Sql server聚合函數在實際工作中應對各種需求使用的還是很廣泛的,對於聚合函數的優化自然也就成為了一個重點,一個程序優化的好不好直接決定了這個程序的聲明周期。Sql server聚合函數對一組值執行計算並返回單一的值。聚合函數對一組值執行計算,並返回單個值。除了 COUNT 以外,聚合函數都會忽略空值。 聚合函數經常與 SELECT 語句的 GROUP BY 子句一起使用。
一.寫在前面
如果有對Sql server聚合函數不熟或者忘記了的可以看我之前的一片博客。
本文中所有數據演示都是用Microsoft官方示例數據庫:Northwind,至於Northwind大家也可以在網上下載。
二.Sql server標量聚合
2.1.概念:在只包含聚合函數的 SELECT 語句列列表中指定的一種聚合函數(如 MIN()、MAX()、COUNT()、SUM() 或 AVG())。當列列表只包含聚合函數時,則結果集只具有一個行給出聚合值,該值由與 WHERE 子句謂詞相匹配的源行計算得到。
2.2.探索標量聚合:
我們先用Sql server的"包括實際的執行計劃"來看看一個簡單的流聚合COUNT()來看看表裡數據所有的行數。
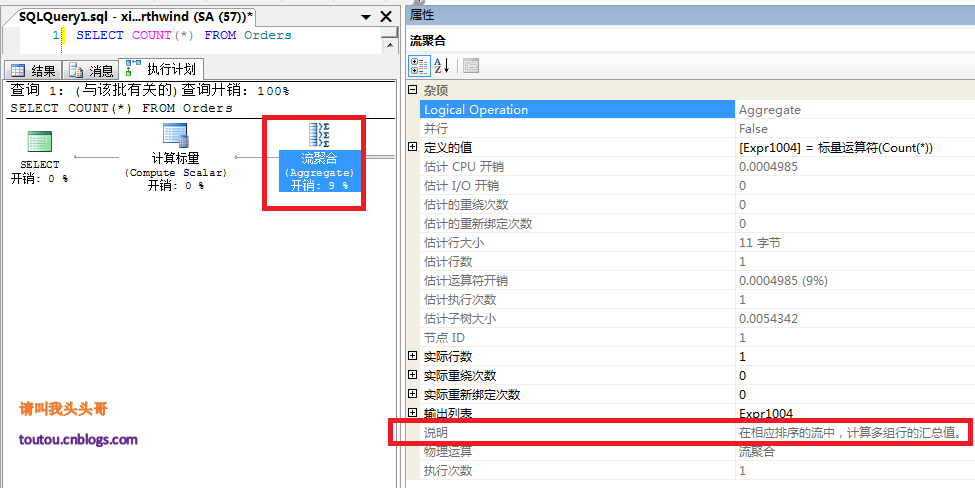
