一、設計說明
設計這個自動化的目的是想要交替、重復地使用固定的幾個分區(分區編號01~05)來保存數據,當最後一個分區就是快滿的時候,我們會把最舊數據的分區的數據清空出分區,新數據就可以使用老分區空間了。
應用這個自動化管理分區的環境是有些限制的,其一:分區的數據是呈現遞增的,比如分區字段是自增Id值,或者是以日期作為分區;其二:可以接受 歷史數據被移除分區表帶來的問題。其三:一天進庫的數量不應大於分區管理表PartitionManage中Part_Value與 Change_Value的差,因為我們作業執行的頻率是1天,不過你可以調整Change_Value或者作業的執行頻率;
具體腳本可以參考:SQL Server 2005 自動化刪除表分區設計方案
二、看圖說話
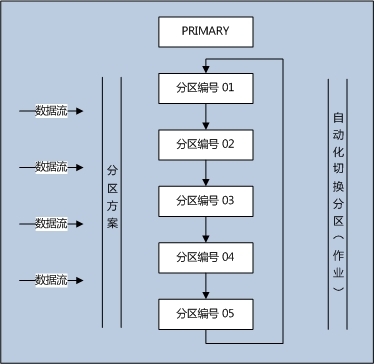
(圖1:整體概念圖)
數據流經過分區方案,被分配到不同的分區中,從圖中可以看出,分區是可以重復利用的,後台有一個所謂的自動化切換分區的作業在跑,目的就是如果 重復利用這些分區。這裡的PRIMARY目的就是說明它與其它文件組的一個平級關系,而且我們在做交換分區時候也會用到PRIMARY,需要事先分配足夠 的空間。
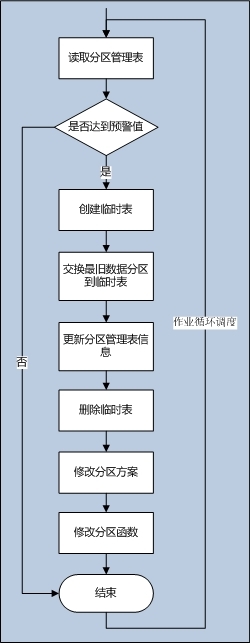
(圖2:自動化設計圖)
這是自動化切換分區作業的邏輯處理,其中分區管理表的設計是比較重要的,它的靈活度關系到整個自動化的效果; 這個邏輯有以下幾個特點:
1. 分區的索引進行存儲位置對齊;其它索引在創建時就使用了分區方案,索引數據跟隨分區數據一起存儲在分區中;
2. 分區管理表,包含了分區記錄數預警設計,在Id達到這個值後就會進行交換分區;
3. 分區管理表,FileGroup_String字段的數據可以通過SQL腳本自動化生成,條件就是分區文件組名稱需要有規律;
4. 臨時表是創建在PRIMARY主分區上,跟原表使用相同的分區方案;需要事先給PRIMARY分配大於或者等於一個分區文件大小的空間,這樣在交換分區的時候就不用增量為主分區分配數據空間;
5. 交換舊數據到臨時表,使用下面的語句可以把數據交換到相同的分區中編號,這樣可以應對臨時表就是一個歷史表,而好處就是歷史表也同樣使用了分區。
ALTER TABLE [tb] SWITCH PARTITION @PARTITION_num TO [Temp_tb] PARTITION@PARTITION_num
6. 這裡需要先修改分區方案,才能修改分區函數,這個跟創建分區函數與分區方案的順序是剛好相反的。
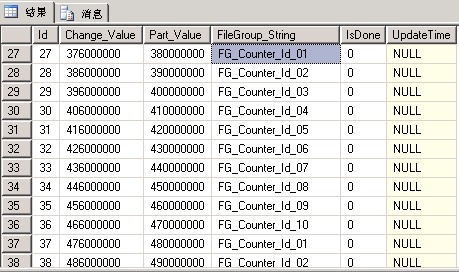
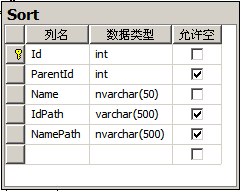
(圖3:分區管理表PartitionManage)
字段說明:Change_Value(預警Id值)Part_Value(分區函數值)FileGroup_String(分區文件組名稱)IsDone(狀態)UpdateTime(更新時間);
這就是那個分區管理表(PartitionManage),它是經過了幾個版本後才把字段確定下來的,現在它已經比較完善了,能應對比較多的情況:
1. 比如我們可以修改預警值(Change_Value),讓數據提早進入交換分區;
2. 比如我們可以修改分區值(Part_Value),達到調整分區間隔的目的;
3. 比如我們可以修改分區文件組名稱(FileGroup_String),達到跳級文件組的目的;通過修改分區管理表來設置分區值與分區文件組的對應關系;
4. 再比如,我們一次性修改了分區方案和分區函數,已經去到很後面的分區值了,那麼我們只要設置這些分區值的狀態(IsDone)為1(True)就可以解決了。
5. 記錄了進行交換分區的時間(UpdateTime),方便查詢;
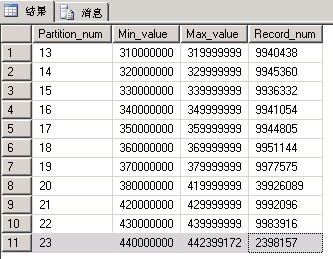
(圖4:分區為Id字段的記錄分布圖)
這是一個實戰中的分區情況,這樣的分區特點就是分區裡面的記錄數基本上是持平的,在Partition_num=20的記錄中明顯多了很多記錄,這就是因為我們沒有及時進行交換分區造成的。
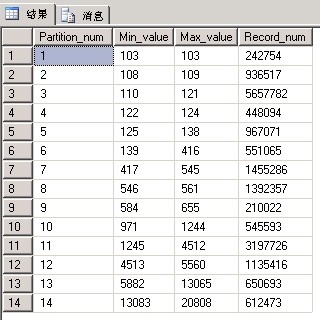
(圖5:分區為ClassId(分類)字段的記錄分布圖)
這同樣是另外一個生產環境中的真實數據,這個分區方式的特點就是分區的記錄數不太均等,而我們前期需要做的就是通過劃分每個分區中ClassId的值來盡量均衡分區中的記錄數,所以可以看到最小與最大值跨度區別是比較大。
(來源:博客園 作者:聽風吹雨)