前言
Redis集群搭建的目的其實也就是集群搭建的目的,所有的集群主要都是為了解決一個問題,橫向擴展。
在集群的概念出現之前,我們使用的硬件資源都是縱向擴展的,但是縱向擴展很快就會達到一個極限,單台機器的Cpu的處理速度,內存大小,硬盤大小沒辦法一直滿足需求,而且機器縱向擴展的成本是相當高的。集群的出現就是能夠讓多台機器像一台機器一樣工作,實現了資源的橫向擴展。
Redis是內存型數據庫,當我們要存儲的數據達到一定程度時,單台機器的內存滿足不了我們的需求,搭建集群則是一種很好的解決方案。
介紹安裝環境與版本
用兩台虛擬機模擬6個節點,一台機器3個節點,創建出3 master、3 salve 環境。
redis 采用 redis-3.2.4 版本。
兩台虛擬機都是 CentOS ,一台 CentOS6.5 (IP:192.168.31.245),一台 CentOS7(IP:192.168.31.210) 。
安裝過程
1. 下載並解壓
cd /root/software wget http://download.redis.io/releases/redis-3.2.4.tar.gz tar -zxvf redis-3.2.4.tar.gz
2. 編譯安裝
cd redis-3.2.4 make && make install
3. 將 redis-trib.rb 復制到 /usr/local/bin 目錄下
cd src cp redis-trib.rb /usr/local/bin/
4. 創建 Redis 節點
首先在 192.168.31.245 機器上 /root/software/redis-3.2.4 目錄下創建 redis_cluster 目錄;
mkdir redis_cluster
在 redis_cluster 目錄下,創建名為7000、7001、7002的目錄,並將 redis.conf 拷貝到這三個目錄中
mkdir 7000 7001 7002<br>cp redis.conf redis_cluster/7000 cp redis.conf redis_cluster/7001 cp redis.conf redis_cluster/7002
分別修改這三個配置文件,修改如下內容
port 7000 //端口7000,7002,7003 bind 本機ip //默認ip為127.0.0.1 需要改為其他節點機器可訪問的ip 否則創建集群時無法訪問對應的端口,無法創建集群 daemonize yes //redis後台運行 pidfile /var/run/redis_7000.pid //pidfile文件對應7000,7001,7002 cluster-enabled yes //開啟集群 把注釋#去掉 cluster-config-file nodes_7000.conf //集群的配置 配置文件首次啟動自動生成 7000,7001,7002 cluster-node-timeout 15000 //請求超時 默認15秒,可自行設置 appendonly yes //aof日志開啟 有需要就開啟,它會每次寫操作都記錄一條日志
接著在另外一台機器上(192.168.31.210),的操作重復以上三步,只是把目錄改為7003、7004、7005,對應的配置文件也按照這個規則修改即可
5. 啟動各個節點
第一台機器上執行 redis-server redis_cluster/7000/redis.conf redis-server redis_cluster/7001/redis.conf redis-server redis_cluster/7002/redis.conf 另外一台機器上執行 redis-server redis_cluster/7003/redis.conf redis-server redis_cluster/7004/redis.conf redis-server redis_cluster/7005/redis.conf
6. 檢查 redis 啟動情況
##一台機器<br>ps -ef | grep redis root 61020 1 0 02:14 ? 00:00:01 redis-server 127.0.0.1:7000 [cluster] root 61024 1 0 02:14 ? 00:00:01 redis-server 127.0.0.1:7001 [cluster] root 61029 1 0 02:14 ? 00:00:01 redis-server 127.0.0.1:7002 [cluster] netstat -tnlp | grep redis tcp 0 0 127.0.0.1:17000 0.0.0.0:* LISTEN 61020/redis-server tcp 0 0 127.0.0.1:17001 0.0.0.0:* LISTEN 61024/redis-server tcp 0 0 127.0.0.1:17002 0.0.0.0:* LISTEN 61029/redis-server tcp 0 0 127.0.0.1:7000 0.0.0.0:* LISTEN 61020/redis-server tcp 0 0 127.0.0.1:7001 0.0.0.0:* LISTEN 61024/redis-server tcp 0 0 127.0.0.1:7002 0.0.0.0:* LISTEN 61029/redis-server 1 2 3 4 5 6 7 8 9 10 11 12 13 ##另外一台機器 ps -ef | grep redis root 9957 1 0 02:32 ? 