從SQL SERVER 2005開始,數據庫不默認生成NDF數據文件,一般情況下有一個主數據文件(MDF)就夠了,但是有些大型的數據庫,由於信息很多,而且查詢頻繁,所以為了提高查詢速度,可以把一些表或者一些表中的部分記錄分開存儲在不同的數據文件裡
由於CPU和內存的速度遠大於硬盤的讀寫速度,所以可以把不同的數據文件放在不同的物理硬盤裡,這樣執行查詢的時候,就可以讓多個硬盤同時進行查詢,以充分利用CPU和內存的性能,提高查詢速度。 在這裡詳細介紹一下其寫入的原理,數據文件(MDF、NDF)和日志文件(LDF)的寫入方式是不一樣的:
數據文件:SQL Server按照同一個文件組裡面的所有文件現有空閒空間的大小,按這個比例把新的數據分布到所有有空間的數據文件裡,如果有三個數據文件A.MDF,B.NDF,C.NDF,空閒大小分別為200mb,100mb,和50mb,那麼寫入一個70mb的東西,他就會向ABC三個文件中一次寫入40、20、10的數據,如果某個日志文件已滿,就不會向其寫入
日志文件:日志文件是按照順序寫入的,一個寫滿,才會寫入另外一個
由上可見,如果能增加其數據文件NDF,有利於大數據量的查詢速度,但是增加日志文件卻沒什麼用處。
在SQL Server 2005中,默認MDF文件初始大小為5MB,自增為1MB,不限增長,LDF初始為1MB,增長為10%,限制文件增長到一定的數目,一般設計中,使用SQL自帶的設計即可,但是大型數據庫設計中,最好親自去設計其增長和初始大小,如果初始值太小,那麼很快數據庫就會寫滿,如果寫滿,在進行插入會是什麼情況呢?當數據文件寫滿,進行某些操作時,SQL Server會讓操作等待,直到文件自動增長結束了,原先的那個操作才能繼續進行。如果自增長用了很長時間,原先的操作會等不及就超時取消了(一般默認的阈值是15秒),不但這個操作會回滾,文件自動增長也會被取消。也就是說,這一次文件沒有得到任何增大,增長的時間根據自動增長的大小確定的,如果太小,可能一次操作需要連續幾次增長才能滿足,如果太大,就需要等待很長時間,所以設置自動增長要注意一下幾點:
1)要設置成按固定大小增長,而不能按比例。這樣就能避免一次增長太多或者太少所帶來的不必要的麻煩。建議對比較小的數據庫,設置一次增長50 MB到100 MB。對大的數據庫,設置一次增長100 MB到200 MB。
2)要定期監測各個數據文件的使用情況,盡量保證每個文件剩余的空間一樣大,或者是期望的比例。
3)設置文件最大值,以免SQL Server文件自增長用盡磁盤空間,影響操作系統。
4)發生自增長後,要及時檢查新的數據文件空間分配情況。避免SQL Server總是往個別文件寫數據。
因此,對於一個比較繁忙的數據庫,推薦的設置是開啟數據庫自動增長選項,以防數據庫空間用盡導致應用程序失敗,但是要嚴格避免自動增長的發生。同時,盡量不要使用自動收縮功能。
數據文件和日志文件的操作會產生大量的I/O。在可能的條件下,日志文件應該存放在一個與數據和索引所在的數據文件不同的硬盤上以分散I/O,同時還有利於數據庫的災難恢復。
為什麼要表分區?
當一個表的數據量太大的時候,我們最想做的一件事是什麼?將這個表一分為二或者更多分,但是表還是這個表,只是將其內容存儲分開,這樣讀取就快了N倍了
原理:表數據是無法放在文件中的,但是文件組可以放在文件中,表可以放在文件組中,這樣就間接實現了表數據存放在不同的文件中。能分區存儲的還有:表、索引和大型對象數據 。
SQL SERVER 2005中,引入了表分區的概念, 當表中的數據量不斷增大,查詢數據的速度就會變慢,應用程序的性能就會下降,這時就應該考慮對表進行分區,當一個表裡的數據很多時,可以將其分拆到多個的表裡,因為要掃描的數據變得更少 ,查詢可以更快地運行,這樣操作大大提高了性能,表進行分區後,邏輯上表仍然是一張完整的表,只是將表中的數據在物理上存放到多個表空間(物理文件上),這樣查詢數據時,不至於每次都掃描整張表
1、表的大小超過2GB。
2、表中包含歷史數據,新的數據被增加到新的分區中。
表分區有以下優點:
1、改善查詢性能:對分區對象的查詢可以僅搜索自己關心的分區,提高檢索速度。
2、增強可用性:如果表的某個分區出現故障,表在其他分區的數據仍然可用;
3、維護方便:如果表的某個分區出現故障,需要修復數據,只修復該分區即可;
4、均衡I/O:可以把不同的分區映射到磁盤以平衡I/O,改善整個系統性能。
缺點:
分區表相關:已經存在的表沒有方法可以直接轉化為分區表。不過 Oracle 提供了在線重定義表的功能.
2.31 創建分區函數
CREATE PARTITION FUNCTION xx1(int)
AS RANGE LEFT FOR VALUES (10000, 20000);
注釋:創建分區函數:myRangePF2,以INT類型分區,分三個區間,10000以內在A 區,1W-2W在B區,2W以上在C區.
