前段時間數據庫健康檢查發現SQL Server服務器的idle時間變少,IO還是比較空閒,估計是遇到了高CPU占用的語句了。
介紹一下背景,我們公司負責運維N多的應有系統,負責提供良好的軟、硬件環境,至於應用的開發質量,我們就無能為力了
解決這個問題,我的思路是:
找出CPU占用最大的語句。
分析查詢計劃。
優化。
1、找出語句
使用SQL Server自帶的性能報表(不是報表服務),找出CPU占用最大的語句。如圖1所示
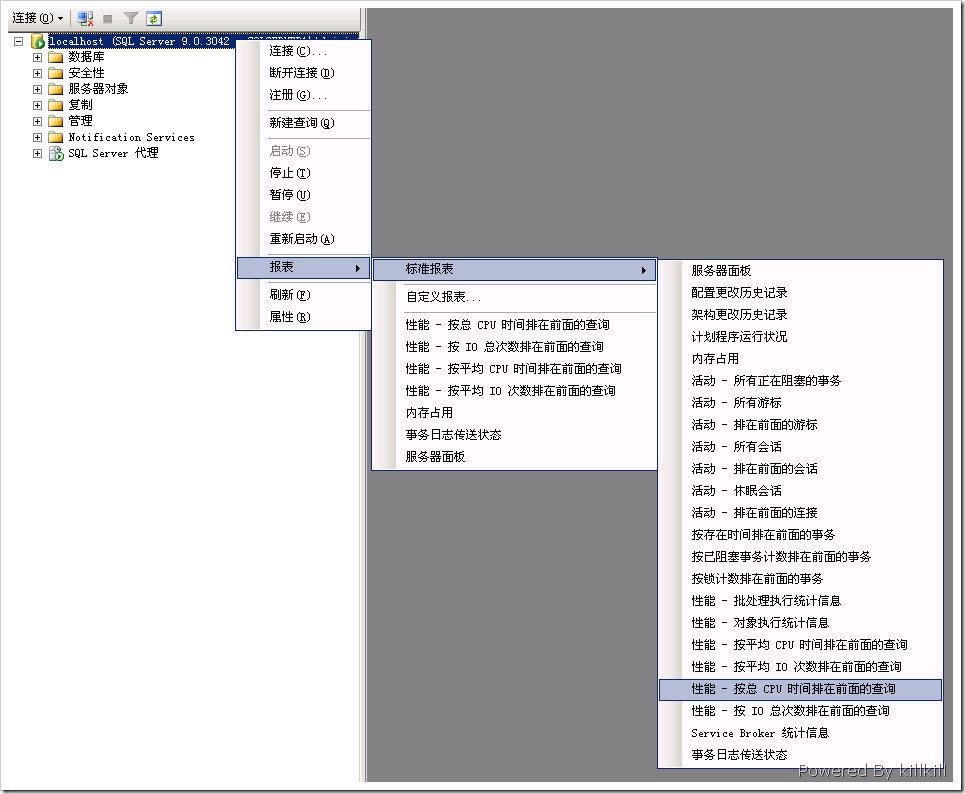
圖1 性能報表
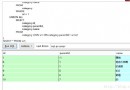
我選取了“性能-按總CPU時間排在前面的查詢”,得出以下兩張報表,如圖2所示:
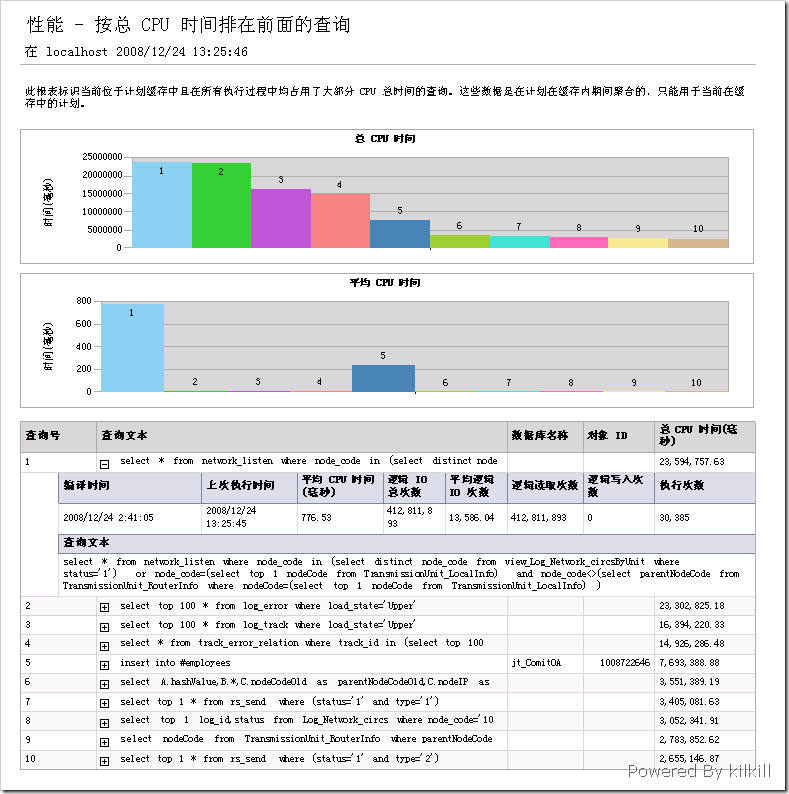
圖2 性能-按總CPU時間排在前面的查詢
在報表中不能直接把語句Copy出來,非得讓我另存為Excel才能Copy語句;而且經常標示不了是語句屬於哪個數據庫,不爽 :( 。
