SQL Server的執行計劃詳細的反映了一個SQL語句具體做了哪些操作。我們可以通過分析一條特定語句的執行計劃,來判斷此SQL語句的執行效率如何,性能開銷怎樣。分析SQL語句的執行計劃,對於SQL Server的性能調優具有指導意義。本文列舉了三類常見的SQL操作,並對其生成的執行計劃進行了簡析。
先建立一張表。
CREATE TABLE Person(
Id int IDENTITY(1,1) NOT NULL,
Name nvarchar(50) NULL,
Age int NULL,
Height int NULL,
Area nvarchar(50) NULL,
MarryHistory nvarchar(10) NULL,
EducationalBackground nvarchar(10) NULL,
Address nvarchar(50) NULL,
InSiteId int NULL
) ON [PRIMARY]
表中的數據14萬左右,大概類似下面這樣:
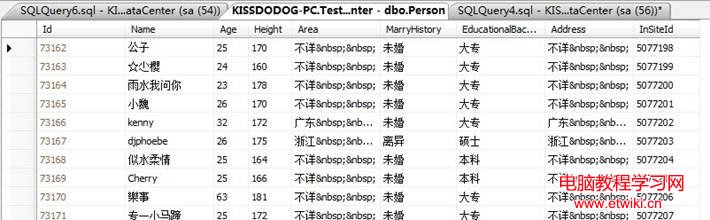
此表,暫時沒有任何索引。
【正文】
一、數據訪問操作
1、表掃描
表掃描:發生於堆表,並且沒有可用的索引可用時,會發生表掃描,表示整個表掃描一次。
現在,我們來對此表執行一條簡單的查詢語句:
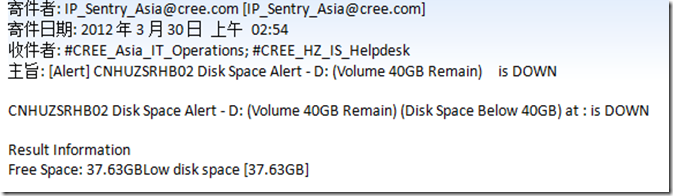
SELECT * From Person WHERE Name = '公子'
查看執行計劃如下:
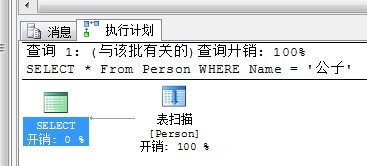
表掃描,顧名思義就是整張表掃描,找到你所需要的數據了。
2、聚集索引掃描
聚集索引掃描:發生於聚集表,也相當於全表掃描操作,但在針對聚集列的條件如(WHERE Id > 10)等操作時,效率會較好。
下面我們在Id列來對此表加上一個聚集索引
CREATE CLUSTERED INDEX IX_Id ON Person(Id)
再次執行同樣的查詢語句:
SELECT * From Person WHERE Name = '公子'
執行計劃如下:
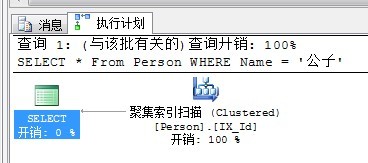
為什麼建的聚集索引在Id列,會對掃描有影響呢?更何況與Name條件也沒關系啊?
其實,你加了聚集索引之後,表就由堆表變成了聚集表。我們知道聚集表的數據存在於聚集索引的葉級節點。因此,聚集掃描與表掃描其實差別不大,要說差別大,也得看where條件裡是什麼,以後返回的數據。就本條SQL語句而言,效率差別並不大。
可以看看I/O統計信息:
表掃描:
聚集索引掃描:

3、聚集索引查找
聚集索引查找:查找聚集索引中特定范圍的行。
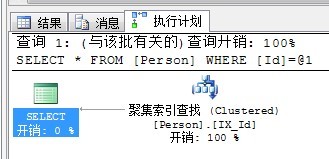
看執行以下SQL語句:
SELECT * FROM Person WHERE Id = '73164'
執行計劃如下:
4、索引掃描
索引掃描:整體掃描非聚集索引。
下面我們來添加一個聚集索引,並執行一條查詢語句:
CREATE NONCLUSTERED INDEX IX_Name ON Person(Name) --創建非聚集索引
SELECT Name FROM Person
查看執行計劃如下:
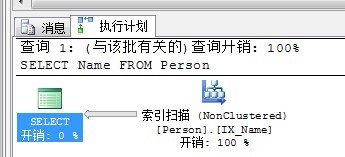
為什麼此處會選擇索引掃描(非聚集索引)呢?
因為此非聚集索引能夠覆蓋所需要的數據。如果非聚集索引不能覆蓋呢?例如,我們將SELECT改為SELECT *再來看看。
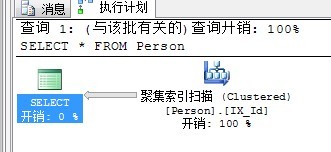
此時,非聚集索引並不能夠覆蓋查詢所需的所有數據,並且沒有篩選條件可供使用,所以本次查詢所需的數據只能通過掃描整張表的方式拿到。在這裡,掃描整張表即為聚集索引掃描,這是由於本張表是聚集索引表。
下面,我們刪除此表上的聚集索引,再運行上述命令。
DROP INDEX Person.IX_Id
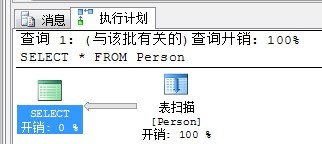
此時沒有聚集索引,所以只有使用表掃描。
5、書簽查找
當一個查詢所需返回的列,不能在非聚集索引中完全覆蓋,而搜索條件中又包含了非聚集索引列時,SQL Server會選擇,先去非聚集索引找到聚集索引鍵(或者記錄的RID),然後利用聚集索引(或者RID)找到數據。
下面來看一個書簽查找的示例:
SELECT * FROM Person WHERE Name = '胖胖' --Name列有非聚集索引
執行計劃如下:
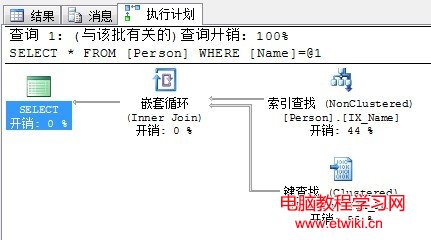
上面的過程可以理解為:首先通過非聚集索引找到所求的行,但這個索引並不包含所有的列,因此還要額外去基本表中找到這些列,因此要進行鍵查找,如果基本表是以堆進行組織的,那麼這個鍵查找(Key Lookup)就會變成RID查找(RID Lookup),鍵查找和RID查找統稱為書簽查找。不過有時當非聚集索引返回的行數過多時,SQL Server可能會選擇直接進行聚集索引掃描了。