介紹
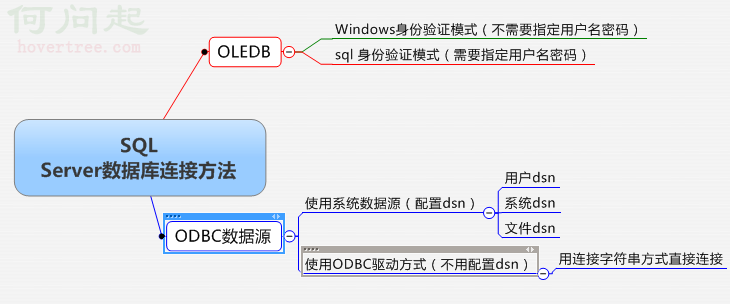
mixer希望在proxy這層就提供自定義路由,sql黑名單,防止sql注入攻擊等功能,而這些的基石就在於將用戶發上來的sql語句進行解析。也就是我最頭大的詞法分析和語法分析。
到現在為止,我只是實現了一個比較簡單的詞法分析器,用以將sql語句分解成多個token。而對於從token在進行語法分析,構建sql的AST,我現在還真沒啥經驗(編譯原理太差了),急需牛人幫忙。
所以,這裡只是簡單介紹一下mixer的詞法分析。
tokenize
在很多地方,我們都需要進行詞法分析,通常會有幾種方式:
使用一個強大的工具,譬如lex,mysql-proxy就用的這種方式
使用正則表達式
state machine
對於使用工具,我覺得有一個不怎麼好的地方在於學習成本,譬如我用lex的時候就需要學習它的語法,同時通過工具生成的代碼可讀性都不怎麼好,代碼量大,更嚴重的是可能會比較慢。所以mysql自身也是自己實現一個詞法分析模塊。
而對於正則表達式,性能問題可能是一個很需要考慮的,而且復雜度並不比使用類似lex這樣的工具低。
狀態機可能是我覺得自己動手實現詞法解析一個很好的方式,對於sql的詞法解析,我覺得使用state machine的方式來自己寫一個難度並不大,所以mixer自己實現了一個。
state machine
通常,一個狀態機的實現采用的是state + action + switch的做法,可能如下:
?
1 2 3 4 5 6 7 8 switch state { case state1: state = action1() case state2: state = action2() case state3: state = action3() }對於一個state,我們通過switch知道它將會由哪一個action進行處理,而對於每一個action,我們則知道執行完成之後下一個state是什麼。
對於上面的實現,如果state過多,可能會導致太多的case語句,我們可以通過state function進行簡化。
一個state function就是執行當前的state action,並且直接返回下一個state function。
我們可以這樣做:
?
1 2 3 4 5 type stateFn func(*Lexer) stateFn for state := startState; state != nil { state = state(lexer) }所以我們需要實現的就是每一個state function以及對應的它的下一個需要執行的state function。
mixer lexer
mixer的詞法分析實現主要參考這個。主要實現在parser模塊。
對於一個lexer,需要提供的是NextToken的功能,供外部獲取下一個token,從而進行後續的操作(譬如語法分析)。
lexer的next token如下:
?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 func (l *Lexer) NextToken() (Token, error) { for { select { case t := <-l.tokens: return t, nil default: if l.state == nil { return Token{TK_EOF, ""}, l.err } l.state = l.state(l) if l.err != nil { return Token{TK_UNKNOWN, ""}, l.err } } } }tokens是一個channel,每次state解析的token都會emit到這個channel上面,供NextToken獲取,如果channel為空了,則再次調用state function。
可以看到,用go實現一個詞法解析是很容易的事情,剩下的就是寫相應的state function用來解析sql。
todo
mixer的詞法分析還有很多不完善的地方,譬如對於科學計數法數值的解析就不完善,後續准備參考mysql官方的詞法分析模塊在好好完善一下。