費了我九牛二虎之力才找出該條語句在哪個數據庫執行,然後馬上備份數據庫,在另一個非生產數據庫上面還原,創造實驗環境。
廢話少說,我把語句Copy出來,順便整理了一下格式。如下:
select*
fromnetwork_listen
where
node_codein
(
selectdistinctnode_code
fromview_Log_Network_circsByUnit
wherestatus='1'
)
or
node_code=
(
selecttop1nodeCode
fromTransmissionUnit_LocalInfo
)
and
node_code<>
(
selectparentNodeCode
fromTransmissionUnit_RouterInfo
wherenodeCode=
(
selecttop1nodeCode
fromTransmissionUnit_LocalInfo
)
)
2、分析語句
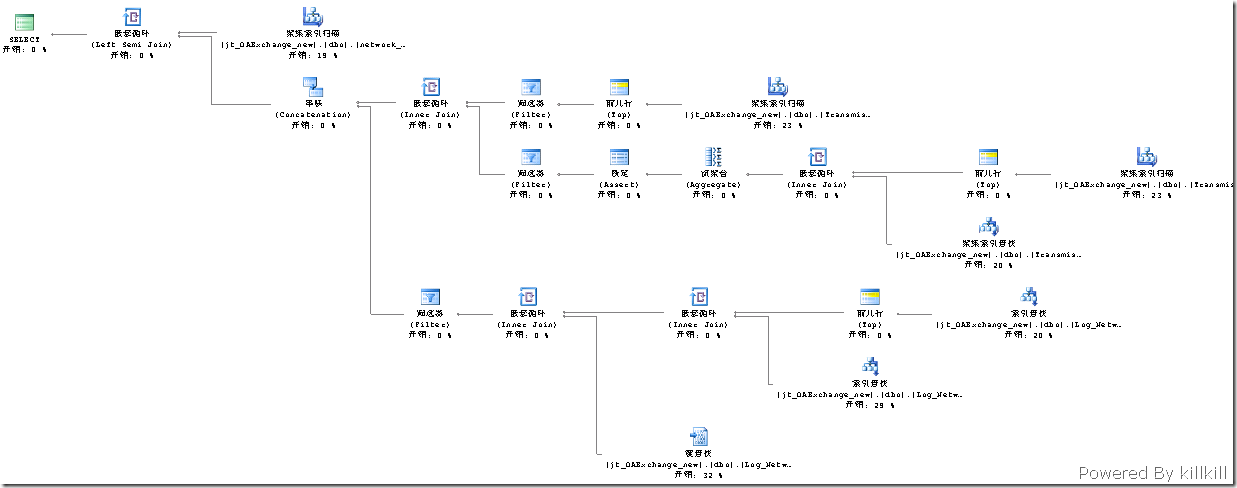
執行計劃如下:
圖太大了,將就著看吧 :( .