2.3.2創建分區架構
CREATE PARTITION SCHEME myRangePS2
AS PARTITION xx1
TO (a, b, c);
注釋:在分區函數XX1上創建分區架構:myRangePS2,分別為A,B,C三個區間
A,B,C分別為三個文件組的名稱,而且必須三個NDF隸屬於這三個組,文件所屬文件組一旦創建就不能修改
2.3.3 對表進行分區
常用數據規范--數據空間類型修改為:分區方案,然後選擇分區方案名稱和分區列列表,結果如圖所示:
也可以用sql語句生成
CREATE TABLE [dbo].[AvCache](
[AVNote] [varchar](300) NULL,
[bb] [int] IDENTITY(1,1)
) ON [myRangePS2](bb); --注意這裡使用[myRangePS2]架構,根據bb分區
2.3.4查詢表分區
SELECT *, $PARTITION.[myRangePF2](bb) FROM dbo.AVCache
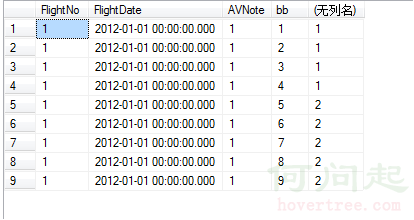
這樣就可以清楚的看到表數據是如何分區的了
2.3.5創建索引分區
分布式數據庫系統是在集中式數據庫系統的基礎上發展起來的,理解起來也很簡單,就是將整體的數據庫分開,分布到各個地方,就其本質而言,分布式數據庫系統分為兩種:1.數據在邏輯上是統一的,而在物理上卻是分散的,一個分布式數據庫在邏輯上是一個統一的整體,在物理上則是分別存儲在不同的物理節點上,我們通常說的分布式數據庫都是這種2.邏輯是分布的,物理上也是分布的,這種也成聯邦式分布數據庫,由於組成聯邦的各個子數據庫系統是相對“自治”的,這種系統可以容納多種不同用途的、差異較大的數據庫,比較適宜於大范圍內數據庫的集成。
分布式數據庫較為復雜,在此不作詳細的使用和說明,只是舉例說明一下,現在分布式數據庫多用於用戶分區性較強的系統中,如果一個全國連鎖店,一般設計為每個分店都有自己的銷售和庫存等信息,總部則需要有員工,供應商,分店信息等數據庫,這類型的分店數據庫可以完全一致,很多系統也可能導致不一致,這樣,各個連鎖店數據存儲在本地,從而提高了影響速度,降低了通信費用,而且數據分布在不同場地,且存有多個副本,即使個別場地發生故障,不致引起整個系統的癱瘓。 但是他也帶來很多問題,如:數據一致性問題、數據遠程傳遞的實現、通信開銷的降低等,這使得分布式數據庫系統的開發變得較為復雜,只是讓大家明白其原理,具體的使用方式就不做詳細的介紹了。
如果你的表已經創建好了索引,但性能卻仍然不好,那很可能是產生了索引碎片,你需要進行索引碎片整理。
什麼是索引碎片?
由於表上有過度地插入、修改和刪除操作,索引頁被分成多塊就形成了索引碎片,如果索引碎片嚴重,那掃描索引的時間就會變長,甚至導致索引不可用,因此數據檢索操作就慢下來了。
如何知道是否發生了索引碎片?
在SQLServer數據庫,通過DBCC ShowContig或DBCC ShowContig(表名)檢查索引碎片情況,指導我們對其進行定時重建整理。
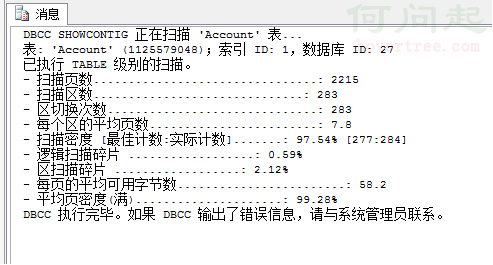
通過對掃描密度(過低),掃描碎片(過高)的結果分析,判定是否需要索引重建,主要看如下兩個:
Scan Density [Best Count:Actual Count]-掃描密度[最佳值:實際值]:DBCC SHOWCONTIG返回最有用的一個百分比。這是擴展盤區的最佳值和實際值的比率。該百分比應該盡可能靠近100%。低了則說明有外部碎片。
Logical Scan Fragmentation-邏輯掃描碎片:無序頁的百分比。該百分比應該在0%到10%之間,高了則說明有外部碎片。
解決方式:
一是利用DBCC INDEXDEFRAG整理索引碎片
二是利用DBCC DBREINDEX重建索引。
兩者區別調用微軟的原話如下:
DBCC INDEXDEFRAG 命令是聯機操作,所以索引只有在該命令正在運行時才可用,而且可以在不丟失已完成工作的情況下中斷該操作。這種方法的缺點是在重新組織數據方面沒有聚集索引的除去/重新創建操作有效。
重新創建聚集索引將對數據進行重新組織,其結果是使數據頁填滿。填滿程度可以使用 FILLFACTOR 選項進行配置。這種方法的缺點是索引在除去/重新創建周期內為脫機狀態,並且操作屬原子級。如果中斷索引創建,則不會重新創建該索引。也就是說,要想獲得好的效果,還是得用重建索引,所以決定重建索引。