再通過SET SHOWPLAN_ALL ON(關於輸出中包含的列更多信息可以在鏈接中查看)來看看有關語句執行情況的詳細信息,並估計語句對資源的需求。
通過SET SHOWPLAN_ALL ON我們來看看COUNT()具體做了那些事情:
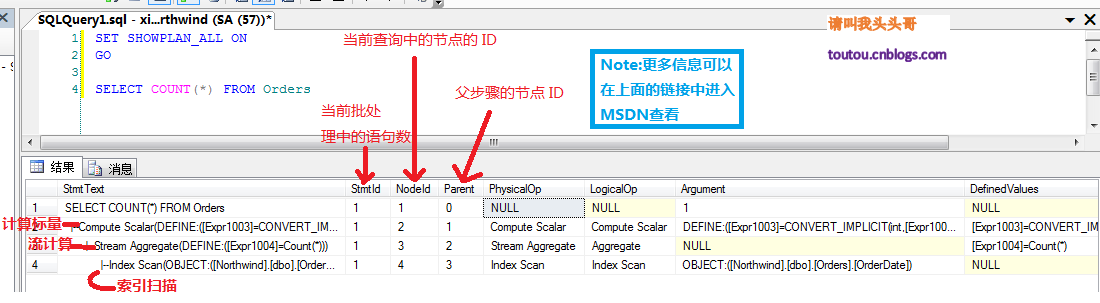
2.3.標量聚合優化技巧:
我們通過兩個比較簡單的sql查詢來看看他們的區別
復制代碼 代碼如下:SELECT COUNT(DISTINCT ShipCity) FROM OrdersSELECT COUNT(DISTINCT OrderID) FROM Orders
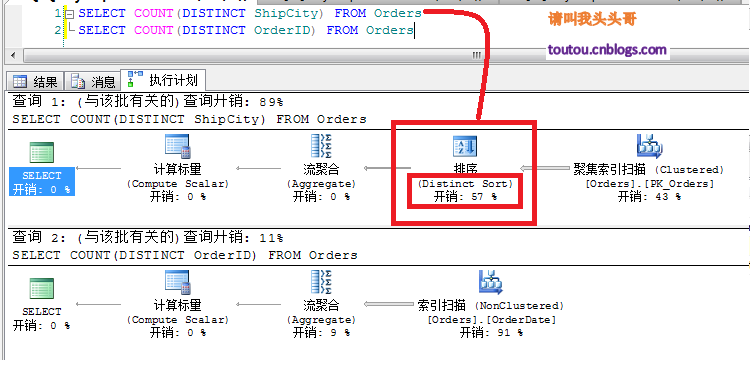
從上圖中可以看到,其實這兩個查詢從語句上來說沒什麼太大的區別,但是為什麼開銷會不一樣,一個是查詢城市一個是查詢訂單號。這是因為其實DISTINCT對於OrderID查詢來說,是沒有什麼意義的,因為OrderID是主鍵,是不會有重復的。而ShipCity是會有重復的,Sql server的去重機制在去重的時候,會有一個排序的過程。這個排序還是比較消耗資源的。
對於數據量比較大的表其實不是很建議對大表排序或者對大表的某個重復次數多的字段去重運算。所以我們這裡可以對ShipCity進行優化一下。可以對ShipCity創建一個非聚集索引。
