盡管從技術上講,其它排名函數的計算與ROW_NUMBER類似,但它們的的實際應用卻少很多。RANK和DENSE——RANK主要用於排名和積分。NTILE更多地用於分析。
先創建一個示例表:
代碼如下:
SET NOCOUNT ON
USE [tempdb]
IF OBJECT_ID('Sales')IS NOT NULL
DROP TABLE sales
CREATE TABLE Sales
(
empid VARCHAR(10) NOT NULL PRIMARY KEY,
mgrid VARCHAR(10) NOT NULL,
qty INT NOT NULL
)
INSERT INTO [Sales] (empid,[mgrid],[qty])VALUES('A','Z',300)
INSERT INTO [Sales] (empid,[mgrid],[qty])VALUES('B','X',100)
INSERT INTO [Sales] (empid,[mgrid],[qty])VALUES('C','X',200)
INSERT INTO [Sales] (empid,[mgrid],[qty])VALUES('D','Y',200)
INSERT INTO [Sales] (empid,[mgrid],[qty])VALUES('E','Z',250)
INSERT INTO [Sales] (empid,[mgrid],[qty])VALUES('F','Z',300)
INSERT INTO [Sales] (empid,[mgrid],[qty])VALUES('G','X',100)
INSERT INTO [Sales] (empid,[mgrid],[qty])VALUES('H','Y',150)
INSERT INTO [Sales] (empid,[mgrid],[qty])VALUES('I','X',250)
INSERT INTO [Sales] (empid,[mgrid],[qty])VALUES('J','Z',100)
INSERT INTO [Sales] (empid,[mgrid],[qty])VALUES('K','Y',200)
CREATE INDEX idx_qty_empid ON [Sales](qty,empid)
CREATE INDEX idx_mgrid_qty_empid ON sales(mgrid,qty,empid)
--
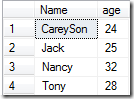
SELECT * FROM [Sales]
代碼如下:
--排名函數
/**/
--Sql Server 2005排名函數只能用於查詢的SELECT 和 ORDER BY 子句中。排名計算(無論你使用什麼方法)的最佳索引是在分區列、排序列、覆蓋列上創建的索引。
--行號:是指按指定順序為查詢結果集中的行分配的連續整數。在後面的節中,將描述Sql Server 2005與之前版本中計算行號的工具與方法。
SELECT empid,qty,ROW_NUMBER()OVER(ORDER BY qty)AS RowNum
FROM [Sales]
ORDER BY [qty]
--確定性
SELECT empid,qty,ROW_NUMBER()OVER(ORDER BY qty)AS RowNum,ROW_NUMBER()OVER(ORDER BY qty,empid)AS RowNum2
FROM [Sales]
ORDER BY qty,empid
--分區
SELECT mgrid,empid,qty,ROW_NUMBER()OVER(PARTITION BY mgrid ORDER BY qty,empid)AS RowNum
FROM [Sales]
ORDER BY mgrid,qty
--=====之前2000版本基於集合的方法實現
--唯一排序列:給定一個唯一的分區 + 排序列組合 (如下例的唯一的分區是empid,排序列empid
SELECT empid,(SELECT COUNT(*) FROM [Sales] AS s2 WHERE s2.empid<=s1.empid)AS rowNum
FROM [Sales] s1 ORDER BY [empid]
--查看執行計劃,(順序是從上至下,從右至左看)會發現有兩個不同的運算符使用了聚集索引。第一個是完整掃描以返回所有的行(這個例子是11行);第二個運算符先為每個外部執行查找,再執行局部掃描,以完成統計。還記得嗎?影響數據處理查詢性能的主要因素通常中I/O。這種方式在小數據量時不明顯,但當數據量較大時(大於千條),由於每一條記錄都需要將全部表掃描一次,使用這種方法掃描的總行數將是1+2+3+N,對於整體上100000行的表,你一共會掃描50005000行。順便提一下,計算前N個正整數之各的公式是(N+N的平方)/2。
--看示例即了解到的.
USE [AdventureWorks]
SET STATISTICS TIME ON
SELECT salesorderid,ROW_NUMBER()OVER(ORDER BY salesorderid)AS rownum
FROM sales.[SalesOrderHeader]
SELECT salesorderid,(SELECT COUNT(*) FROM sales.[SalesOrderHeader] b WHERE b.salesorderid<=a.salesorderid)AS rownum
FROM sales.[SalesOrderHeader] a
ORDER BY [salesorderid]
/* 結果:
(31465 行受影響)
SQL Server 執行