最近在給一個客戶做調優的時候發現一個很有意思的現象,對於一個復雜查詢(涉及12個表)建立必要的索引後,語句使用的IO急劇下降,但執行時間不降反升,由原來的8秒升到20秒。
通過觀察執行計劃,發現之前的執行計劃在很多大表連接的部分使用了Hash Join,由於涉及的表中數據眾多,因此查詢優化器選擇使用並行執行,速度較快。而我們優化完的執行計劃由於索引的存在,且表內數據非常大,過濾條件的值在一個很寬的統計信息步長范圍內,導致估計行數出現較大偏差(過濾條件實際為15000行,步長內估計的平均行數為800行左右),因此查詢優化器選擇了Loop Join,且沒有選擇並行執行,因此執行時間不降反升。
由於語句是在存儲過程中實現,因此我們直接對該語句使用一個undocument查詢提示,使得該查詢的並行開銷阈值強制降為0,使得該語句強制走並行,語句執行時間由20秒降為5秒(注:使用Hash Join提示是7秒)。
下面通過一個簡單的例子展示使用該提示的效果,示例T-SQL如代碼清單1所示:
SELECT * FROM [AdventureWorks].[Sales].[SalesOrderDetail] a INNER JOIN [Sales].SalesOrderHeader b ON a.SalesOrderID=b.SalesOrderID
代碼清單1.
該語句默認不會走並行,執行計劃如圖1所示:
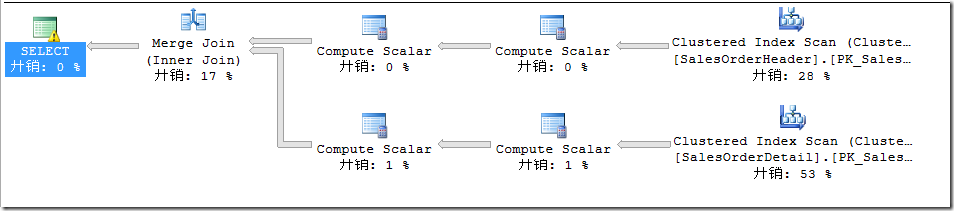
圖1.
下面我們對該語句加上提示,如代碼清單2所示。
SELECT * FROM [AdventureWorks].[Sales].[SalesOrderDetail] a INNER JOIN [Sales].SalesOrderHeader b ON a.SalesOrderID=b.SalesOrderID OPTION(querytraceon 8649)
代碼清單2.
此時執行計劃會按照提示走並行,如圖2所示:

圖2.
在面對一些復雜的DSS或OLAP查詢時遇到類似的情況,可以考慮使用該Undocument提示要求SQL Server盡可能的使用並行,從而降低執行時間。
From:cnblogs CareySon