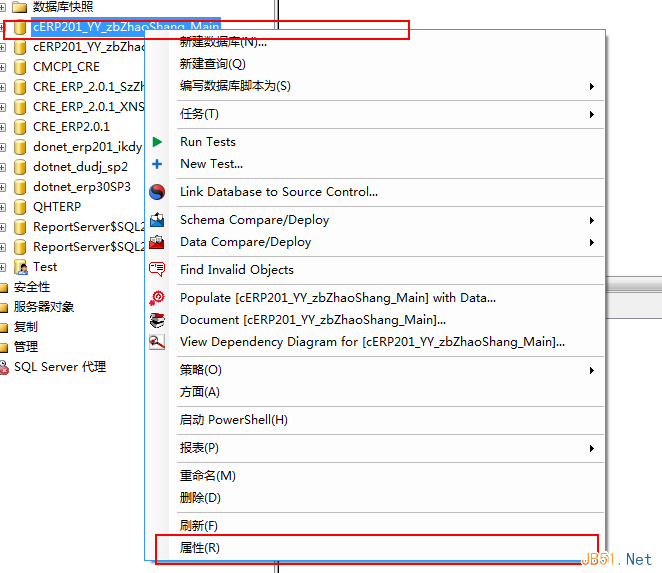
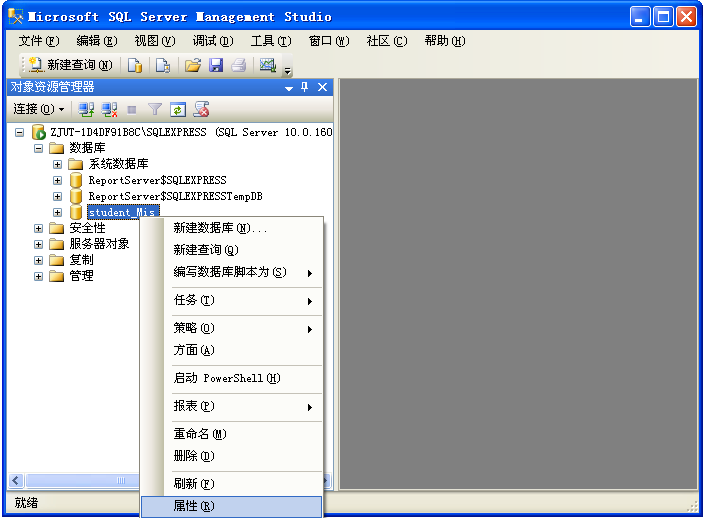
---啟用sa賬號
1. 先使用一個windows賬號登陸。
2.在數據庫實例上面右鍵,屬性,安全性,登錄名,sa.
右鍵,屬性。
常規,修改sa的密碼。
狀態,啟用sa賬號。
主鍵的作用:
1.唯一標識表中的一條記錄。
選擇什麼樣的列作為主鍵:
1.沒有重復的列。
2.不能為空(null)的列。
3.選擇比較穩定的列。(列不經常發生變化的),主鍵中的值一般不修改。
4.選擇那些比較“小”的列。(列的數據類型所占用的字節數小)。
5.盡量選擇那些沒有實際意義的列作為主鍵(邏輯主鍵
不建議選擇那些在業務中具有實際意義的列作為主鍵(具有實際意義的列作為主鍵,叫做,業務主鍵。)
6.盡量選擇單列作為主鍵,不要選擇多列作為主鍵(組合主鍵、復合主鍵)[一個主鍵是由多列組成的]
一個表中可以有多個主鍵嗎?不可以,因為表中數據的實際存儲順序只能有一種。
主鍵不是必須的,但是建議每張表都應該有主鍵。
數據類型介紹
image 用來存儲二進制字節。byte[] 可以存儲圖片,文件,電影等。什麼類型都可以存儲。只要能轉換為byte[]就可以使用image數據類型存儲
---下面的這幾種數據類型都是表示字符串類型---
char/nchar/varchar/nvarchar/varchar(max)/nvarchar(max)/text/ntext
char()/nchar()
char(5) 最大可以寫char(8000)
五個字符 //不帶n的,存儲的時候是用ascii模式來存儲,中文字符占用兩個字節,英文字符、數字字符等占用一個字節
nchar(5) 最大可以寫nchar(4000)
//凡是帶n的都表示在存儲的時候使用unicode方式來存儲,那麼無論是中文還是英文都是每個字符占用2個字節
---數據前面不加var,表示這個數據類型是一個固定長度的數據類型。
如果設置了長度為10,那麼
1>最多能存儲10個。多了則報錯
2>如果只存儲了3個,那麼後面也會自動補齊7個空格。
---如果加了var,那麼表示的是可變長度。
---比如varchar(10)
1>最多能存儲10個,多了則報錯
2>如果存儲的少於10個,則實際存儲的長度就是,實際用戶輸入的字符串的個數,不會自動補齊。
varchar()/nvarchar()
帶var的優點:節省空間。缺點:每次都會動態計算用戶實際保存的數據的長度,重新設置數據類型長度。
text 等價於varchar(max)
ntext等價於nvrcahr(max)
SQL Server一共有5個系統數據庫:
master:記錄SQL Server系統的所有系統級信息,例如:登陸賬戶信息、鏈接服務器和系統配置設置、記錄其他所有數據庫的存在、數據文件的位置、SQL Server的初始化信息等。
如果master數據庫不可用,則無法啟動SQL Server。
msdb:用於SQL Server代理計劃警報和作業。數據庫定時執行某些操作、數據庫郵件等。
model:用作SQL Server實例上創建的所有數據庫的模板。對model 數據庫進行的修改(如數據庫大小、排序規則、恢復模式和其他數據庫選項)將應用於以後創建的所有數據庫。在model數據庫中創建一張表,則以後每次創建數據庫的時候都會有默認的一張同樣的表。
tempdb:一個工作空間,用於保存臨時對象或中間結果集。一個全局資源,可供連接到 SQL Server 實例的所有用戶使用。每次啟動 SQL Server 時都會重新創建 tempdb。
SQL語句入門:
SQL全名結構化查詢語言(Structured Query Language),是關系數據庫管理系統的標准語言
Sybase與Microsoft對標准SQL做了擴展,稱為:T-SQL(Transact-SQL)
SQL主要分為DDL(數據庫定義語言)、DML(數據操作語言) 、DCL(數據庫控制語言)
truncate table student 的作用與delete from student一樣,都是刪除student表中的全部數據,區別在於:
1.truncate語句非常高效。由於truncate操作采用按最小方式來記錄日志,所以效率非常高。對於數百萬條數據使用truncate刪除只要幾秒鐘,而使用delete則可能耗費幾小時。
2.truncate語句會把表中的自動編號重置為默認值。
3.truncate語句不觸發delete觸發器。