復制代碼 代碼如下:CREATE INDEX Index_ShipCity On Orders(ShipCity desc)go
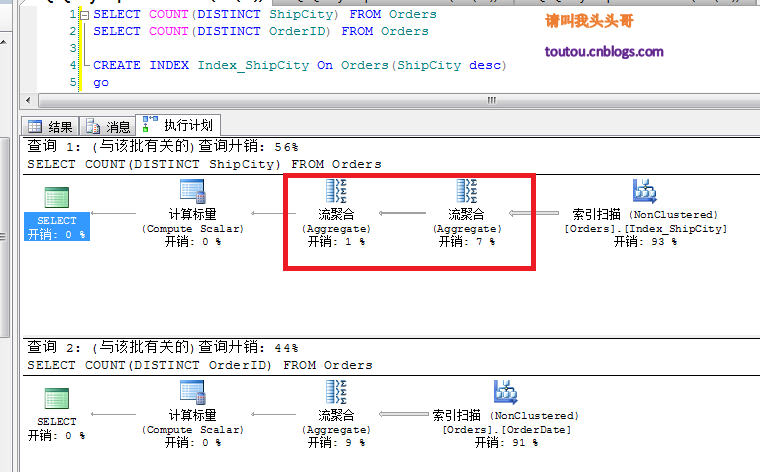
從上圖中可以看到,加了索引以後COUNT(DISTINCT ShipCity)的查詢變成了兩個流聚合,而沒有了排序,節省了開銷。
總結:對於標量聚合從上面的例子大家可以看到,標量聚合優缺點很明顯:
三.Sql server哈希聚合
3.1.概念:
哈希(Hash,一般翻譯做“散列”,也有直接音譯為“哈希”的,就是把任意長度的輸入(又叫做預映射, pre-image),通過散列算法,變換成固定長度的輸出,該輸出就是散列值。這種轉換是一種壓縮映射,也就是,散列值的空間通常遠小於輸入的空間,不同的輸入可能會散列成相同的輸出,所以不可能從散列值來唯一的確定輸入值。簡單的說就是一種將任意長度的消息壓縮到某一固定長度的消息摘要的函數。)
哈希聚合的內部實現方法和哈希連接的實現機制一樣,需要哈希函數的內部運算,形成不同的哈希值,依次並行掃描數據形成聚合值。
3.2.背景:
為了解決流聚合的不足,應對大數據的操作,所以哈希聚合就誕生了。
3.3.分析:
來看看兩個簡單的查詢。
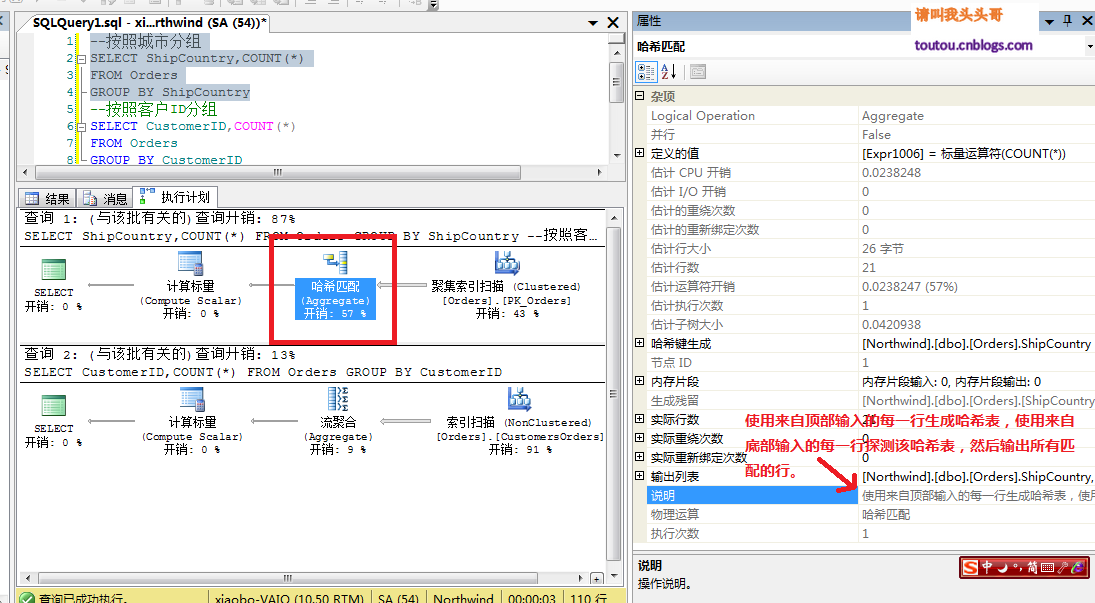
