本文主要介紹使用SQL Server 2005數據庫管理工具生成大量數據方法。此方法主要適用於擁有自增長標識的表;若標識不為自增長,則需要首先修改該表標識屬性為自增長。
1. 數據准備
在目標表中准備10條左右的真實數據,若果沒有10條數據,那麼選一條或若干條數據,按Ctrl+C,然後Ctrl+V復制粘貼即可。

通過復制->粘貼將數據增加到1000條。
2.數據導出
當數據准備工作完成後,我們就以進行數據的導出了
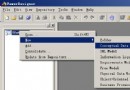
2.1打開導出界面
如下圖所示:右鍵點擊數據庫名->任務->導出數據

2.2選擇導出數據庫和數據源
如圖所示,在“SQL Server導入和導出”界面,選擇

2.3選擇導入和導出目標
此界面與上一界面一樣,填寫方法也一樣,如圖所示:

2.4指定表或查詢
選擇“復制一個或多個表或視圖的數據”,點擊下一步

2.5選擇源表或源視圖
如圖所示:


2.6完成導出數據,一路點擊“下一步”“完成”即可

這樣我們就完成了一次將數據向中轉表導出的操作(導出100W條數據需要3分鐘左右),那麼如何實現原表數據的增加呢?很簡單,就是將中轉表的數據再倒回到源表中。
3.數據導入
數據導入與數據導出的過程一樣,唯一的卻別就是在於編輯“列映射”界面
這裡的源表是中轉表“c_HumRecord_test”,目標表是原表“c_HumRecord”

這裡就不能再啟用標識插入了,因為目標表的ID列(主鍵)是,自增長的;並且
在下方的列表中將列ID的目標列該成“忽略”,這樣才可以成功完成向原表c_HumRecord的數據的導入

4.總結
如此一來我們就完成了一次數據庫表的生成了,看到這裡有同學會質疑數據這樣生成的速度。其實如果我們重復以上步驟,會發現表數據是以倍數增加的,不用半小時,我們就可將表數據增加到千萬了。
對比之前使用過的DataFactroy生成百萬的數據就需要20-30分鐘(根據表結構復雜程度而定,且每個字段的生成規則都要設定),此方法還是非常快捷簡單實用的。