如果你像我一樣,那麼你就會有一個在適當位置的SQL Agent任務需要重建和重新組織,而實際上只有你數據庫中的索引需要這樣的操作。如果你依賴於Microsoft SQL Server中的標准技術維護計劃,那麼重建所有索引的焦土政策將產生。更確切地說,無論這些操作是否要求被用到具體的索引中,索引的重建以及對所有鎖和日志的攪拌都會發生。這就是為什麼可以說大多數人都會推出自己的索引維護解決方案。這也正是我最大的煩惱之一。無論如何,通過只維護成為碎片的索引,相對於你數據庫中的表/索引,統計數據不能發生全面自動更新。我們所需要的正是對我們的SQL Server實例上的每一個數據庫采取更新所有統計這樣一個快速的解決方案。
在你開始操作前,我必須聲明一個事實,那就是你在自己的數據庫上有AUTO_UPDATE_STATISTICS ON,但請記住那並不意味著它們正在更新!
可能你對此會很不屑。那麼請稍微思考這個問題。當處在下面的情況時,SQL Server的引擎將會自動更新:
l 當數據剛被添加到一張空表時
l 當統計是上次搜集的並且從搜集開始,統計數據對象的主要字段每500秒增長一次時,這張表的記錄超過500。
l 當統計數據是上次搜集的,並且,從上次統計數據搜集日期起統計數據對象的主要字段按照每500秒加上行數的20%更改時。
在這個標准下,有很多這樣的情況:當潛在的數據以這樣一種方式或者層次變化時,存在於一個索引中的統計不能正確反映數據庫中真實的數據。正因為如此,你不能僅僅依賴於引擎來使你的統計保持檢查和更新成當前的狀態。這是一個簡單的代碼塊,它將迭代處理你的數據庫以此來建立sp_updatestats命令,該命令隨後將被復制粘貼到一個新的查詢窗口來執行。這些代碼將與所有當前的和先前的SQL Server版本一道回到SQL 7.0工作。
DECLARE @SQL VARCHAR(1000)
DECLARE @DB sysname
DECLARE curDB CURSOR FORWARD_ONLY STATIC FOR
SELECT [name]
FROM sys..sysdatabases
WHERE [name] NOT IN ('model', 'tempdb')
ORDER BY [name]
OPEN curDB
FETCH NEXT FROM curDB INTO @DB
WHILE @@FETCH_STATUS = 0
BEGIN
SELECT @SQL = 'USE [' + @DB +']' + CHAR(13) + 'EXEC sp_updatestats' + CHAR(13)
PRINT @SQL
FETCH NEXT FROM curDB INTO @DB
END
CLOSE curDB
DEALLOCATE curDB
在我的測試數據庫中,這些代碼產生了下面的結果:
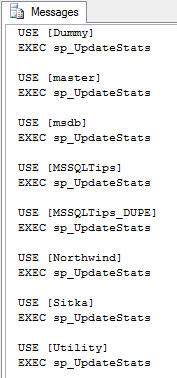
圖1
接下來我們把復制這個文本,把它粘貼到SQL Server管理套件的一個查詢窗口,然後針對這個實例執行它。另一種方法是,你可以選擇只針對select數據庫執行它,但這完全取決於你。
USE [Dummy]
EXEC sp_UpdateStats
USE [master]
EXEC sp_UpdateStats
USE [msdb]
EXEC sp_UpdateStats
USE [MSSQLTips]
EXEC sp_UpdateStats
USE [MSSQLTips_DUPE]
EXEC sp_UpdateStats
USE [Northwind]
EXEC sp_UpdateStats
USE [Sitka]
EXEC sp_UpdateStats
USE [Utility]
EXEC sp_UpdateStats
我已經提供了上面執行的SQL語句搜集產生的輸出結果實例。正如你看到的,引擎仍然會審查這些統計,看看它們是否需要更新。它將忽略哪些可以接受的,只更新那些要求這種操作的統計。我可以向你保證,上面列出的每一個數據庫都把AUTO_UPDATE_STATISTICS和AUTO_CREATE_STATISTICS設置成ON,但下面的結果表明統計數據將變成過時的。
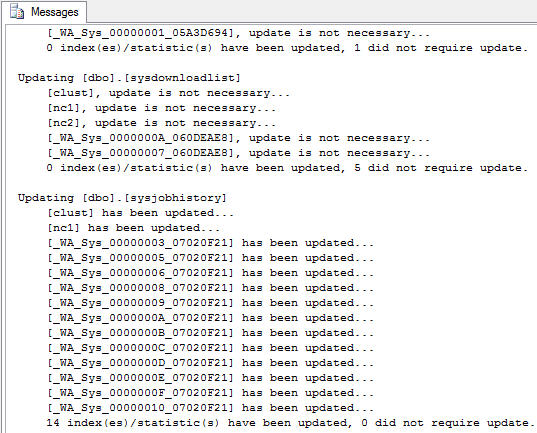
圖2