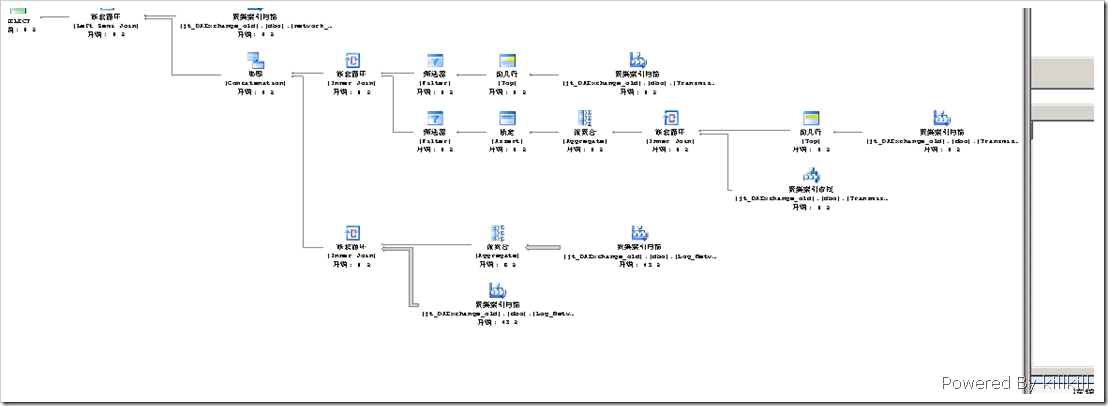
圖3 查詢計劃全圖
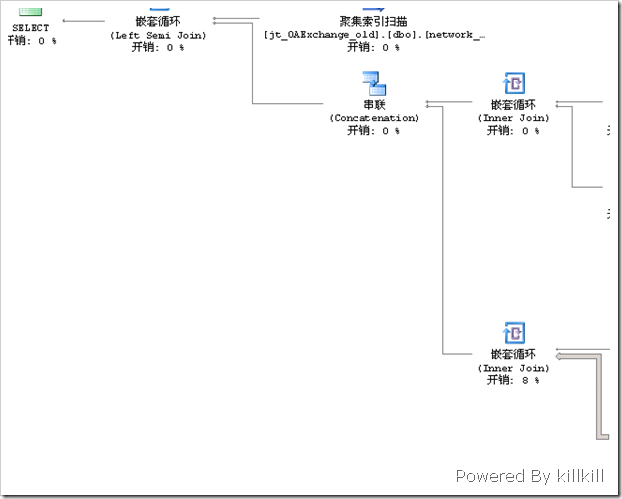
圖4 查詢計劃1
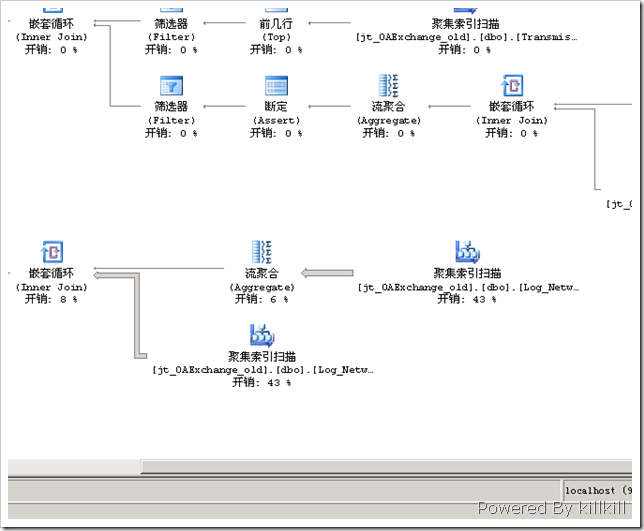
圖5 查詢計劃2
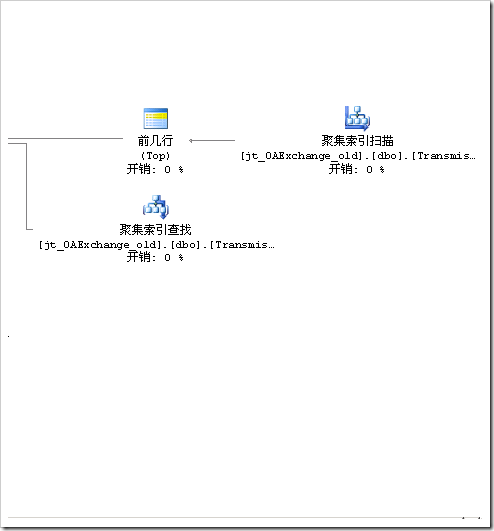
圖6 查詢計劃3
從整個查詢計劃來看,主要開銷都花在了圖5的那個部分——兩個“聚集索引掃描”。
查看一下這兩個數“聚集索引掃描”,搞什麼飛機呢?
