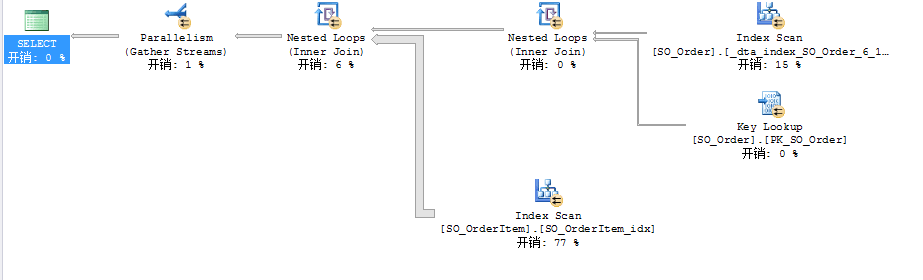
本文通過詳細分析一個示例來說明SEEK、SCAN等操作的用法和效果,供大家參考!
入門指南
讓我們以一個簡單的例子幫助你理解如何閱讀查詢計劃,可以通過發出SET SHOWPLAN_TEXT On命令,或者在SQL Query Analyzer 的配置屬性中設置同樣的選項等方式得到查詢計劃。
注意:這個例子使用了表pubs.big_sales,該表與pubs..sales表完全相同,除了多了80000行的記錄,以當作簡單explain plan例子的主要數據。
如下所示,這個最簡單的查詢將掃描整個聚集索引,如果該索引存在。注意聚集鍵值是物理次序,數據按該次序存放。所以,如果聚集鍵值存在,你將可能避免對整個表進行掃描。即使你所選的列不在聚集鍵值中,例如ord_date,這個查詢引擎將用索引掃描並返回結果集。
SELECT *
FROM big_sales
SELECT ord_date
FROM big_sales
StmtText
-------------------------------------------------------------------------
|--ClusteredIndexScan(OBJECT:([pubs].[dbo].[big_sales].[UPKCL_big_sales]))
上面的查詢展示返回的數據量非常不同,所以小結果集(ord_date)的查詢比其它查詢運行更快,這只是因為存在大量底層的I/O。然而,這兩個查詢計劃實際上是一樣的。你可以通過使用其它索引提高性能。例如,在title_id列上有一個非聚集索引存在:
SELECT title_id
FROM big_sales
StmtText
------------------------------------------------------------------
|--Index Scan(OBJECT:([pubs].[dbo].[big_sales].[ndx_sales_ttlID]))
上面的查詢的執行時間與SELECT *查詢相比非常小,這是因為可以從非聚集索引即可得到所有結果。該類查詢被稱為covering query(覆蓋查詢),因為全部結果集被一個非聚集索引所覆蓋。