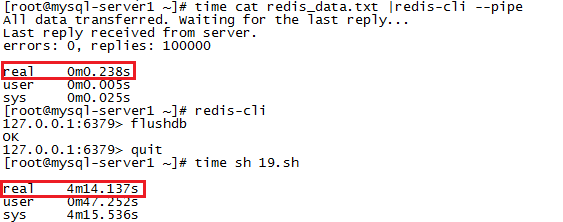
以下是來自Redis官網的測試用例和測試結果。需要說明的是,該測試是基於loopback(127.0.0.1)的,因此RTT所占用的時間相對較少,如果是基於實際網絡接口,那麼管線機制所帶來的性能提升就更為顯著了。
復制代碼 代碼如下:
require 'rubygems'
require 'redis'
def bench(descr)
start = Time.now
yield
puts "#{descr} #{Time.now-start} seconds"
end
def without_pipelining
r = Redis.new
10000.times {
r.ping
}
end
def with_pipelining
r = Redis.new
r.pipelined {
10000.times {
r.ping
}
}
end
bench("without pipelining") {
without_pipelining
}
bench("with pipelining") {
with_pipelining
}
//without pipelining 1.185238 seconds
//with pipelining 0.250783 seconds