列存儲索引其實在在SQL Server 2012中就已經存在,但SQL Server 2012中只允許建立非聚集列索引,這意味著列索引是在原有的行存儲索引之上的引用了底層的數據,因此會消耗更多的存儲空間,但2012中的限制最大的還是一旦將非聚集列存儲索引建立在某個表上時,該表將變為只讀,這使得即使在數據倉庫中使用列索引,每次更新數據都變成非常痛苦的事。SQL Server 2014中的可更新聚集列索引則解決了該問題。
聚集列存儲索引的概念可以類比於傳統的行存儲,聚集索引既是數據本身,列存儲的概念也是同樣。將數據按照列存儲而不是行存儲則提供了諸多好處,
首先對於大量聚合、掃描、分組等數據倉庫類查詢僅僅需要讀取選擇的列,對於需要Join多個表的星型結構等場景性能提升尤其明顯
其次是列索引可以更新,並且每個表中只需要一個(這是優點也是缺點,因為無法再建非聚集索引)聚集列索引即可,大大節省了空間
列索引由於是按列存儲,同一列中數據類型是一樣的,因此可以更加容易的實現更高的壓縮比率
列存儲的表會占用更少的存儲空間,因此存在更少的IO
行存儲對於OLTP操作十分適合,因為每個聚集索引鍵可以標識某一行,該行存儲在物理磁盤上也連續,因此可以利用Seek操作完成大量選擇性非常高的查詢,而列存儲索引同一行的每一列並不在物理上聯系,並且列存儲聚集索引中並沒有“主鍵”的概念,因此並不存在SEEK操作,如果大量OLTP類的查詢,性能將會出現問題。
列存儲索引只支持Scan操作,如圖1所示。
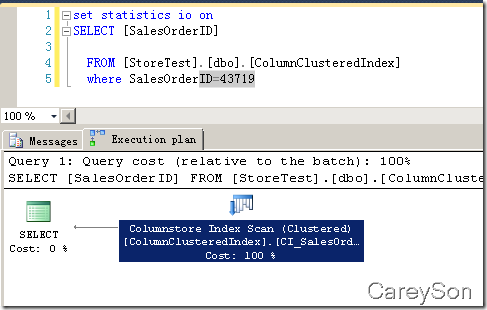
圖1.列存儲索引只支持Scan操作
列索引存儲可以望文生義,就是按列存儲。這個過程可以分為3個階段,首先將一堆行分組,這就是所謂的“行組”,分組完成後,再按列切分,最後將列壓縮,如圖2所示。

圖2.列存儲的過程