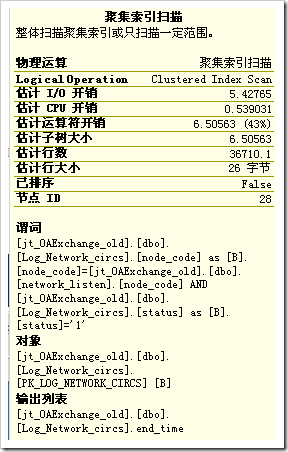
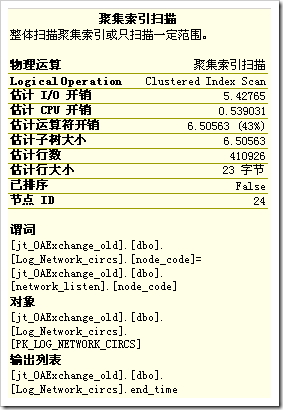
奇怪了,查詢語句裡面沒有Log_Nwtwork_circs 這個表啊,再仔細分析一下這個執行計劃,嫌疑最大的就是view_Log_Network_circsByUnit這個視圖了。
查看一下這個試圖的定義:
CREATEVIEW[dbo].[view_Log_Network_circsByUnit]
AS
SELECTB.*
FROM(
SELECTnode_code,MAX(end_time)ASend_time
FROMLog_Network_circs
GROUPBYnode_code
)A
LEFTOUTERJOIN
dbo.Log_Network_circsB
ON
A.node_code=B.node_code
AND
A.end_time=B.end_time
看著有點暈是吧,那麼看看下圖
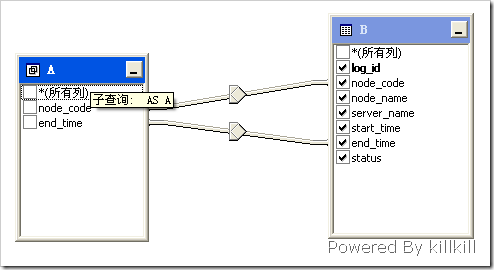
3、優化
SQL寫得好不好,咱不說,反正我是不能改SQL的,而且應該可以判斷出整個查詢最耗時的地方就是用在搞這張試圖了。
那就只能針對這個試圖調優啦。仔細觀察這個試圖,實際上就涉及到一個表 Log_Network_circs,下面是該表的表結構:
CREATETABLE[dbo].[Log_Network_circs](
[log_id][varchar](30)NOTNULL,
[node_code][varchar](100)NULL,
[node_name][varchar](100)NULL,
[server_name][varchar](100)NULL,
[start_time][datetime]NULL,
[end_time][datetime]NULL,
[status][varchar](30)NULL,
CONSTRAINT[PK_LOG_NETWORK_CIRCS]PRIMARYKEYCLUSTERED
(
[log_id]ASC
)WITH(PAD_INDEX =OFF,STATISTICS_NORECOMPUTE =OFF,
IGNORE_DUP_KEY=OFF,ALLOW_ROW_LOCKS =ON,ALLOW_PAGE_LOCKS =ON)ON[PRIMARY]
)ON[PRIMARY]
數據量有489957條記錄,不算太大。
根據 3、經常與其他表進行連接的表,在連接字段上應該建立索引;
感覺上得在 node_code 和 end_time 這兩字段上建立一個復合索引,大概定義如下:
CREATEINDEX[idx__Log_Network]
ONLog_Network_circs
(
node_codeASC,
end_timeASC
)
保險起見,我把需要調優的語句copy到一個文件裡,然後打開“數據庫引擎優化顧問”,設置好數據庫,得出以下調優結果:
