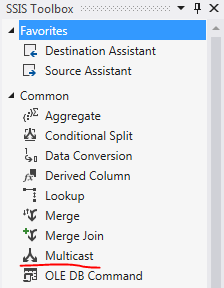
在 SSIS Data Flow 中有一個 Multicast 組件,它的作用和 Merge, Merge Join 或者 Union All 等合並數據流組件對比起來作用正好相反。非常直觀,它可以將一個數據流平行分開成為多個數據流供下游其它 Data Flow 組件使用。
第一種,從同一個數據源中取出一部分數據直接放到 A 表中,一部分數據直接放到 B 表中。我曾經遇到一個370多列的一個文件,這370列的文件可以分出列數不等的7,8 張表。我最開始的做法是先將這個文件的數據 Load 到一個大表中,然後再從大表抽取不同的列到小表中,這樣相當於形成了二次加載,效率不高,後來使用 Multicast 就可以一次性直接將 370 列寬的文件分散到不同的表中。
第二種,從數據源 A 抽取數據到 B,B 每次都會先 Truncate 一下,但是又需要備份一下每次從 A 抽取的數據,這個時候也可以使用 Multicast。在每次從 A 抽取數據的時候,通過 Multicast 使數據在導向 B 的同時也導向到 B 的備份表。
第三種,類似於第二種,不同的是沒有備份表,但是需要保留加載的一些 Audit 信息數據。比如,從 Source 抽取數據到 Staging 的時候,同時需要記錄一下抽取的行數,以及用來標示這批 Staging 數據中最大的時間戳,表名和列的名稱。這樣的話,下次加載數據到 Staging 的時候就只選擇加載新增的 Source 數據,也就是上一批最大時間戳之後的新數據。
當然,同一種問題可能有不同的解決的方式,歡迎大家補充!
下面的示例演示一下第一種和第三種情形。
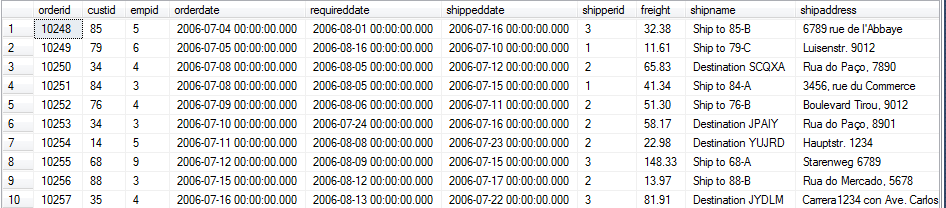
先從 TSQL2012 中抽取一部分測試的數據 (TSQL2012 是 Microsoft SQL Server 2012 High-Performance T-SQL Using Window Function 一書中的示例數據庫),我們的 Source 表就是 SalesOrderSource。
USE BIWORK_SSIS
GO
IF OBJECT_ID('dbo.SalesOrderSource','U') IS NOT NULL
DROP TABLE dbo.SalesOrderSource
GO
SELECT *
INTO dbo.SalesOrderSource
FROM TSQL2012.Sales.Orders
WHERE orderdate < '2006-08-01'
SELECT * FROM dbo.SalesOrderSource
創建兩個目標表,一個用來簡單存儲 Order 相關信息,一個用來簡單存儲 Ship 相關信息。
IF OBJECT_ID('dbo.SalesOrder','U') IS NOT NULL
DROP TABLE dbo.SalesOrder
IF OBJECT_ID('dbo.OrderShip','U') IS NOT NULL
DROP TABLE dbo.OrderShip
CREATE TABLE dbo.SalesOrder
(
OrderID INT,
CustID INT,
EmpID INT,
OrderDate DATETIME,
CreateDate DATETIME DEFAULT(GETDATE())
)
CREATE TABLE dbo.OrderShip
(
OrderID INT,
ShippedDate DATETIME,
Shipperid INT,
freight MONEY,
shipname NVARCHAR(40),
CreateDate DATETIME DEFAULT(GETDATE())
)
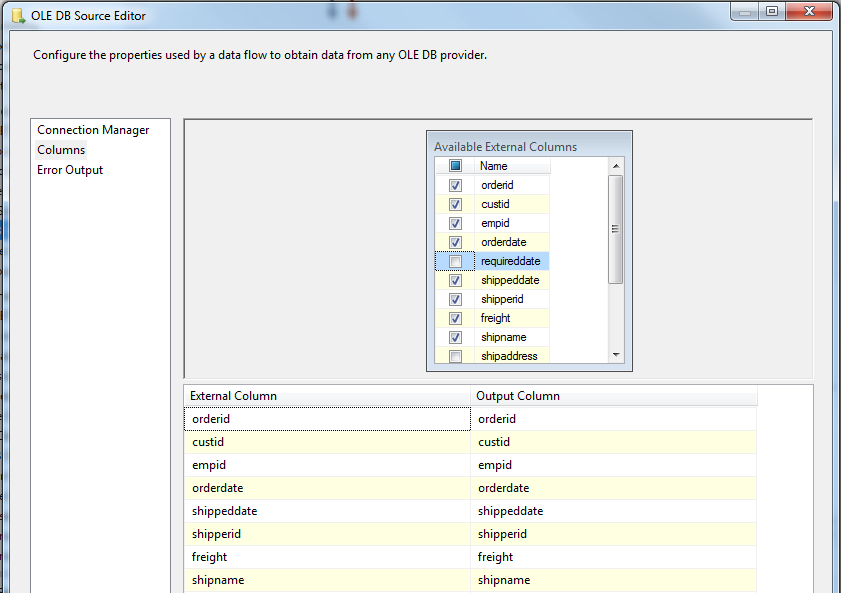
創建連接管理器的過程就不多說了,新建一個 Data Flow Task, 然後創建一個 OLE DB Source 指向 SalesOrderSource 這張數據源表。
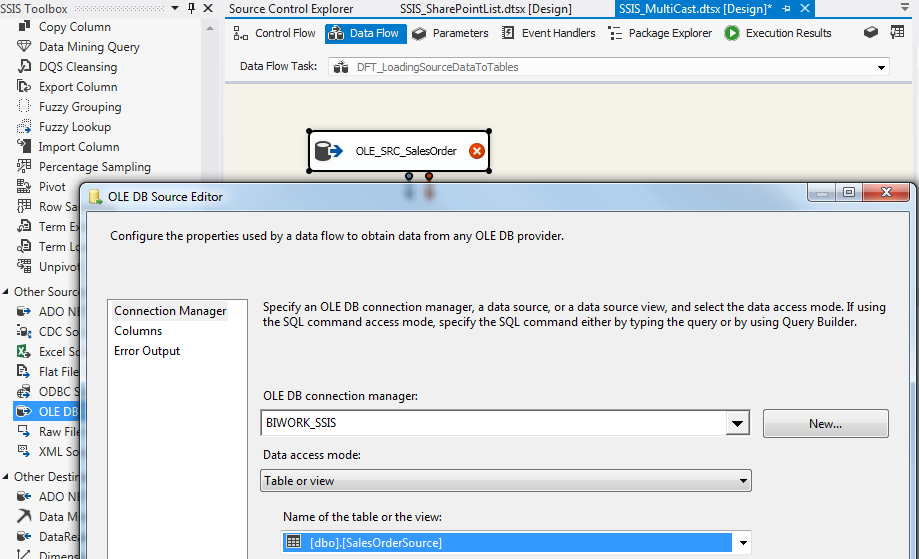
在 Columns 中選擇只需要向下輸出的列,減少不必要的數據傳輸。