約束-保證數據完整性
非空約束
主鍵約束(PK) primary key constraint 唯一且不為空
唯一約束(UQ) unique constraint 唯一,允許為空,但只能出現一次
默認約束(DF) default constraint 默認值
檢查約束(CK) check constraint 范圍以及格式限制
外鍵約束(FK) foreign key constraint 表關系(在外鍵表中建立外鍵約束)
增加外鍵約束時,設置【級聯更新、級聯刪除】:來保證,當主鍵表中的記錄發生改變時候,對應的外鍵表中的數據也發生相應的改變。
[ ON DELETE { NO ACTION | CASCADE | SET NULL | SET DEFAULT } ]
[ ON UPDATE { NO ACTION | CASCADE | SET NULL | SET DEFAULT } ]
top和distinct
top獲取查詢出的結果集中的前n條
order by 進行排序。所以,一般使用top的時候,必須配合排序一起使用才有意義。
--row_number() (MSSQL Server2005之後新增) 數據庫取底4條到第8條的數據

select * from (select row_number() over (order by cid asc) as num,* from CheckTest) as s where s.num between 4 and 8 select top 5 * from CheckTest where cid not in (select top 2 cid from CheckTest)分頁Demo/row_number
--Group by數據分組
--1.分組的目的,就是為了匯總、統計。
--2.聚合函數。剛才所說的聚合函數其實就是把整個表中的數據作為"一組",來進行統計匯總。
--聚合函數使用的時候一定會配合分組(group by)來使用,如果使用聚合函數時,沒用分組,那麼意義不大。
--聚合函數在使用的時候一定會分組,即便不寫group by語句,其實也是默認把整個表中的數據作為"一個組"來使用,進行統計。
select ---4
tsclassId,
count(*) as 班級人數
from TblStudent ---1
group by tsclassId ---2
having count(*)>10 ---3 --注意在having中不能使用select中所使用的別名,因為在執行having的時候,select的還沒執行呢。
--但是,在order by語句中卻可以使用select中為列起的別名,因為order by語句在最後執行,在執行order by語句的時候,select語句已經執行完畢了。
--having的意思就是對分組後的結果,再進行篩選,最終確定哪些組顯示,那些組不顯示
--where與having的區別
--1.where是在分組前進行數據篩選,having是在分組後數據篩選。
--2.不能在where中直接使用聚合函數來進行數據篩選,也不能在having中直接使用分組查詢後並不包含的列來進行數據篩選
SQL語句執行順序:
5>…Select 5-1>選擇列,5-2>distinct,5-3>top(應用top選項最後計算) 1>…From 表 2>…Where 條件 3>…Group by 列 4>…Having 篩選條件 6>…Order by 列 --------------------- 1.FROM 2.ON 3.JOIN 4.WHERE 5.GROUP BY 6.WITH CUBE 或 WITH ROLLUP 7.HAVING 8.SELECT 9.DISTINCT 10.ORDER BY 11.TOPMSSQL 執行順序
---類型轉換Cast()與Convert()
Cast(getdate(),varchar(16))
Convert(varchar(16),getdate())
---聯合union
--union指的是聯合的意思,是將多個結果集聯合成了一個結果集。把所有的記錄都加起來變成一個大的結果集。
--1:union ,使用union的時候會默認執行去除重復的操作。
--2:union all(推薦),使用union all的時候並不會執行任何去除重復操作,會將所有的記錄都聯合顯示出來。
--3;進行結果集聯合的時候,可以對多個結果集進行聯合,但是前提是:
--- 1>多個結果集中,每個結果集的列的個數都得一致