ShipCountry和CustomerID的分組查詢看上去很類似,但是為什麼執行計劃會不同呢?這是因為ShipCountry包含了大量的重復值,CustomerID重復值非常少,所以Sql server系統給ShipCountry推送的哈希聚合,而CustomerID推送的是流聚合。也就是說Sql server系統會動態的根據查詢的情況選擇合適的聚合方式。所以我們在做SQL優化的時候不能僅根據SQL語句來優化,還得結合具體數據分布的環境。
四.運算過程監控指標
4.1.監控元素:
可視化查看運行時間T-sql語句查詢時間占用內存T-sql語句查詢IO
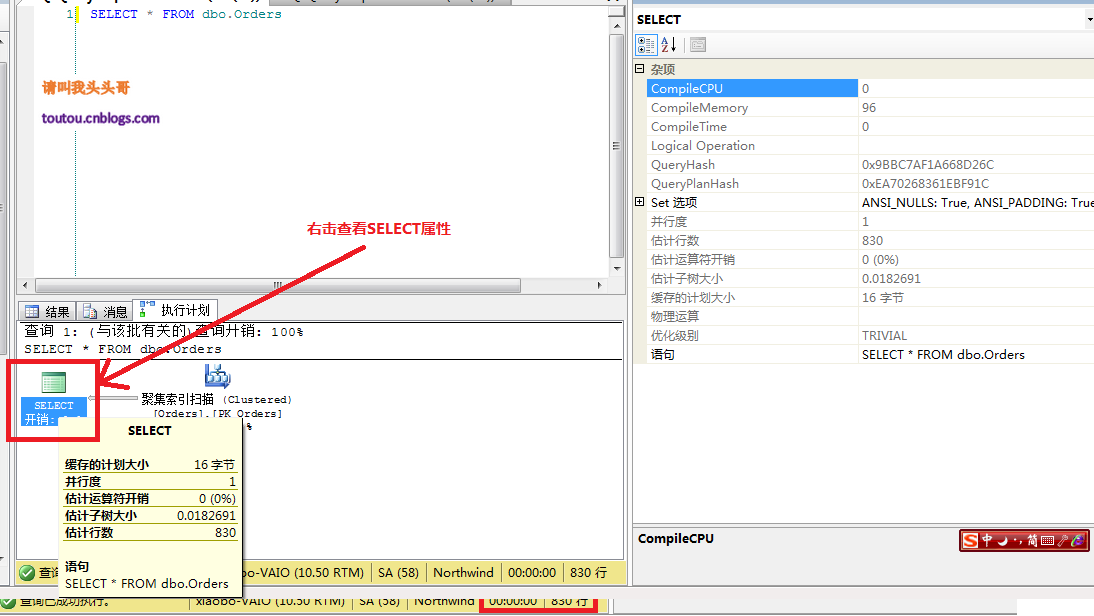
4.2.可視化查看運行時間: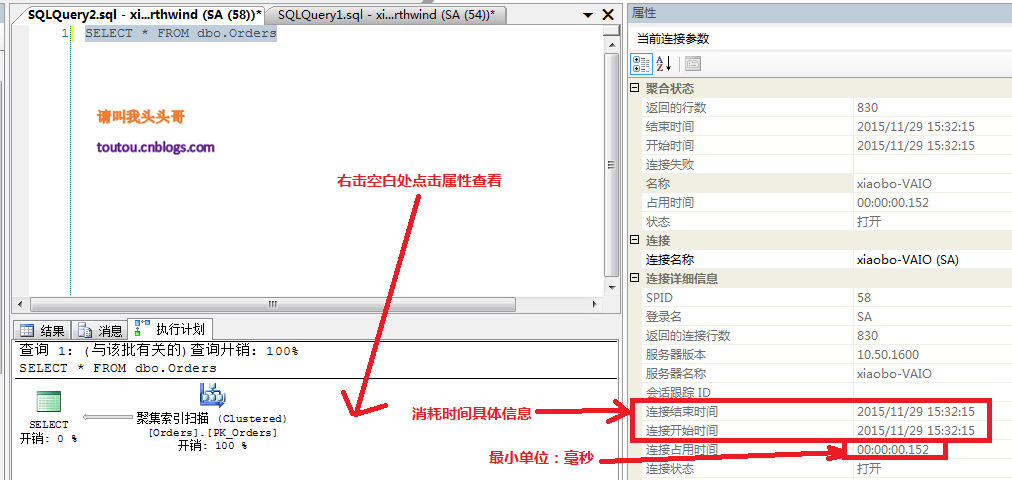
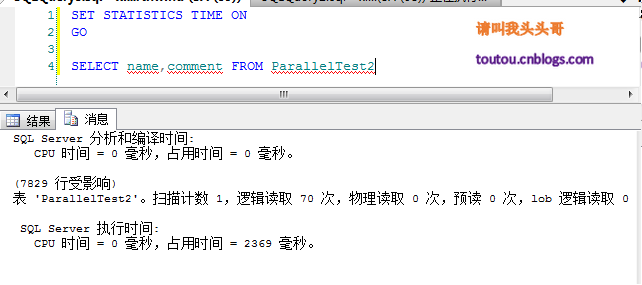
4.3.T-sql語句查詢時間:
4.4.占用內存:
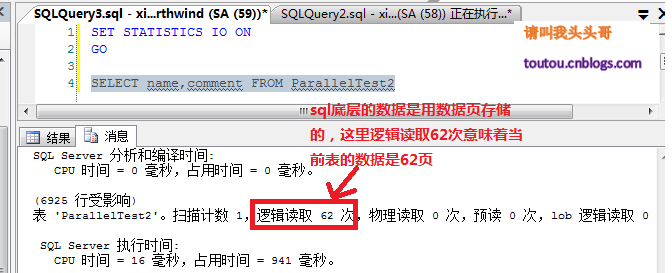
4.5.T-sql語句查詢IO:
關於監控元素還有很多,這裡就列舉幾個。
SQL Server 聚合函數算法優化技巧差不多就介紹到這裡,希望對大家優化聚合函數算法有所幫助。