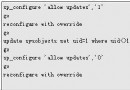
誤區 #11:鏡像在檢測到故障後瞬間就能故障轉移
錯誤
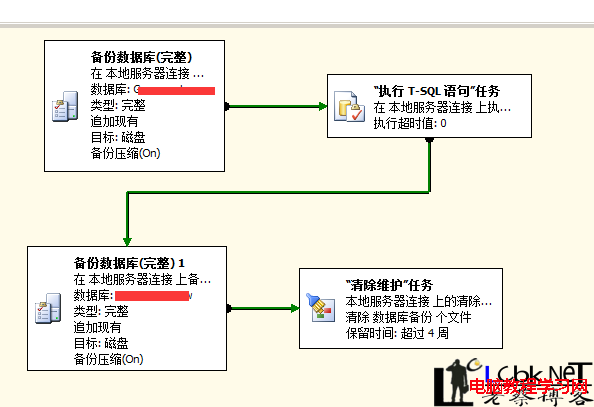
數據庫鏡像的故障轉移既可以自動發起,也可以手動發起。
在自動發起的情況下,是由鏡像服務器執行故障轉移操作(你沒有看錯,並不是由見證服務器來做故障轉移的決定),在見證服務器和鏡像服務器都發現無法和主體服務器交換信息(這個過程被稱為”形成仲裁”,譯者注:也就是通過程序對集群進行監管,集群可用的依據來自監管程序的算法,比如根據:每個節點的配置,文件共享情況,磁盤訪問情況,每個節點的可用性等來確定集群是否可用)並且鏡像方式是同步時,可以進行故障轉移。(譯者注:所謂的同步指的是主體服務器必須等待鏡像服務器的日志寫入後,才能夠提交事務。相對異步來說性能更差,但更安全,並且還不需要SQL Server是企業版)。
手動故障轉移是由你發起的,手動發起可能是由於不存在見證服務器(以至於無法“形成仲裁”),或是在主體服務器現在問題時鏡像的運行模式不是“同步”。
當主體服務器發生故障時,鏡像服務器在日志隊列Redo完成之前不會上線(所謂的日志隊列就是由主體服務器傳送到鏡像服務器的日志,但還沒有在鏡像服務器Replay)。即使你鏡像的運行模式是同步,也僅僅只能說明日志被寫入鏡像磁盤,但不能保證日志在鏡像服務器被重放。而對於故障轉移來說,鏡像服務器必須經歷Roll Forward階段才能夠上線.但Roll Back階段是鏡像上線後才會做的。
在SQL Server標准版以及企業版所在的CPU低於5個內核,Roll Forward只有一個線程。對於企業版並且CPU多余5核,為每4個核分配一個Roll Forward線程。所以完全可以看出故障轉移所需的時間取決於需要對日志進行Redo處理的隊列大小,CPU的核數,以及鏡像服務器的負載。
由於大家都認為鏡像工作在同步方式時可以迅速進行故障轉移,所以很少有人檢測日志Redo隊列。但由於Redo隊列的大小確定了故障轉移時Downtime的大小,所以檢測鏡像服務器Redo隊列變得十分重要。
有關這裡更細節的文章,你可以參看:Estimating the Interruption of Service During Role Switching