00:00:01 redis-server 127.0.0.1:7003 [cluster] root 9964 1 0 02:32 ? 00:00:01 redis-server 127.0.0.1:7004 [cluster] root 9971 1 0 02:32 ? 00:00:01 redis-server 127.0.0.1:7005 [cluster] root 10065 4744 0 02:38 pts/0 00:00:00 grep --color=auto redis netstat -tlnp | grep redis tcp 0 0 127.0.0.1:17003 0.0.0.0:* LISTEN 9957/redis-server 1 tcp 0 0 127.0.0.1:17004 0.0.0.0:* LISTEN 9964/redis-server 1 tcp 0 0 127.0.0.1:17005 0.0.0.0:* LISTEN 9971/redis-server 1 tcp 0 0 127.0.0.1:7003 0.0.0.0:* LISTEN 9957/redis-server 1 tcp 0 0 127.0.0.1:7004 0.0.0.0:* LISTEN 9964/redis-server 1 tcp 0 0 127.0.0.1:7005 0.0.0.0:* LISTEN 9971/redis-server 1
7.創建集群
Redis 官方提供了 redis-trib.rb 這個工具,就在解壓目錄的 src 目錄中,第三步中已將它復制到 /usr/local/bin 目錄中,可以直接在命令行中使用了。使用下面這個命令即可完成安裝。
redis-trib.rb create --replicas 1 192.168.31.245:7000 192.168.31.245:7001 192.168.31.245:7002 192.168.31.210:7003 192.168.31.210:7004 192.168.31.210:7005
其中,前三個 ip:port 為第一台機器的節點,剩下三個為第二台機器。
等等,出錯了。這個工具是用 ruby 實現的,所以需要安裝 ruby。安裝命令如下:
yum -y install ruby ruby-devel rubygems rpm-build gem install redis
之後再運行 redis-trib.rb 命令,會出現如下提示:
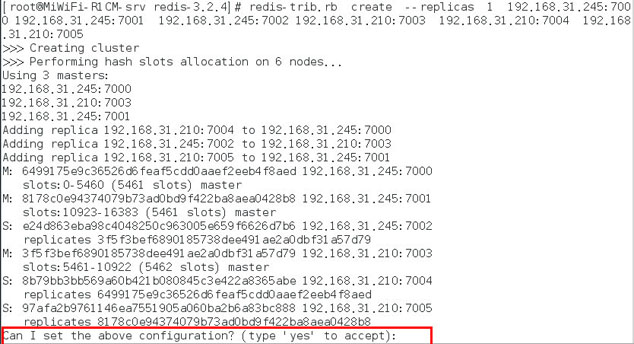
輸入 yes 即可,然後出現如下內容,說明安裝成功。
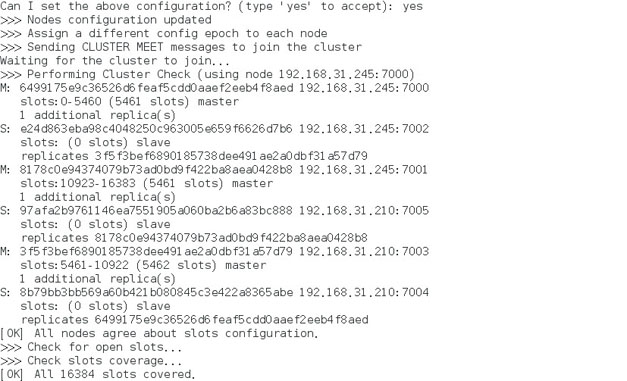
8. 集群驗證
在第一台機器上連接集群的7002端口的節點,在另外一台連接7005節點,連接方式為 redis-cli -h 192.168.31.245 -c -p 7002 ,加參數 -C 可連接到集群,因為上面 redis.conf 將 bind 改為了ip地址,所以 -h 參數不可以省略。
在7005節點執行命令 set hello world ,執行結果如下:

然後在另外一台7002端口,查看 key 為 hello 的內容, get hello ,執行結果如下:

說明集群運作正常。
簡單說一下原理
redis cluster在設計的時候,就考慮到了去中心化,去中間件,也就是說,集群中的每個節點都是平等的關系,都是對等的,每個節點都保存各自的數據和整個集群的狀態。每個節點都和其他所有節點連接,而且這些連接保持活躍,這樣就保證了我們只需要連接集群中的任意一個節點,就可以獲取到其他節點的數據。
Redis 集群沒有並使用傳統的一致性哈希來分配數據,而是采用另外一種叫做哈希槽 (hash slot)的方式來分配的。redis cluster 默認分配了 16384 個slot,當我們set一個key 時,會用CRC16算法來取模得到所屬的slot,然後將這個key 分到哈希槽區間的節點上,具體算法就是:CRC16(key) % 16384。所以我們在測試的時候看到set 和 get 的時候,直接跳轉到了7000端口的節點。
Redis 集群會把數據存在一個 master 節點,然後在這個 master 和其對應的salve 之間進行數據同步。當讀取數據時,也根據一致性哈希算法到對應的 master 節點獲取數據。只有當一個master 掛掉之後,才會啟動一個對應的 salve 節點,充當 master 。
需要注意的是:必須要3個或以上的主節點,否則在創建集群時會失敗,並且當存活的主節點數小於總節點數的一半時,整個集群就無法提供服務了。
總結
以上就是這篇文章的全部內容了,希望本文的內容對大家的學習或者工作能帶來一定的幫助,如果有疑問大家可以留言交流。