SQLSERVER的表值函數是SQLSERVER 2005以來的新特性,由於它使用比較方便,就像一個單獨的表一樣,在我們的系統中大量使用。有一個獲取客戶數據的SQLSERVER 表值函數,如果使用管理員登錄,這個函數會返回150W行記錄,大概需要30秒左右,但如果將TOP語句放到表值函數外,效率異常低下,需要約3分鐘:
- select top 20 * from GetFrame_CustomerSerch('admin','1')
下面是該存儲過程的定義:
- ALTER FUNCTION [dbo].[GetFrame_CustomerSerch]
- (
- -- Add the parameters for the function here
- @WorkNo varchar(38)
- ,@SerchChar varchar(500)
- )
- RETURNS TABLE
- AS
- RETURN
- (
- -- Add the SELECT statement with parameter references here
- select a.GUID,a.CustomerName,a.CustomerIDcard,a.CustomerPhone,a.CustomerMobile from
- (
- --具體子查詢略
- )
- ) a union all
- select b.GUID,b.CustomerName,b.CustomerIDcard,b.CustomerPhone,
- b.CustomerMobile from WFT_ManagerCollectUsers a left join WFT_Customer b on
- a.FundAccount=b.FundAccount
- --where a.WorkNo=@WorkNo
- WHERE a.WorkNo IN
- (
- --具體子查詢略
- )
- )
這個語句放在PDF.NET數據開發框架的SQL-MAP文件中,開始還以為是框架引起的,將這個語句直接在查詢分析器中查詢,仍然很慢。
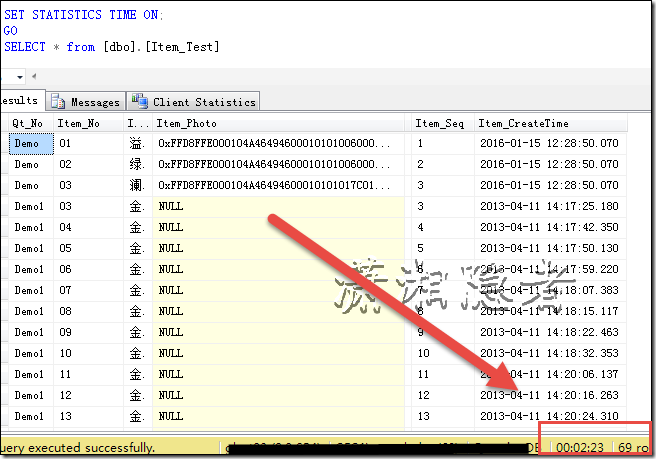
將GetFrame_CustomerSerch 中的SQL語句提取出來,直接加上Top查詢,只需要6秒,快了N倍:
- declare @WorkNo varchar(38)
- declare @SerchChar varchar(500)
- set @WorkNo='admin'
- set @SerchChar='1'
- select top 20 a.GUID,a.CustomerName,a.CustomerIDcard,a.CustomerPhone,
- a.CustomerMobile from
- (
- --具體子查詢略
- )
- ) a union all
- select b.GUID,b.CustomerName,b.CustomerIDcard,b.CustomerPhone,b.CustomerMobile
- from WFT_ManagerCollectUsers
- a left join WFT_Customer b on a.FundAccount=b.FundAccount
- WHERE a.WorkNo IN
- (
- --具體子查詢略
- )
為什麼會有這麼大的差異?
我分析可能有如下原因:
1,在表值函數外使用Top或者其它條件,SQLSERVER 的查詢優化器無法針對此查詢進行優化,比如先返回所有記錄,然後再在臨時表中選取前面的20條記錄;
2,雖說該表值函數使用了“表變量”,它是內存中的,但如果這個“表”結果很大,很有可能內存放不下(並非還有物理內存就會將結果放到物理內存中,數據庫自己還會有保留的,會給其它查詢預留一定的內存空間),使用虛擬內存,而虛擬內存實際上就是磁盤頁面文件,當記錄太多就會發生頻繁的頁面交換,從而導致這個查詢效率非常低。
看來,“表值函數”也不是傳說中的那麼好,不知道大家是怎麼認為的。
最近還遇到一個怪異的問題,有一個存儲過程,老是在系統運行1-2天後變得極其緩慢,但重新修改一下又很快了(只是加一個空格之類),不知道大家遇到過沒有,什麼原因?