一個數據庫能否保持信息的正確性、及時性、很大程度上依賴於數據庫的更新功能的強弱與實時。數據庫的更新包括插入、刪除、修改(也稱為更新)三種操作。本章將分別講述如何使用這些操作,以便有效地更新數據庫。
在SQL Server 中可以在Enterprise Manager 中查看數據庫表的數據時添加數據,但這種方式不能應付數據的大量插入,需要使用INSERT 語句來解決這個問題。
11.1.1 INSERT 語法
數據庫的信息時常需要改變用戶需要添加數據,INSERT 語句提供了此功能。INSERT語句通常有兩種形式。一種是插入一條記錄;另一種是插入子查詢的結果。後者可以一次插入多條記錄。


注意:當插入VARBINARY類型的數據時,其尾部的“0”將被去掉。
當插入VARCHAR或TEXT類型的數據時,其後的空格將被去掉,如果插入一個只含空格的字符串,則會被認為插入了一個長度為零的字符串。
IDENTITY列不能指定數據,在VALUES列表中應跳過此列。
對字符類型的列,當插入數據,特別是插入字符串中含有數字字符以外的字符時,最好用引號將其括起來,否則容易出錯。
column_list中列的順序可以與表結構中的順序不同,但VALUES中的值必須與COLUMN_list中的列相對應。
11.1.2 插入單行
以下舉例說明如何插入單行數據:
例11-1: 插入數據到訂購商信息表中。
use pangu
insert firms
(firm_id, f_name, f_intro)
values(10070001, 'SQL', '制作數據庫軟件的公司')
運行結果如下:
(1 row(s) affected)
例11-2: 插入數據到訂購商信息表中。
use pangu
insert firms
/* 當表中所有的列均被指定時可以省略column_list */
values(10070001, 'SQL', '制作數據庫軟件的公司', 100700010007, '00-12345678', 234325, 'chengdu')
11.1.3 插入子查詢結果
子查詢不僅可以嵌套在SELECT 語句中,用以構造父查詢的條件,也可以嵌套在
INSERT 語句中,用以生成要插入的數據。插入子查詢的INSERT 語句語法如下:
INSERT [INTO]
{ table_name WITH ( <table_hint_limited> [...n])
| view_name
| rowset_function_limited }
{ [(column_list)]
subquery }
其功能是以批量插入,一次將子查詢的結果全部插入指定表中。
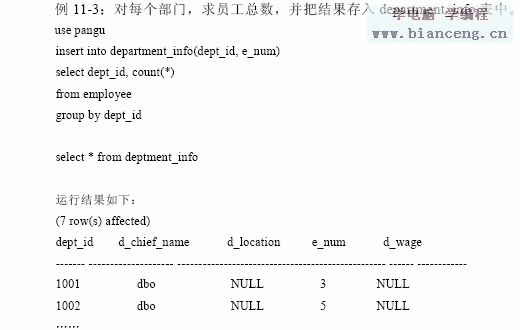
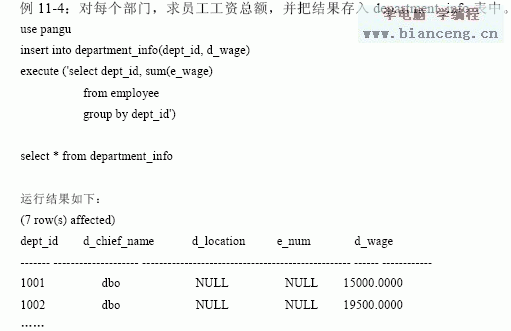
11.1.4 用存儲過程插入數據
在INSERT 語句中可以通過執行存儲過程來取得要插入的數據。所插入的數據是存儲
過程中SELECT 語句所檢索的結果集。使用存儲過程插入數據的語法如下:
INSERT [INTO]
{ table_name WITH ( <table_hint_limited> [...n])
| view_name
| rowset_function_limited }
{ [(column_list)]
EXECUTE procedure
其中procedure 既可以是一個已經存在的系統存儲過程或用戶自定義的存儲過程,也
可以在INSERT 語句中直接編寫存儲過程。