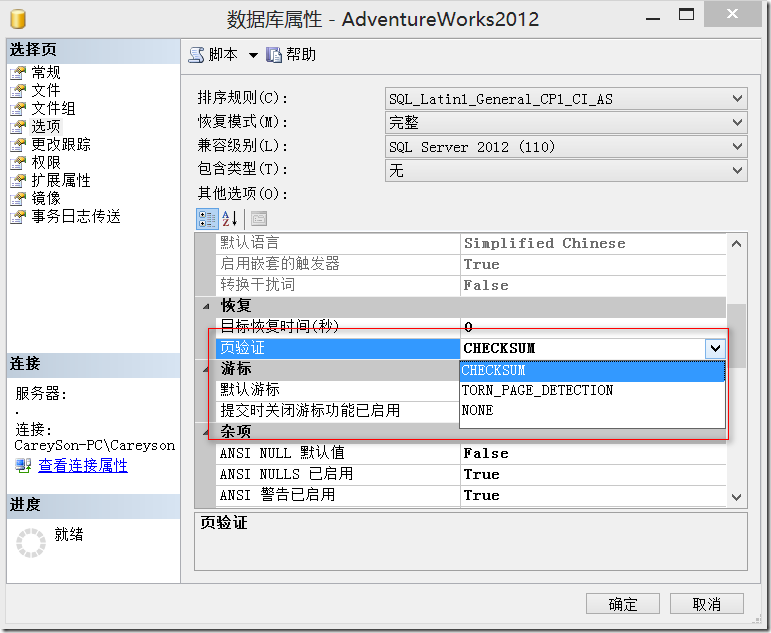
在數據庫中創建索引時,查詢所使用的索引信息存儲在索引頁中。連續索引頁由從一個頁到下一個頁的指針鏈接在一起。當對數據的更改影響到索引時,索引中的信息可能會在數據庫中分散開來。重建索引可以重新組織索引數據(對於聚集索引還包括表數據)的存儲,清除碎片。這可通過減少獲得請求數據所需的頁讀取數來提高磁盤性能。
在 Microsoft® SQL Server™ 2000 中,如果要用一個步驟重新創建索引,而不想刪除舊索引並重新創建同一索引,則使用 CREATE INDEX 語句的 DROP_EXISTING 子句可以提高效率。這一優點既適用於聚集索引也適用於非聚集索引。
以刪除舊索引然後重新創建同一索引的方式重建聚集索引,是一種昂貴的方法,因為所有二級索引都使用聚集鍵指向數據行。如果只是刪除聚集索引然後重新創建,則會使所有非聚集索引都被刪除和重新創建兩次。一旦刪除聚集索引並再次重建該索引,就會發生這種情形。通過在一個步驟中重新創建索引,可以避免這一昂貴的做法。在一個步驟中重新創建索引時,會告訴 SQL Server 要重新組織現有索引,避免了刪除和重新創建非聚集索引這些不必要的工作。該方法的另一個重要優點是可以使用現有索引中的數據排序次序,從而避免了對數據重新排序。這對於聚集索引和非聚集索引都十分有用,可以顯著減少重建索引的成本。另外,通過使用 DBCC DBREINDEX 語句,SQL Server 還允許對一個表重建(在一個步驟中)一個或多個索引,而不必單獨重建每個索引。
DBCC DBREINDEX 也可用於重建執行 PRIMARY KEY 或 UNIQUE 約束的索引,而不必刪除並創建這些約束(因為對於為執行 PRIMARY KEY 或 UNIQUE 約束而創建的索引,必須先刪除該約束,然後才能刪除該索引)。例如,可能需要在 PRIMARY KEY 約束上重建一個索引,以便為該索引重建給定的填充因子。