一、前言
在MSDN上看到一篇關於SQL Server 表分區的文檔:已分區索引的特殊指導原則,如果你對表分區沒有實戰經驗的話是比較難理解文檔裡面描述的意思。這裡我就裡面的一些概念進行講解,方便大家的交流。
SQL Server 解讀【已分區索引的特殊指導原則】(1)- 索引對齊
SQL Server 解讀【已分區索引的特殊指導原則】(2)- 唯一索引分區
二、解讀
【對非聚集索引進行分區】
“對唯一的非聚集索引進行分區時,索引鍵必須包含分區依據列。對非唯一的非聚集索引進行分區時,默認情況下 SQL Server 將分區依據列添加為索引的非鍵(包含性)列,以確保索引與基表對齊。如果索引中已經存在分區依據列,SQL Server 將不會向索引中添加分區依據列。“
(一) “對唯一的非聚集索引進行分區時,索引鍵必須包含分區依據列。“對唯一的非聚集索引進行分區,首先它是有唯一約束的,你可以參考:SQL Server 解讀【已分區索引的特殊指導原則】(2)- 唯一索引分區
(二) 其實上面這個描述中,我最關心的是否真的會默認創建包含性列?下面我們進行測試:
1) 創建一個名為[ClassifyResult]的分區表,這個分區方案是以[ClassId]作為分區依據列,[Id]+ [ClassId]作為聚集索引,並且是主鍵(唯一約束),
--創建測試表
CREATE TABLE [dbo].[ClassifyResult](
[Id] [bigint] IDENTITY(1,1) NOT NULL,
[ClassId] [int] NOT NULL CONSTRAINT [DF_ClassifyResult_ClassID] DEFAULT ((0)),
[ArchiveId] [int] NOT NULL CONSTRAINT [DF_ClassifyResult_ArchiveID] DEFAULT ((0)),
[Url] [nvarchar](400) NOT NULL CONSTRAINT [DF_ClassifyResult_Url] DEFAULT (''),
CONSTRAINT [PK_ClassifyResult] PRIMARY KEY CLUSTERED
(
[Id] ASC,
[ClassId] ASC
) ON [Sch_ClassifyResult_ClassId]([ClassId]),
CONSTRAINT [IX_ClassifyResult_Temp_ClassIdUrl] UNIQUE NONCLUSTERED
(
[ClassId] ASC,
[Url] ASC
)WITH (IGNORE_DUP_KEY = ON) ON [Sch_ClassifyResult_ClassId]([ClassId])
) ON [Sch_ClassifyResult_ClassId]([ClassId])
2) 為[ClassifyResult]創建一個非唯一的非聚集索引:[IX_ClassifyResult_ArichiveId],這個索引鍵值只有一個:[ArchiveId],並且使用了和表一樣的分區方案。
--創建一個非唯一的非聚集索引
CREATE NONCLUSTERED INDEX [IX_ClassifyResult_ArichiveId] ON [dbo].[ClassifyResult]
(
[ArchiveId] ASC
) ON [Sch_ClassifyResult_ClassId]([ClassId])
3) 按照“對非唯一的非聚集索引進行分區時,默認情況下 SQL Server 將分區依據列添加為索引的非鍵(包含性)列,以確保索引與基表對齊。“的說法,上面創建索引的SQL語句就等同於下面的SQL語句:
--創建一個非唯一的非聚集索引(include)
CREATE NONCLUSTERED INDEX [IX_ClassifyResult_ArichiveId] ON [dbo].[ClassifyResult]
(
[ArchiveId] ASC
)INCLUDE([ClassId]) ON [Sch_ClassifyResult_ClassId]([ClassId])
4) 下面就來驗證上面的說法是否正確,應該怎麼驗證呢?首先你需要了解INCLUDE有什麼作用:SQL Server 索引中include的魅力(具有包含性列的索引),所以我們就測試在Select時候返回不同的列值時候的執行計劃。執行計劃如Figure1所示:
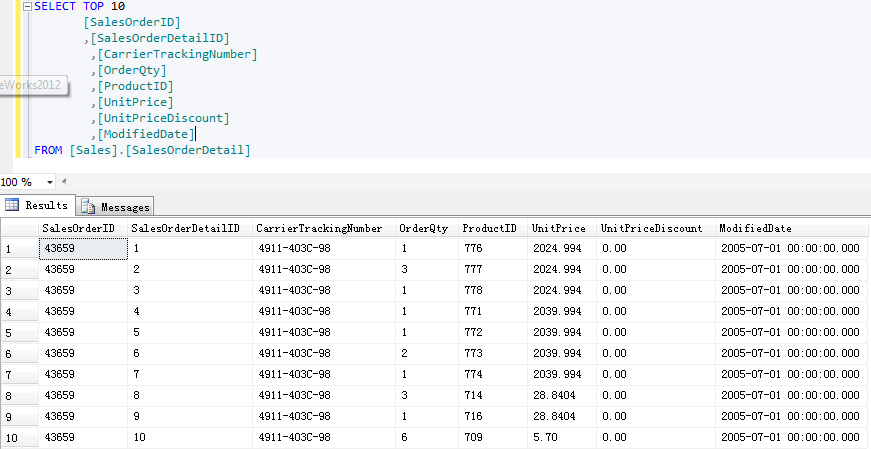
--SQL_1查詢返回[Id]和[ArchiveId] SELECT top 10 [Id],[ArchiveId] FROM [ClassifyResult] where ArchiveId = 107347
查看本欄目
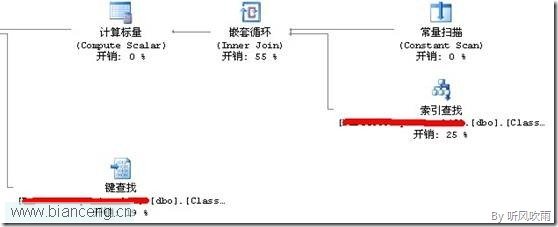
(Figure1:執行計劃)