SQL Server 2005是微軟在推出SQL Server 2000後時隔五年推出的一個數據庫.相對於SQL Server2000來說有了質的提高。它給我們提供了諸多新特性,例如:復制、分區、動態管理視圖、CTE、性能顧問等等。
在微軟TechNet上是這樣介紹分區表和分區索引的:
Instruction 已分區表和已分區索引的數據劃分為分布於一個數據庫中多個文件組的單元。數據是按水平方式分區的,因此多組行映射到單個的分區。對數據進行查詢或更新時,表或索引將被視為單個邏輯實體。單個索引或表的所有分區都必須位於同一個數據庫中。
已分區表和已分區索引支持與設計和查詢標准表和索引相關的所有屬性和功能,包括約束、默認值、標識和時間戳值以及觸發器。因此,如果要實現位於服務器本地的已分區視圖,則可能需要改為實現已分區表。
決定是否實現分區主要取決於表當前的大小或將來的大小、如何使用表以及對表執行用戶查詢和維護操作的完善程度。
通常,如果某個大型表同時滿足下列兩個條件,則可能適於進行分區:
該表包含(或將包含)以多種不同方式使用的大量數據。
不能按預期對表執行查詢或更新,或維護開銷超過了預定義的維護期。
例如,如果對當前月份的數據主要執行 INSERT、UPDATE 和 DELETE 操作,而對以前月份的數據主要執行 SELECT 查詢,則如果按月份對表進行分區,表的管理可能要容易些。如果對表的常規維護操作只針對一個數據子集,那麼此優點尤為明顯。如果該表沒有分區,那麼就需要對整個數據集執行這些操作,這樣就會消耗大量資源。例如,通過分區,可以針對具有只寫數據的單個月份執行類似索引重新生成和碎片整理的維護操作,而只讀數據仍可用於聯機訪問。 正如上面的描述,分區為可以將對數據的操作壓力分散到各個分區文件組中,應用程序每次訪問的數據只是在某個數據分區上,這樣可以相應的提高數據庫的性能。
找個了數據量在200W左右的表,這個表是一個賬本類型的表,可以以時間日期作為分區依據列,將200W數據依據月份分配到12個分區上。然後執行業務存儲過程進行測試:
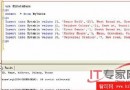
SP exec proc_partitiontest @HCompany=N’0002’,@HOrg=N’00000000000000000223’,
@FiscalYear=N’2008’,@FiscalPeriod=N’01’,
@HWareHouseID=N’’,@SpeStock=N’’,@ofObject=N’’ ,......
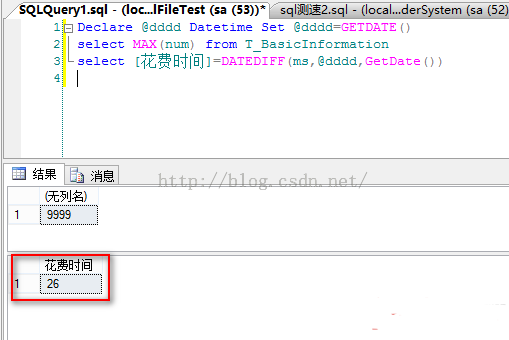
執行結果比較:
分區前:執行時間52s ,IO cost:
Table 'PartitionAccount'. Scan count 2, logical reads 1735, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
分區後:執行時間47s ,IO cost:
Table 'PartitionAccount'. Scan count 2, logical reads 76, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
對性能提高很一般,是數據量較少的原因麼?還是查詢應用分區鍵不太合理?因為一些原因,這個sp的具體寫法不能貼出,請各位朋友諒解。在這裡,請朋友們談談分區的關鍵,謝謝。