對於關系型數據庫來說,表現樹狀的層次結構始終是一個問題。微軟在SQL Server 2005中首次嘗試了 解決這個問題,那就是被稱之為通用數據表表達式(Common Table Expressions,CTE)的實現方式。
盡管CTE在現有的數據庫架構中運行良好,微軟找到了一種將此類層次結構作為頭等概念來使用的方式 。因此,為了實現這種效果,他們在SQL Server 2008中提出了一種“HierarchId”數據類型 。
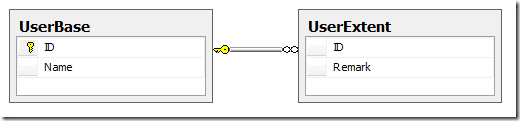
在傳統的層次結構中,一條記錄僅僅儲存了一個指向它父記錄的引用,這使得一條記錄能夠獲得它在 層次結構中的相對位置,而不是絕對位置。改變某條記錄的父數據行引用是一個原子更新操作,它不會影 響到該記錄的任何子記錄。
一個HierarchyId類型的字段儲存了記錄在層次結構中的准確位置。Denny Cherry提供了一個例子,其 中展示了0x、0x58以及0x5AC0三個值,它們的字符串表現形式分別為“/”, “/1/”和“/1/1/”。這就引發了有關一致性和性能方面的問題,尤其是父記錄被 改變的時候。Ravi S.Maniam建議在改變父記錄操作不頻繁的情況下使用這種設計方式。
與HierarchyId類型同時出現的還有一系列函數。GetAncestor和GetDescendant方法可以用來遍歷樹。 ToString和Parse方法用於HierarchyId類型二進制與字符串表現形式之前的轉換。有些古怪的是,隨之而 來的還有用於支持BinaryReader與BinaryWriter的一些方法。
再來回頭看看GetDescendant,這是一個有些古怪的方法。它實際上不返回那些子記錄,而是返回那些 潛在的子節點的位置。向樹中插入一個新的記錄時,我們必需調用GetDescendant方法來獲得指定父記錄 的最後一個子節點的位置,然後才能獲得緊跟著該位置之後的空隙。
迄今為止還沒有使用T-SQL來獲得樹狀結構的合適示例。事實上,與它有關的所有東西都更像是一些命 令,而不是基於集合的操作。