本文主旨:條件列上的索引對數據庫delete操作的影響。
事由:今天在博客園北京俱樂部MSN群中和網友討論了關於索引對delete的影響問題,事後感覺非常汗顏,因為我的隨口導致錯誤連篇。大致話題是這樣的,並非原話:
[討論:] delete course where classID=500001 classID上沒有創建任何索引,為了提高刪除效率,如果在classID上創建一個非聚集索引會不會提高刪除的效率呢?
我當時的觀點:不能。
我當時的理由:數據庫在執行刪除時,如果在classID上創建了非聚集索引,首先按這個非聚集索引查找數據,找到索引行後,根據索引行後面帶的聚集索引地址最後找到真正的物理數據行,並且執行刪除,這個過程看起來沒有作用,只能創建聚集索引來提高刪除效率,因為如果classID是聚集索引,那麼直接聚集索引刪除,此時的效率最高。
下班後對這個話題再次想了下,覺的自己的觀點都自相矛盾,既然知道刪除時,會在條件列上試圖應用已經存在的索引,那麼為什麼創建非聚集索引會無效呢?如果表的數據相當大,classID上如果沒有任何索引,查找數據時就要執行表掃描,而表掃描的速度是相當慢的,為此為了證明下這個問題,我特意做了一個示意性的實驗。
創建兩個表course 和course2,創建語句如下,它們唯一的區別就在於索引,course表中classID上創建了非聚集索引,而course2上沒有創建任何索引。
CREATE TABLE [dbo].[course](
[ID] [int] IDENTITY(1,1) NOT NULL,
[sCourseName] [nchar](10) COLLATE Chinese_PRC_CI_AS NULL,
[classID] [int] NULL,
CONSTRAINT [PK_CKH] PRIMARY KEY CLUSTERED
(
[ID] ASC
)WITH (IGNORE_DUP_KEY = OFF) ON [PRIMARY]
) ON [PRIMARY]
--創建索引
create index IX_classID
on course(classID)
CREATE TABLE [dbo].[course2](
[ID] [int] IDENTITY(1,1) NOT NULL,
[sCourseName] [nchar](10) COLLATE Chinese_PRC_CI_AS NULL,
[classID] [int] NULL,
CONSTRAINT [PK_CKH2] PRIMARY KEY CLUSTERED
(
[ID] ASC
)WITH (IGNORE_DUP_KEY = OFF) ON [PRIMARY]
) ON [PRIMARY]
實驗過程:
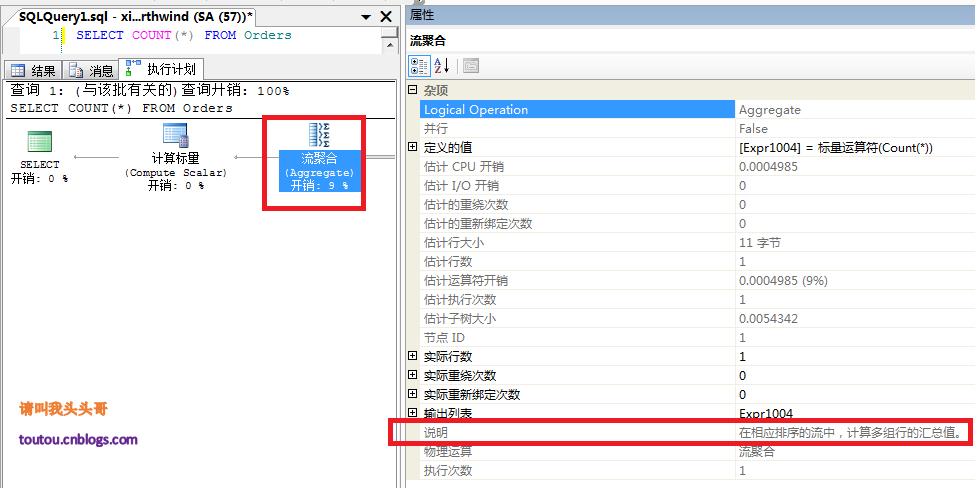
第一步:分別給兩個表插入相當的數據1000行,然後刪除第500條記錄。
delete course
where classID=500
delete course2
where classID=500