當我們想統計數據表的記錄總數時,我們使用的T-SQL函數count(*) 。如果在 一個包含了數百萬行的大表中執行這個函數的話,,可以要花很長時間才能返回 整個表的記錄總數,這導致了查詢性能的下降。
一、常規辦法:采用Count ()函數
每個數據庫管理員知道如何使用count(*) 函數。SQL Server在執行這個函數 時,為了返回總表的行計數,需要對索引/表進行完整的掃描。因此建議DBA們盡 量避免針對整個表使用聚合函數count(*),因為它影響了數據庫的性能。
下面我們來看個AdventureWorks數據庫中的例子。
在查詢分析器中執行下面的查詢語句:
use AdventureWorks
go
select count (*) from Sales.SalesOrderDetail
查詢分析器執行後,顯示有121317行。
當我們點擊SQL Server 2005 Management Studio的工具欄上的“顯示估 計的執行計劃”圖標時,我們可以得到以下的圖表:
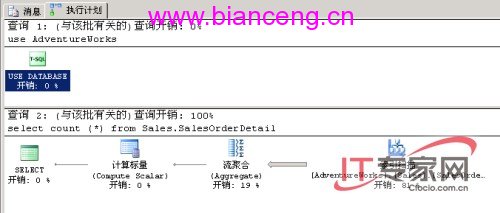
圖1:count(*)函數的執行計劃
從右到左來看,我們可以了解到SQL語句的執行過程:
l 第一步中對整個表進行索引掃描,這是個非常耗時的過程(占81%)。
l 第二步中應用流聚合也較耗時(占19%)。