1. 索引的體系結構
為什麼要不斷的維護表的索引?首先,簡單介紹一下索引的體系結構。SQL Server在硬盤中用8KB頁面在數據庫文件內存放數據。缺省情況下這些頁面及其包含的數據是無組織的。為了使混亂變為有序,就要生成索引。生成索引後,就有了索引頁和數據頁,數據頁保存用戶寫入的數據信息。索引頁存放用於檢索列的數據值清單(關鍵字)和索引表中該值所在紀錄的地址指針。索引分為簇索引和非簇索引,簇索引實質上是將表中的數據排序,就好像是字典的索引目錄。非簇索引不對數據排序,它只保存了數據的指針地址。向一個帶簇索引的表中插入數據,當數據頁達到100%時,由於頁面沒有空間插入新的的紀錄,這時就會發生分頁,SQL Server 將大約一半的數據從滿頁中移到空頁中,從而生成兩個半的滿頁。這樣就有大量的數據空間。簇索引是雙向鏈表,在每一頁的頭部保存了前一頁、後一頁地址以及分頁後數據移動的地址,由於新頁可能在數據庫文件中的任何地方,因此頁面的鏈接不一定指向磁盤的下一個物理頁,鏈接可能指向了另一個區域,這就形成了分塊,從而減慢了系統的速度。對於帶簇索引和非簇索引的表來說,非簇索引的關鍵字是指向簇索引的,而不是指向數據頁的本身。
為了克服數據分塊帶來的負面影響,需要重構表的索引,這是非常費時的,因此只能在需要時進行。可以通過DBCC SHOWCONTIG來確定是否需要重構表的索引。
2. DBCC SHOWCONTIG用法
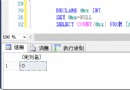
下面舉例來說明DBCC SHOWCONTIG和DBCC REDBINDEX的使用方法。以應用程序中的Employee數據表作為例子,在 SQL Server的Query analyzer輸入命令:
use database_name
declare @table_id int
set @table_id=object_id('Employee')
dbcc showcontig(@table_id)
輸出結果:
DBCC SHOWCONTIG scanning 'Employee' table...
Table: 'Employee' (1195151303); index ID: 1, database ID: 53
TABLE level scan performed.
- Pages Scanned................................: 179
- Extents Scanned..............................: 24
- Extent Switches..............................: 24
- Avg. Pages per Extent........................: 7.5
- Scan Density [Best Count:Actual Count].......: 92.00% [23:25]
- Logical Scan Fragmentation ..................: 0.56%
- Extent Scan Fragmentation ...................: 12.50%
- Avg. Bytes Free per Page.....................: 552.3
- Avg. Page Density (full).....................: 93.18%
DBCC execution completed. If DBCC printed error messages, contact your system administrator.