一、前言
在MSDN上看到一篇關於SQL Server 表分區的文檔:已分區索引的特殊指導原則,如果你對表分區沒有實戰經驗的話是比較難理解文檔裡面描述的意思。這裡我就裡面的一些概念進行講解,方便大家的交流。
二、解讀
【對唯一索引進行分區】
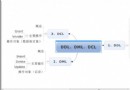
“對唯一索引(聚集或非聚集)進行分區時,必須從唯一索引鍵使用的分區依據列中選擇分區依據列。此限制將使 SQL Server 只調查單個分區,以確保表中不存在重復的新鍵值。如果分區依據列不可能包含在唯一鍵中,則必須使用 DML 觸發器,而不是強制實現唯一性。”
你對這段描述是否有自己的理解呢?這段話你可以這樣解讀:
1) “對唯一索引(聚集或非聚集)”:在創建SQL Server表結構的時候,大家很習慣的把Id值做為主鍵,這就是說把Id創建為唯一索引,並且是聚集索引,其實在SQL Server中這兩者是可以分開的;
2) “對唯一索引(聚集或非聚集)進行分區時,必須從唯一索引鍵使用的分區依據列中選擇分區依據列”,這句翻譯的很拗口,我們來看看它的英文原文:When partitioning a unique index (clustered or nonclustered), the partitioning column must be chosen from among those used in the unique index key.假如你想創建一個唯一索引UniqueIndex([SiteId] , [Url]),並想對這個唯一索引進行分區,那麼在創建索引ON選項中的分區依據列必須是UniqueIndex([SiteId] , [Url])中[SiteId] 和 [Url]這2個字段的子集([Url]或者[SiteId]或者[Url]+[SiteId])。為什麼會有這樣的要求呢?請看下面的解讀。
3) “此限制將 使 SQL Server 只調查單個分區,以確保表中不存在重復的新鍵值”,這句的意思是:假設UniqueIndex([SiteId] , [Url])索引是以SiteId作為分區依據列,那麼某個SiteId值只會屬於某單一的分區中,這樣才能保證([SiteId] , [Url])這兩個字段在單個分區是唯一就表示了在整個表是也是唯一的;再假設:如果上面的唯一索引UniqueIndex([SiteId] , [Url])是以Id作為分區依據列的,那麼你怎麼確保各個單個分區裡的數據在整個表中是唯一的呢?數據庫是沒有辦法的。SQL Server是想偷懶,它想當判斷了某個分區的唯一索引在這個是唯一就可以省事很多,不需要去全局整個表判斷,這樣是不是省事很多?
4) “如果分區依據列不可能包含在唯一鍵中,則必須使用 DML 觸發器,而不是強制實現唯一性。”上面的所有描述都是有一個前提的,那就是你希望索引與基表對齊,如果在不用對齊的情況下,你可以使用DML觸發器,或者單獨一個文件組來存放唯一索引,如果這樣,你就不能使用分區切換了。
作者:聽風吹雨
出處:http://gaizai.cnblogs.com/
查看本欄目