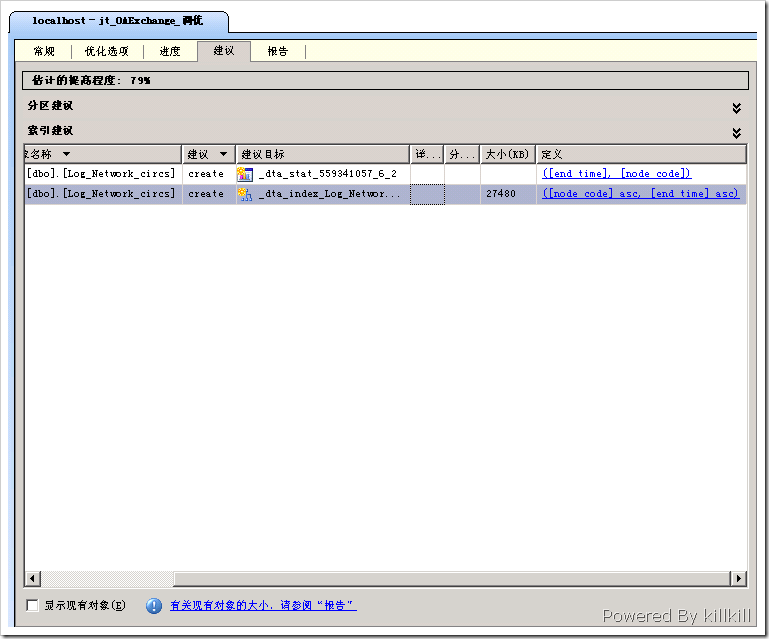
CREATESTATISTICS[_dta_stat_559341057_6_2]ON[dbo].[Log_Network_circs]([end_time],[node_code])
CREATENONCLUSTEREDINDEX[_dta_index_Log_Network_circs_24_559341057__K2_K6]ON[dbo].[Log_Network_circs]
(
[node_code]ASC,
[end_time]ASC
)WITH(SORT_IN_TEMPDB=OFF,IGNORE_DUP_KEY=OFF,DROP_EXISTING=OFF,ONLINE=OFF)ON[PRIMARY]
嗯,結果差不多,具體參數再說。
按照“數據庫引擎優化顧問”給出的建議,建立 STATISTICS 和 INDEX 。
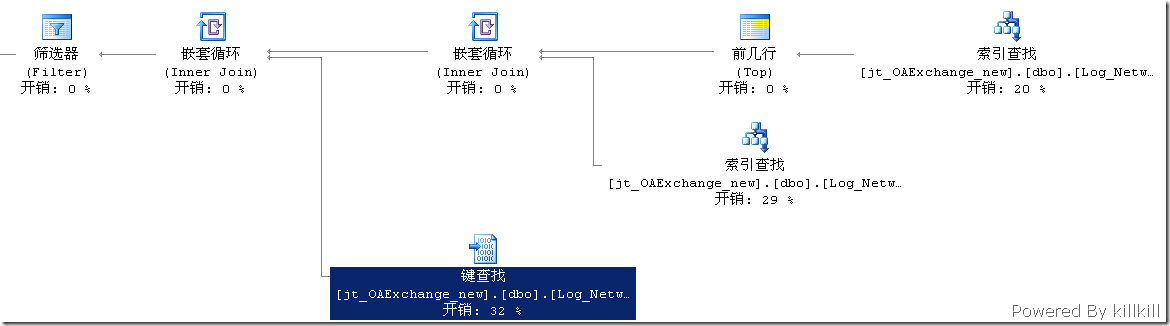
再看看優化後的執行計劃
明顯查詢 view_Log_Network_circsByUnit 這個視圖的執行計劃不一樣了。
不看廣告,看療效,使用統計功能。執行以下語句:
SETSTATISTICSIOon;
SETSTATISTICSTIMEon;
(2行受影響)
表'Log_Network_circs'。掃描計數2,邏輯讀取13558次,物理讀取0次,預讀0次,lob邏輯讀取0次,lob物理讀取0次,lob預讀0次。
表'TransmissionUnit_RouterInfo'。掃描計數0,邏輯讀取2次,物理讀取0次,預讀0次,lob邏輯讀取0次,lob物理讀取0次,lob預讀0次。
表'TransmissionUnit_LocalInfo'。掃描計數3,邏輯讀取6次,物理讀取0次,預讀0次,lob邏輯讀取0次,lob物理讀取0次,lob預讀0次。
表'network_listen'。掃描計數1,邏輯讀取2次,物理讀取0次,預讀0次,lob邏輯讀取0次,lob物理讀取0次,lob預讀0次。
SQLServer執行
CPU時間=719毫秒,占用時間=719毫秒。
(2行受影響)
表'Log_Network_circs'。掃描計數2,邏輯讀取9次,物理讀取0次,預讀0次,lob邏輯讀取0次,lob物理讀取0次,lob預讀0次。
表'TransmissionUnit_RouterInfo'。掃描計數0,邏輯讀取2次,物理讀取0次,預讀0次,lob邏輯讀取0次,lob物理讀取0次,lob預讀0次。
表'TransmissionUnit_LocalInfo'。掃描計數3,邏輯讀取6次,物理讀取0次,預讀0次,lob邏輯讀取0次,lob物理讀取0次,lob預讀0次。
表'network_listen'。掃描計數1,邏輯讀取2次,物理讀取0次,預讀0次,lob邏輯讀取0次,lob物理讀取0次,lob預讀0次。
SQLServer執行
CPU時間=0毫秒,占用時間=2毫秒。
邏輯讀取數,總執行時間都大大縮減,開來調優還是挺成功的