簡介:
如果兩個聯接輸入並不小但已在二者聯接列上排序(例如,如果它們是通過掃描已排序的索引獲得的),則合並聯接是最快的聯接操作。如果兩個聯接輸入都很大,而且這兩個輸入的大小差不多,則預先排序的合並聯接提供的性能與哈希聯接相近。
從上次我們分析來看,嵌套循環適合輸入和輸出都小的情況,那如果輸入和輸入都比較大情況下,使用合並算法什麼情況下最優。
最佳使用:
合並聯接本身的速度很快,但如果需要排序操作,選擇合並聯接就會非常費時。然而,如果數據量很大且能夠從現有 B 樹索引中獲得預排序的所需數據,則合並聯接通常是最快的可用聯接算法。
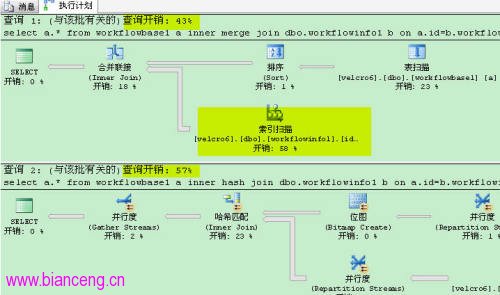
我們來測試一下,合並連接的最優情況:
測試環境:表:workflowinfo1 約45萬條 表workflowbase1 約4.5萬條
條件:workflowbase1中列id,creater都建立索引,workflowinfo1中workflowid建立了索引。
如果兩個聯接輸入並不小但已在二者聯接列上排序(例如,如果它們是通過掃描已排序的索引獲得的),則合並聯接是最快的聯接操作。如果兩個聯接輸入都很大,而且這兩個輸入的大小差不多,則預先排序的合並聯接提供的性能與哈希聯接相近。~:(creater=4028814110830a1e01108fe379e60061’的workflowbase1表有1023條數據)
測試語句:
合並算法
select a.* from workflowbase1 a inner merge join dbo.workflowinfo1 b
on a.id=b.workflowid and a.creater='4028814110830a1e01108fe379e60061'
hash算法
select a.* from workflowbase1 a inner hash join dbo.workflowinfo1 b
on a.id=b.workflowid and a.creater='4028814110830a1e01108fe379e60061'
注意:這兩條SQL和上一個嵌套循環的例子有區別,一個 select * 和一個是 select a.*
重啟數據庫服務,查看成本: