前言
眾所周知代理 ip 因為配置簡單而且廉價,經常用來作為反反爬蟲的手段,但是穩定性一直是其诟病。篩選出優質的代理 ip 並不簡單,即使付費購買的代理 ip 源,賣家也不敢保證 100% 可用;另外代理 ip 的生命周期也無法預知,可能上一秒能用,下一秒就撲街了。基於這些原因,會給使用代理 ip 的爬蟲程序帶來很多不穩定的因素。要排除代理 ip 的影響,通常的做法是建一個代理 ip 池,每次請求前來池子取一個 ip,用完之後歸還,保證池子裡的 ip 都是可用的。本文接下來就探討一下,如何使用 Redis 構建代理 ip 池,實現自動更新,自動擇優。
整體流程

由上圖所示,左側是形成了整個流程的閉環,從爬蟲程序以獨占的方式拿到一個代理 ip 到爬取完成歸還 ip。這個流程其實是不太嚴謹的,如果爬蟲程序異常中斷,就會導致 ip 無法歸還,就會導致這個 ip 無法循環利用。但是由於代理 ip 本身的特點,量多而且循環利用的價值並不大,所以這種情況就let it go。
上面也提到 ip 是以獨占的方式獲取,如果是去爬兩個毫不相關的網站,本來一個 ip 就可以,可現在需要兩個。為了資源最大化使用,這裡引入了頻道 ip 池和總代理 ip 池。兩個網站就當做兩個頻道,各自獨占,互不相關;總池子就是保存所有的 ip,每個頻道都共享。假設只有一個 ip:1.1.1.1 在總池子,爬 A 網站會把它從總池子取到 A 頻道的 ip 池,然後 A 爬蟲程序從 A 頻道 ip 池取出 1.1.1.1 進行使用,這時 1.1.1.1 依然在總池子裡,但 A 頻道的 ip 池已經不包含 1.1.1.1 了;爬 B 網站也是一樣的流程拿到 1.1.1.1,只是從 B 自己的頻道池獲取。下面就詳細說說總池子和頻道池子。
總代理 ip 池
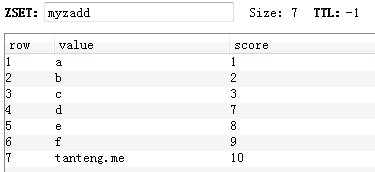
總池子的作用就是共享所有可用的 ip,但是僅作為存儲 ip 的池子並不能實現自動擇優啊,這裡的擇優通常是希望延遲低速度快的 ip 更容易被篩選出,所以我們希望池子中的 ip 是根據它們的延時升序排列,借助 Redis 的 Sorted Sets 數據結構即可實現,用延時表示 score,ip 表示 member。
使用 ZADD 添加新 ip 或更新 ip 的延遲:
> ZADD proxy_global_ips 200 1.1.1.1:8080 100 2.2.2.2:80 300 3.3.3.3:8888 (integer) 3
使用 ZRANGE 獲取 ip,可以指定獲取的個數,比如取兩個:
> ZRANGE proxy_global_ips 0 1 WITHSCORES 1) "2.2.2.2:80" 2) "100" 3) "1.1.1.1:8080" 4) "200"
頻道 ip 池
頻道 ip 池的作用是為了最大化使用總池子中的 ip,並且隔離其他頻道的 ip 池。由於一個 ip 使用次數過多是有很大的概率被目標網站屏蔽掉,所以這裡也需要進行擇優,應該優先篩選出使用次數少的 ip,同理也是使用 Sorted Sets,使用次數表示 score,ip 表示 member,這裡與總池子明顯的不同之處是 key 不是固定的,需要把頻道名稱組合進去,這樣保證頻道之間的隔離,如頻道 abc 的 key:proxy_channel_abc_ips。
由於頻道池子中的 ip 是要以獨占的方式取出,我們需要一個 ZPOP 的方法,奈何 Redis 本身沒有,還好可以通過 Lua 模擬,在一個原子操作下取出 ip,然後刪除:
> eval "local el = redis.call('zrange', KEYS[1], 0, 0, 'WITHSCORES'); redis.call('zrem', KEYS[1], el[1]); return el;" 1 proxy_channel_abc_ips
往頻道 ip 池添加 ip:
> ZADD proxy_channel_abc_ips INCR 0 1.1.1.1:8080
這裡與總池子不同的是多了一個 INCR 選項,這是 Redis 3.0.2 版本後才支持的新特性,即指定在 ZADD 時發生 member 沖突采取的處理方式,INCR 顧名思義是沖突後累加 score 的方式,為什麼要用這個選項,看看下面這個流程:
ZADD proxy_channel_abc_ips 0 1.1.1.1;取出 1.1.1.1ZADD proxy_channel_abc_ips 11 1.1.1.1ZADD proxy_channel_abc_ips 1 1.1.1.1第 5 步結束後,ip 1.1.1.1 的計數被錯誤地重置為 1,而不是我們預期的 12。使用 INCR 選項就可以避免這個尴尬,其實這也只能保證最終計數正確,中途還是會有些非預期的情況,如:
ZADD proxy_channel_abc_ips 0 1.1.1.1;取出 1.1.1.1ZADD proxy_channel_abc_ips INCR 1 1.1.1.1ZADD proxy_channel_abc_ips INCR 3 2.2.2.2如果要避免這個問題,一個簡單粗暴的辦法就是增加頻道池子的容量,讓 ip 數永遠大於並發的線程數。
更新
與 ip 有關的兩個屬性:延時(爬取頁面所花的時間)和使用次數。上面只講到了根據它們自動擇優,這裡的就來說下它們是如何更新的。延時和使用次數的更新需要爬蟲程序的配合,程序中要記錄時間和遞增使用次數,在歸還 ip 時要將最新值帶回給總池子和頻道池子。上面頻道 ip 池的例子也有提及,每次歸還 ip 都要將最新的使用次數帶上,其次還要將 ip 的延時更新到總池子裡面。如果歸還 ip 時出現使用失敗的情況,就要將該 ip 從總池子裡刪除掉,保證該 ip 不會再被使用,至於當前的頻道池不用歸還就行了。其他頻道池不作任何處理,因為 ip 在當前頻道不可用,一般都是因為被屏蔽,其他頻道依然可以使用,即使確實都不能使用,也會在其他頻道歸還 ip 時被刪除。
這兩個屬性其實也可以都在 Redis 中更新,在獲取 ip 時,使用 Hashs 保存 ip 對應的獲取時間和使用次數;在歸還時從 Hashs 中取出時間計算出延時,取出使用次數並加 1,再分別更新到總池子和頻道池子中。而且這還能避免上面提到的獲取 ip 不符合預期的問題。
總結
放在 Redis 中更新的方法也有弊端,延時會包含獲取和歸還的傳輸時間,如果爬蟲程序獲取一個 ip 多次使用,會造成使用次數統計偏少。當然也可以通過在程序中多次調用 Redis 更新 ip 的屬性來解決,這樣增加了整個流程的復雜性,需要自己權衡。
個人還是傾向在程序中記錄,最後更新到 Redis 中。這個方案邏輯確實不夠嚴謹,但是出現問題也不會導致嚴重後果。程序的健壯性也不是不允許出現 bug,而是出現 bug 有很好的容錯性。
以上就是這篇文章的全部內容了,希望本文的內容對大家的學習或者工作能帶來一定的幫助,如果有疑問大家可以留言交流。