在SQL Server中,索引是一種增強式的存在,這意味著,即使沒有索引,SQL Server仍然可以實現應有的功能。但索引可以在大多數情況下大大提升查詢性能,在OLAP中尤其明顯.要完全理解索引的概念,需要了解大量原理性的知識,包括B樹,堆,數據庫頁,區,填充因子,碎片,文件組等等一系列相關知識,這些知識寫一本小書也不為過。所以本文並不會深入討論這些主題。
索引是對數據庫表中一列或多列的值進行排序的一種結構,使用索引可快速訪問數據庫表中的特定信息。
精簡來說,索引是一種結構.在SQL Server中,索引和表(這裡指的是加了聚集索引的表)的存儲結構是一樣的,都是B樹,B樹是一種用於查找的平衡多叉樹.理解B樹的概念如下圖:
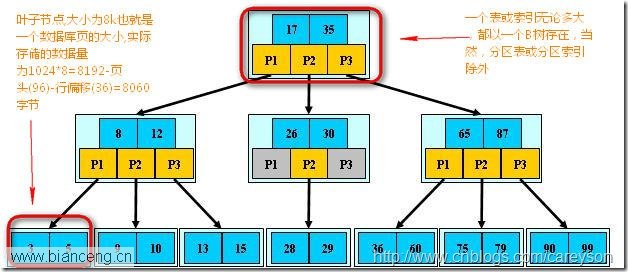
理解為什麼使用B樹作為索引和表(有聚集索引)的結構,首先需要理解SQL Server存儲數據的原理.
在SQL SERVER中,存儲的單位最小是頁(PAGE),頁是不可再分的。就像細胞是生物學中不可再分的,或是原子是化學中不可再分的最小單位一樣.這意味著,SQL SERVER對於頁的讀取,要麼整個讀取,要麼完全不讀取,沒有折中.
在數據庫檢索來說,對於磁盤IO掃描是最消耗時間的.因為磁盤掃描涉及很多物理特性,這些是相當消耗時間的。所以B樹設計的初衷是為了減少對於磁盤的掃描次數。如果一個表或索引沒有使用B樹(對於沒有聚集索引的表是使用堆heap存儲),那麼查找一個數據,需要在整個表包含的數據庫頁中全盤掃描。這無疑會大大加重IO負擔.而在SQL SERVER中使用B樹進行存儲,則僅僅需要將B樹的根節點存入內存,經過幾次查找後就可以找到存放所需數據的被葉子節點包含的頁!進而避免的全盤掃描從而提高了性能.
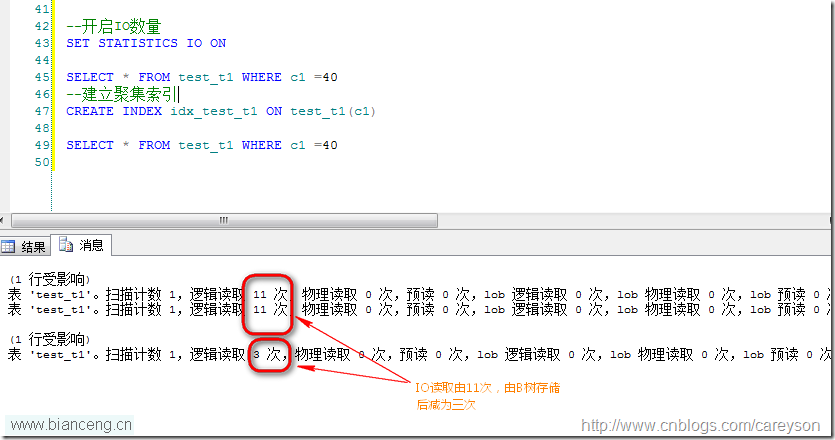
下面,通過一個例子來證明:
在SQL SERVER中,表上如果沒有建立聚集索引,則是按照堆(HEAP)存放的,假設我有這樣一張表:
現在這張表上沒有任何索引,也就是以堆存放,我通過在其上加上聚集索引(以B樹存放)來展現對IO的減少: