在上篇文章給大家介紹了SQL Server中的執行計劃緩存(上),本文繼續給大家介紹sqlserver執行計劃緩存相關知識,小伙伴們一起學習吧。
簡介
在上篇文章中我們談到了查詢優化器和執行計劃緩存的關系,以及其二者之間的沖突。本篇文章中,我們會主要闡述執行計劃緩存常見的問題以及一些解決辦法。
將執行緩存考慮在內時的流程
上篇文章中提到了查詢優化器解析語句的過程,當將計劃緩存考慮在內時,首先需要查看計劃緩存中是否已經有語句的緩存,如果沒有,才會執行編譯過程,如果存在則直接利用編譯好的執行計劃。因此,完整的過程如圖1所示。
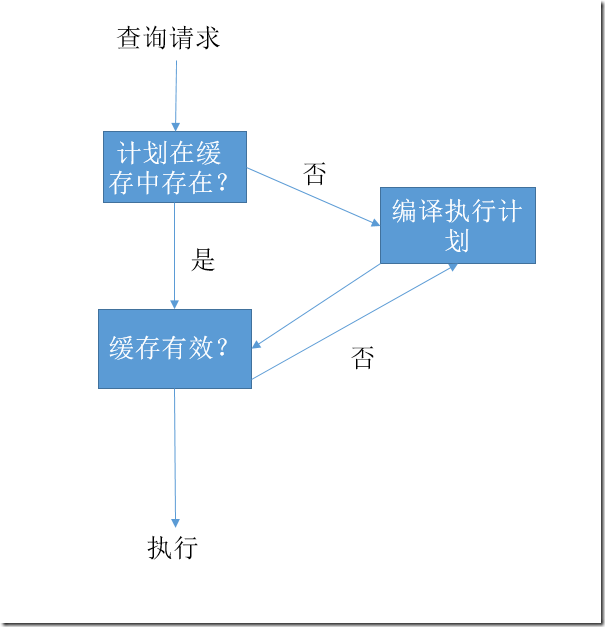
圖1.將計劃緩存考慮在內的過程
圖1中我們可以看到,其中有一步需要在緩存中找到計劃的過程。因此不難猜出,只要是這一類查找,一定跑不了散列(Hash)的數據結構。通過sys.dm_os_memory_cache_hash_tables這個DMV可以找到有關該Hash表的一些信息,如圖2所示。這裡值得注意的是,當執行計劃過多導致散列後的對象在同一個Bucket過多時,則需要額外的Bucket,因此可能會導致查找計劃緩存效率低下。解決辦法是盡量減少在計劃緩存中的計劃個數,我們會在本文後面討論到。
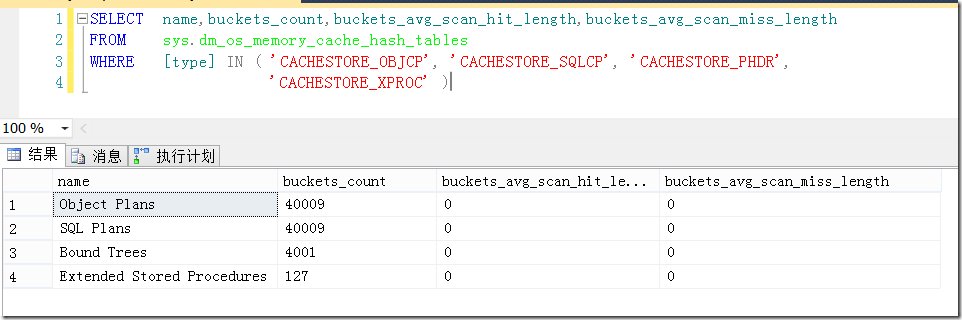
圖2.有關存儲計劃緩存的HashTable的相關信息
當出現這類問題時,我們可以在buckets_avg_scan_miss_length列看出問題。這類情況在緩存命中率(SQL Server: Plan Cache-Cache Hit Ratio)比較高,但編譯時間過長時可以作為考慮對象。
參數化和非參數化
查詢計劃的唯一標識是查詢語句本身,但假設語句的主體一樣,而僅僅是查詢條件謂詞不一樣,那在執行計劃中算1個執行計劃還是兩個執行計劃呢?It's Depends。
假設下面兩個語句,如圖3所示。
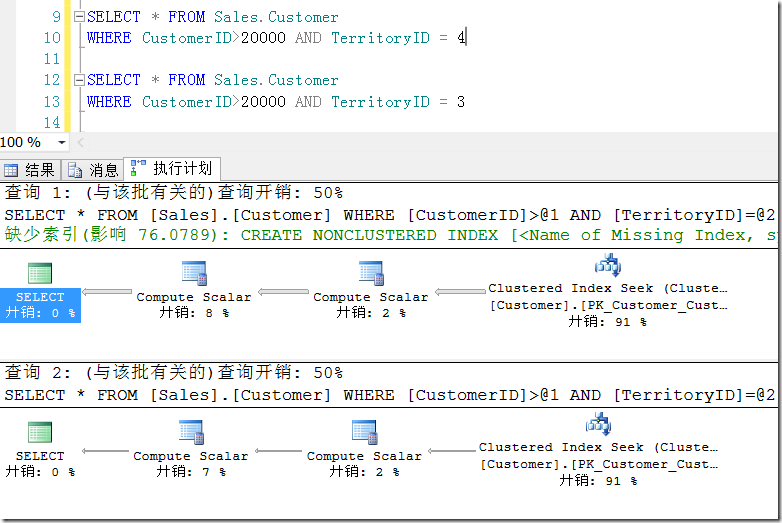
圖3.僅僅謂詞條件不一樣的兩個語句
雖然執行計劃一樣,但是在執行計劃緩存中卻會保留兩份執行計劃,如圖4所示。

圖4.同一個語句,不同條件,有兩份不同的執行計劃緩存
我們知道,執行計劃緩存依靠查詢語句本身來判別緩存,因此上面兩個語句在執行計劃緩存中就被視為兩個不同的語句。那麼解決該問題的手段就是使得執行計劃緩存中的查詢語句一模一樣。
參數化
使得僅僅是某些參數不同,而查詢本身相同的語句可以復用,就是參數化的意義所在。比如說圖3中的語句,如果我們啟用了數據庫的強制參數化,或是使用存儲過程等。SQL Server會將這些語句強制參數話,比如說我們根據圖5修改了數據庫層級的選項。
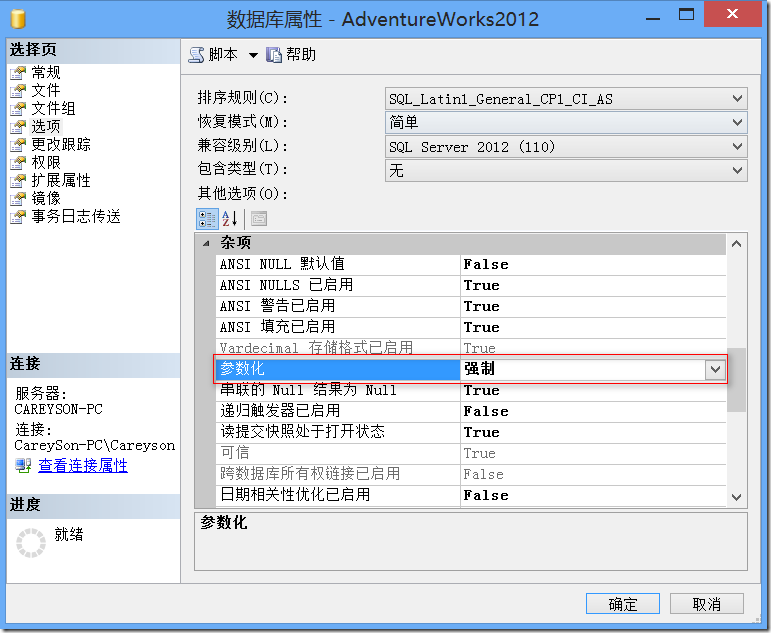
圖5.數據庫層級的選項
此時我們再來執行圖3中的兩條語句,通過查詢執行計劃緩存,我們發現變量部分被參數化了,從而在計劃緩存中的語句變得一致,如圖6所示,從而可以復用.

圖6.參數話之後的查詢語句
但是,強制參數會引起一些問題,查詢優化器很多時候就無法根據統計信息最優化一些具體的查詢,比如說不能應用一些索引或者該掃描的時候卻查找。所產生的負面影響在上篇文章中已經說過,這裡就不細說了。
因此對於上面的問題可以有幾種解決辦法。
平衡參數化和非參數化
在具體的情況下,參數化有些時候是好的,但有些時候卻是性能問題的罪魁禍首,下面我們來看幾種平衡這兩者之間關系的手段。
使用RECOMPILE
當查詢中,不准確的執行計劃的成本要高於編譯的成本時,在存儲過程中使用RECOMPILE選項或是在即席查詢中使用RECOMPILE提示使得每次查詢都會重新生成執行計劃,該參數會使得生成的執行計劃不會被插入到執行計劃緩存中。對於OLAP類查詢來說,不准確的執行計劃所耗費的成本往往高於編譯成本太多,所以可以考慮該參數或選項,您可以如代碼清單1中的查詢所示這樣使用Hint。
SELECT * FROM Sales.Customer WHERE CustomerID>20000 AND TerritoryID = 4 OPTION (recompile)
代碼清單1.使用Recompile
除去我們可以手動提示SQL Server重編譯之外,SQL Server也會在下列條件下自動重編譯:
元數據變更,比如說表明稱改變、刪除列、變更數據類型等。
統計信息變更。
連接的SET參數變化,SET ANSI_NULLS等的值不一樣,會導致緩存的執行計劃不能被復用,從而重編譯。這也是為什麼我們看到緩存的執行計劃中語句一模一樣,但就是不復用,還需要相關的參數一致,這些參數可以通過sys.dm_exec_plan_attributes來查看。
使用Optimize For參數
RECOMPILE方式提供了完全不使用計劃緩存的節奏。但有些時候,特性謂語的執行計劃被使用的次數h更多,比如說,僅僅那些謂語條件產生大量返回結果集的參數編譯,我們可以考慮Optimize For參數。比如我們來看代碼清單2。
DECLARE @vari INT SET @vari=4 SELECT * FROM Sales.Customer WHERE CustomerID>20000 AND TerritoryID = @vari OPTION (OPTIMIZE FOR (@vari=4))
代碼清單2.使用OPTIMIZE FOR提示
使用了該參數會使得緩存的執行計劃按照OPTIMIZE FOR後面的謂語條件來生成並緩存執行計劃,這也可能造成不在該參數中的查詢效率低下,但是該參數是我們選擇的,因此通常我們知道哪些謂語條件會被使用的多一些。
另外,自SQL Server 2008開始多了一個OPTIMIZE FOR UNKNOWN參數,這使得在優化查詢的過程中探測作為謂語條件的局部參數的值,而不是根據局部變量的初始值去探測統計信息。
在存儲過程中使用局部變量代替存儲過程參數
在存儲過程中不使用過程參數,而是使用局部變量相當於直接禁用參數嗅探。畢竟,局部變量的值只有在運行時才能知道,在執行計劃被查詢優化器編譯時是無法知道該值的,因此強迫查詢分析器使用條件列的平均值進行估計。
雖然這種方式使得參數估計變得非常不准確,但是會變得非常穩定,畢竟統計信息不會變更的過於頻繁。該方式不被推薦,如果可能,盡量使用Optimizer的方式。
代碼清單3展示了這種方式。
CREATE PROC TestForLocalVari @vv INT AS DECLARE @vari INT SET @vari=@vv SELECT * FROM Sales.Customer WHERE CustomerID>20000 AND TerritoryID = @vari
代碼清單3.直接引用局部變量,而不是存儲過程參數
強制參數化
在本篇文章的前面已經提到過了強制參數化,這裡就不再提了。
使用計劃指導
在某些情況下,我們的環境不允許我們直接修改SQL語句,比如所不希望破壞代碼的邏輯性或是應用程序是第三方開發,因此無論是加HINT或參數都變得不現實。此時我們可以使用計劃指導。
計劃指導使得查詢語句在由客戶端應用程序扔到SQL Server的時候,SQL Server對其加上提示或選項,比如說通過代碼清單4可以看到一個計劃指導的例子。
EXEC sp_create_plan_guide N'MyPlanGuide1', @stmt=N'SELECT * FROM Sales.Customer WHERE CustomerID>20000 AND TerritoryID=@vari', @type=N'sql', @module_or_batch=NULL, @params=N'@vari int', @hints=N'OPTION (RECOMPILE)'
代碼清單4.對我們前面的查詢設置計劃指導
當加入了計劃指導後,當批處理到達SQL Server時,在查找匹配的計劃緩存時也會去找是否有計劃指導和其相匹配。如果匹配,則應用計劃指導中的提示或選項。這裡要注意的是,這裡@stmt參數必須和查詢語句中的一句一模一樣,差一個空格都會被認為不匹配。
PARAMETERIZATION SIMPLE
當我們在數據庫層級啟用了強制參數化時,對於特定語句,我們卻不想啟用強制參數化,我們可以使用PARAMETERIZATION SIMPLE選項,如代碼清單5所示。
DECLARE @stmt NVARCHAR(MAX) DECLARE @params NVARCHAR(MAX) EXEC sp_get_query_template N'SELECT * FROM Sales.Customer WHERE CustomerID>20000 AND TerritoryID=2', @stmt OUTPUT, @params OUTPUT PRINT @stmt PRINT @params EXEC sp_create_plan_guide N'MyTemplatePlanGuide', @stmt, N'TEMPLATE', NULL, @params, N'OPTION(PARAMETERIZATION SIMPLE)'
代碼清單5.通過計劃指南對單條語句應用簡單參數化
小結
執行計劃緩存希望盡量重用執行計劃,這會減少編譯所消耗的CPU和執行緩存所消耗的內存。而查詢優化器希望盡量生成更精准的執行計劃,這勢必會造成大量的執行計劃,這不僅僅可能引起重編譯大量消耗CPU,還會造成內存壓力,甚至當執行計劃緩存過多超過BUCKET的限制時,在緩存中匹配執行計劃的步驟也會消耗更多的時間。
因此利用本篇文章中所述的方法基於實際的情況平衡兩者之間的關系,就變得非常重要。