最近的4到5年以來,微軟首次嘗試重寫在1998年發布的SQL Server版本7所確立的查詢執行引擎。重寫的目標是在不犧牲關系型數據庫特色的前提下,提供類似於NoSQL的高速度。
這一次嘗試的核心是Hekaton項目,即內存優化表。雖然依然能夠通過傳統的T-SQL操作對其進行訪問,但其內部已經是基於完全不同的技術所實現。這一技術是有意與當今服務器硬件的三大趨勢保持一致的。
早期的SQL Server可以通過某些方式將表駐留在內存中,但這一特性後來被證明會造成對性能的損害,隨後就被廢棄了接近10年的時間。在當時來看,將整張表的內容駐留在容量有限的內存系統中是完全不合理的做法。而現如今,64位處理器已經得到了廣泛的應用,而且內存的價格也在不斷下降,選擇將龐大的數據庫保存在內存中就顯得更為合理了。
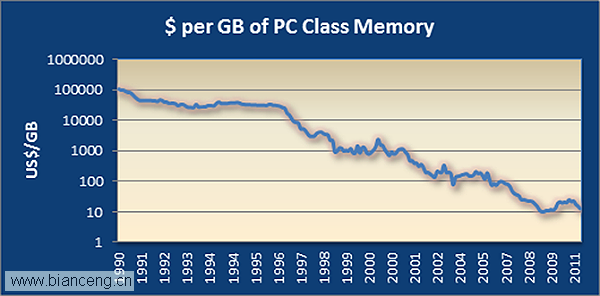
雖然CPU的復雜度還在保持上升,但近10年來,它的時鐘速度的增加幾乎已經停滯不前了。因此要看到線性性能的提升,除了利用緩存的能力之外,也要求所運行的代碼具有更高的效率。
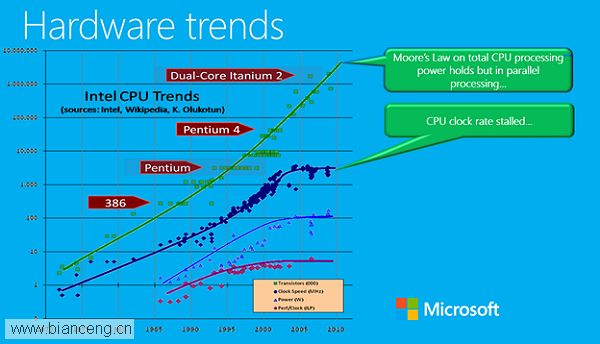
在這裡,T-SQL曾經的設計決策就能夠起到作用了。在目前的設計中,無論是即時的查詢或是基於存儲過程的查詢,都僅僅會被編譯為一種中間語言,並且之後會通過解釋的方式進行執行,而不是通過即時編譯的方式轉變為機器代碼。雖然這種方式能夠接受較高的復雜性,但也付出了降低性能的代價。
這一點在過去還是可以接受的,因為雖然數據加載量在增大,但CPU處理連續數據量的能力也在隨之上升。但這一點在如今已經不可行了,微軟已經決定要打造一個新的執行引擎,它的實現依賴於完全經過編譯的機器代碼。
正如我們在之前的一份報告中所指出的一樣,新的執行引擎僅支持存儲過程。你付出了放棄動態查詢的代碼,所得到的是經過高度優化的C代碼,這些代碼是為你所使用的表而專門生成的。