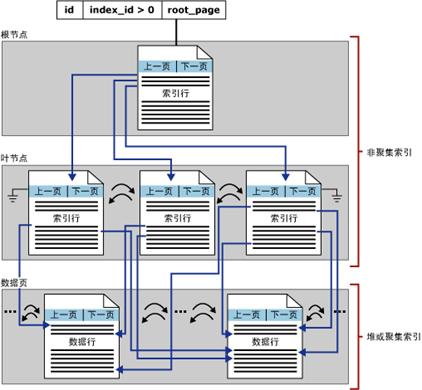
非聚集索引與聚集索引具有相同的 B 樹結構,它們之間的顯著差別在於以下兩點:
基礎表的數據行不按非聚集鍵的順序排序和存儲。
非聚集索引的葉層是由索引頁而不是由數據頁組成。
非聚集索引既可以建在堆表結構上也可以建在聚集索引表上;非聚集索引中的每個索引行都包含非聚集鍵值和行定位符。此定位符指向聚集索引或堆中包含該鍵值的數據行。
如果表是堆則行定位器是指向行的指針。該指針由文件標識符 (ID)、頁碼和頁上的行數生成。整個指針稱為行 ID (RID)。
如果表包含有聚集索引,則行定位器是行的聚集索引鍵。如果聚集索引不是唯一的索引,SQL Server 將添加在內部生成的值(稱為唯一值)以使所有重復鍵唯一。此四字節的值對於用戶不可見。僅當需要使聚集鍵唯一以用於非聚集索引中時,才添加該值。SQL Server 通過使用存儲在非聚集索引的葉行內的聚集索引鍵搜索聚集索引來檢索數據行。
B 樹的頁集合由 sys.system_internals_allocation_units 系統視圖中的 root_page 指針定位。
堆表
--創建一張堆表
CREATE TABLE testHeapIndex
(
name CHAR(200),
type1 CHAR(900),
type2 CHAR(900)
)
--分別創建一個唯一索引和一個非唯一索引
CREATE UNIQUE INDEX idx_testHeapIndex1 ON testHeapIndex(type1)
CREATE INDEX idx_testHeapIndex2 ON testHeapIndex(type2)
--插入測試數據
INSERT INTO testHeapIndex VALUES('A','A1','A2')
INSERT INTO testHeapIndex VALUES('B','B1','B2')
INSERT INTO testHeapIndex VALUES('C','C1','B2')
INSERT INTO testHeapIndex VALUES('D','D1','B2')
INSERT INTO testHeapIndex VALUES('E','E1','C2')
INSERT INTO testHeapIndex VALUES('F','F1','F1')
INSERT INTO testHeapIndex VALUES('G','G1','G1')
INSERT INTO testHeapIndex VALUES('H','H1','G1')
INSERT INTO testHeapIndex VALUES('I','I1','G1')
INSERT INTO testHeapIndex VALUES('J','J1','J1')
--獲取該表的相應頁面信息
SELECT A.NAME TABLE_NAME,B.NAME INDEX_NAME,B.INDEX_ID
FROM SYS.OBJECTS A,SYS.INDEXES B
WHERE A.OBJECT_ID=B.OBJECT_ID AND A.NAME='testHeapIndex'
TRUNCATE TABLE tablepage;
INSERT INTO tablepage EXEC ('DBCC IND(testdb,testHeapIndex,0)');
INSERT INTO tablepage EXEC ('DBCC IND(testdb,testHeapIndex,2)');
INSERT INTO tablepage EXEC ('DBCC IND(testdb,testHeapIndex,3)');
SELECT
b.name table_name,
CASE WHEN c.type=0 THEN '堆'
WHEN c.type=1 THEN '聚集'
WHEN c.type=2 THEN '非聚集'
ELSE '其他'
END index_type,
c.name index_name,
PagePID,IAMPID,ObjectID,IndexID,Pagetype,IndexLevel,
NextPagePID,PrevPagePID
FROM tablepage a,sys.objects b,sys.indexes c
WHERE A.ObjectID=b.object_id
AND A.ObjectID=c.object_id
AND a.IndexID=c.index_id
--獲取該表的root頁面地址,聚集索引的根節點必須通過下面腳本才能找到
SELECT c.name,a.type_desc,d.name,
total_pages,used_pages,data_pages,
testdb.dbo.f_get_page(first_page) first_page_address,
testdb.dbo.f_get_page(root_page) root_address,
testdb.dbo.f_get_page(first_iam_page) IAM_address
FROM sys.system_internals_allocation_units a,sys.partitions b,sys.objects c,sys.indexes d
WHERE a.container_id=b.partition_id and b.object_id=c.object_id
AND d.object_id=b.object_id AND d.index_id=b.index_id
AND c.name in ('testHeapIndex')
--下面各個例子獲取相關頁面和root頁面的腳本基本相同,不再重復