--- 2>並且多個結果集之間的數據類型需要一一對應(數據類型一致,或者數據類型之間得兼容)
--- 通過一條SQL語句向表中插入多條數據[insert into 表名 + 結果集]
insert into 表名 select 列1值,列2值,... union all select 列1值,列2值,... union all select 列1值,列2值,...insert表[使用select SQL]
--- 把現有表的數據插入到新的表中(表不能存在),為表建立備份
select * into NewCheckTest from checktest
--- 創建一個新表,該表的結果與已經存在的表一致,但是該表中沒有任何數據
select * into MyNewCheckTest from checktest where 1<>1 (不推薦)
select top 0 * into MyNewCheckTest from checktest (推薦)
--- 如果表已經存在
insert into 表名 select * from 已經存在的表
--字符串函數
LEN():計算字符串長度(字符的個數)
datalength()://計算字符串所占用的字節數,不屬於字符串函數。
varchar變量與nvarchar變量存儲字符串a的區別 [varchar占用1個字節數(使用ascii方式),nvarchar占用2個字節數(使用unicode方式)]
LOWER() 、UPPER () :轉小寫、大寫
LTRIM():字符串左側的空格去掉
RTRIM():字符串右側的空格去掉
LTRIM(RTRIM(' bb ')):字符串兩邊的空格去掉
LEFT()、RIGHT():截取取字符串
SELECT LEFT('abcdefg',2)
SUBSTRING(string,start_position,length),索引從1開始。
參數string為主字符串,start_position為子字符串在主字符串中的起始位置,length為子字符串的最大長度。SELECT SUBSTRING('abcdef111',2,3)
--日期函數
GETDATE() :取得當前日期時間
DATEADD (datepart , number, date ):計算增加以後的日期。參數date為待計算的日期;參數number為增量;參數datepart為計量單位,可選值見備注。
DATEADD(DAY, 3,date)為計算日期date的3天後的日期,而DATEADD(MONTH ,-8,date)為計算日期date的8個月之前的日期 。
Sql2005中只有DateTime類型,2008中有date、datetime、datetime2 等類型。
DATEDIFF ( datepart , startdate , enddate ):計算兩個日期之間的差額。 datepart 為計量單位,可取值參考DateAdd。
select DateDiff(year,sInDate,getdate()),count(*) from student Group by DateDiff(year,sInDate,getdate())統計不同入學年數的學生個數[DataDiff]
DATEPART (datepart,date):返回一個日期的特定部分 Month()、year()、day()來代替。
select DatePart(year,sBirthday),count(*) from student group by DatePart(year, sBirthday)統計學生的生日年份個數
--返回剛剛插入數據的Id
insert into 'TableName' output inserted.Id values('AA','BB') (推薦)
insert into 'TableName' values('laozhang',10);select @@identity (不推薦,同時插入數據時,只會返回最後一個的id)
--Case 等值判斷
CASE expression
WHEN value1 THEN returnvalue1
WHEN value2 THEN returnvalue2
WHEN value3 THEN returnvalue3
ELSE defaultreturnvalue
END
---Case 區間判斷
CASE
WHEN condition1 THEN returnvalue1
WHEN condition 2 THEN returnvalue2
