微軟的SQL Server的存儲過程機制能夠通過對Transact-SQL語句進行組合而大大地簡化了數據庫開發過程。
存儲過程功能的優點
為什麼要使用存儲過程?以下是存儲過程技術的幾大主要優點:
結構
存儲過程的結構跟其他編程語言非常相似。存儲過程接受輸入參數形式的數據。這些輸入參數在執行系列語句的時候被運用並生成結果。結果在通過使用記錄集、輸出參數和返回代碼返回。聽起來似乎很復雜,實際上存儲程序非常簡單。
實例
假設我們有如下名為Inventory的表格,表格裡的數據需要實時更新,倉庫經理會不停地檢查倉庫裡的貨存數量和可供發貨的貨存數量。以前,每一個地區的倉庫經理都會進行如下查詢:
SELECT Product, Quantity
FROM Inventory
WHERE Warehouse = 'FL'
這樣的查詢使SQL Server性能效率非常低下。每次倉庫經理執行該查詢,數據庫服務器都不得不重新對其進行編譯然後重新開始執行。這樣的查詢還要求倉庫經理具備SQL方面的知識,並且擁有訪問表格數據的權限。
我們可以通過使用存儲過程來簡化這個查詢過程。首先創建一個名為 sp_GetInventory的過程,能夠獲取一個已有倉庫的貨存水平。下面是創建該程序的SQL代碼:
CREATE PROCEDURE sp_GetInventory
@location varchar(10)
AS
SELECT Product, Quantity
FROM Inventory
WHERE Warehouse = @location
A地區的倉庫經理可以執行下面的命令來獲得貨存水平:
EXECUTE sp_GetInventory 'FL'
B地區的倉庫經理可以使用同樣的存儲過程來訪問該地區的貨存信息。
EXECUTE sp_GetInventory 'NY'
當然,這只是一個很簡單的例子,但是可以看出來存儲過程的好處。倉庫經理不一定要懂得SQL或者存儲過程內在的工作原理。從性能的角度看的話,存儲過程無疑大大地提高了工作的效率。SQL Server只需創建執行計劃一次,然後就可以重復使用存儲過程,只需要在每次執行時輸入適當的參數就可以了。
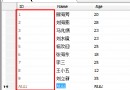
貨存表格:
ID
Product
Warehouse
Quantity
142
Green beans
NY
100
214
Peas
FL
200
825
Corn
NY
140
512
Lima beans
NY
180
491
Tomatoes
FL
80
379
Watermelon
FL
85