WHEN condition 3 THEN returnvalue3
ELSE defaultreturnvalue
END
--索引
全表掃描:對數據進行檢索(select)效率最差的是全表掃描,就是一條條的找。
如果沒有目錄,查漢語字典就要一頁頁的翻,而有了目錄只要查詢目錄即可。為了提高檢索的速度,可以為經常進行檢索的列添加索引,相當於創建目錄。
創建索引的方式,在表設計器中點擊右鍵,選擇“索引/鍵”→添加→在列中選擇索引包含的列。
使用索引能提高查詢效率,但是索引也是占據空間的,而且添加、更新、刪除數據的時候也需要同步更新索引,因此會降低Insert、Update、Delete的速度。
只在經常檢索的字段上(Where)創建索引。【MSSQL 默認使用【填充因子】 來提高效率(在每條數據之間留有空間)】
(*)即使創建了索引,仍然有可能全表掃描,比如like、函數、類型轉換等。
select A1,A2 from A where A3 like '%abc%' --會全表掃描,不會使用索引
select A1,A2 from A where A3 like 'abc%' --會使用索引
--不清楚在哪列建立索引 可以使用MSSQL-->工具-->【數據庫引擎優化顧問】
索引
相當於字典中的目錄
加快查詢速度
在執行增刪改的時候降低了速度
聚集索引
一個表中只能有一個聚集索引。
【相當於字典中拼音目錄,拼音目錄的順序和數據的順序是一致的】
索引的排序順序與表中數據的物理存儲位置是一致的,一般新建主鍵列後回自動生成一個聚集索引。
非聚集索引(邏輯上的排序)
一個表中可以有多個非聚集索引。
【相當於字典中筆畫目錄,筆畫目錄的順序和數據是無關的】
// 建索引的目的是為了加快查詢速度。
// 索引之所以能加快查詢速度是【因為索引對數據進行了排序,排序後則可更高效的查詢】。
// 建索引應該建在某個列上(where中經常使用到的列),就是說要對某個列排序,
//這是,如果用用戶執行一條查詢語句,where條件中包含了建索引的那列,那麼這時,采用用到索引,否則,不會使用索引。Name=數據(用索引),name like ‘%aa%’(不用索引)
=======非聚集索引=============
CREATE NONCLUSTERED INDEX IX_SalesPerson_SalesQuota_SalesYTD ON Sales.SalesPerson (SalesQuota, SalesYTD); GO
====創建唯一非聚集索引=============
CREATE UNIQUE INDEX AK_UnitMeasure_Name ON Production.UnitMeasure(Name); GO
=======創建聚集索引=================
CREATE TABLE t1 (a int, b int, c AS a/b); CREATE UNIQUE CLUSTERED INDEX Idx1 ON t1(c); INSERT INTO t1 VALUES (1, 0);
=====刪除索引=====
drop index 表名.列名
--子查詢
把一個查詢的結果在另一個查詢中使用就叫子查詢。(將一個查詢語句做為一個結果集供其他SQL語句使用)
子查詢基本分類:
1. 獨立子查詢(連接子查詢):子查詢可以獨立運行
2. 相關子查詢:子查詢中引用了父查詢中的結果
--分頁(每頁顯示4條數據,顯示第三頁數據)
SELECT TOP 4 * FROM UserInfo WHERE Id NOT IN ( SELECT TOP (4 * 2) Id FROM UserInfo) ------------------------------------- SELECT * FROM (SELECT ROW_NUMBER() OVER (ORDER BY id ASC) AS num,* FROM UserInfo) AS U WHERE U.num BETWEEN (4 * 2)+ 1 AND (4 * 3)分頁Demo
--連接查詢(join)
交叉連接:(兩種語法cross join 和 ,)
內連接:(inner join),多表內連接。
無論幾張表連接,每次執行都是兩張表進行連接。
外連接:
左外聯(left outer join)
右外聯(right outer join)
連接查詢的基本執行步驟:
1>笛卡爾積(第一張表的所有數據和第二張表一一連接)
2>應用on篩選器
3>添加外部行,到此from執行完畢