Sqlserver 獲取每組中的第一條記錄
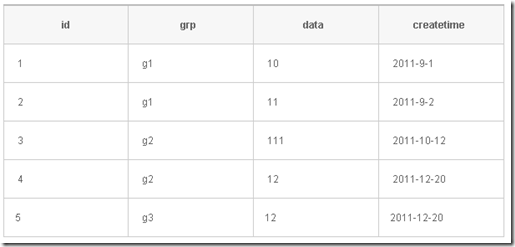
在日常生活方面,我們經常需要記錄一些操作,類似於日志的操作,最後的記錄才是有效數據,而且可能它們屬於不同的方面、功能下面,從數據庫的術語來說,就是查找出每組中的一條數據。下面我們要實現的就是在sqlserver中實現從每組中取出第一條數據。
例子
我們要從上面獲得的有效數據為:
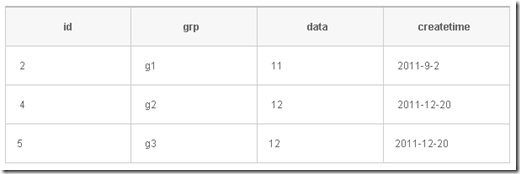
對應的sql語句如下所示:
select * from t1 t where id = (select top 1 id from t1 where grp = t.grp order by createtime desc )
下面給大家介紹oracle查詢取出每組中的第一條記錄
oracle查詢:取出每組中的第一條記錄
按type字段分組,code排序,取出每組中的第一條記錄
方法一:
select type,min(code) from group_info group by type;
注意:select 後面的列要在group by 子句中,或是用聚合函數包含,否則會有語法錯誤。
方法二:
SELECT * FROM( SELECT z.type , z.code ,ROW_NUMBER() OVER(PARTITION BY z.type ORDER BY z.code) AS code_id FROM group_info z ) WHERE code_id =1;
這裡涉及到的over()是oracle的分析函數
參考sql reference文檔:
Analytic functions compute an aggregate value based on a group of rows. They differ from aggregate functions in that they return multiple rows for each group.
Analytic functions are the last set of operations performed in a query except for the final ORDER BY clause. All joins and all WHERE , GROUP BY , and HAVING clauses are completed before the analytic functions are processed. Therefore, analytic functions can appear only in the select list or ORDER BY clause.
語法結構:
analytic_function ([ arguments ]) OVER
(analytic_clause)
其中analytic_clause結構包括:
[ query_partition_clause ]
[ order_by_clause [ windowing_clause ] ]
也就是:函數名( [ 參數 ] ) over( [ 分區子句 ] [ 排序子句 [ 滑動窗口子句 ] ])
這裡PARTITION BY 引導的分區子句類似於聚組函數中的group by,排序子句可看成是select語句中的order by.
mysql 中只獲取1條數據
SELECT * FROM 表 LIMIT 0, 10
LIMIT 接受一個或兩個數字參數。
參數必須是一個整數常量。
如果給定兩個參數,第一個參數指定第一個返回記錄行的偏移量,
第二個參數指定返回記錄行的最大數目。
初始記錄行的偏移量是 0(而不是 1)
主意:limit 用於 having 之後
自己的示例:
select count(1),tpc_equipment_code from tb_parts_consume GROUP BY tpc_equipment_code ORDER BY count(1) DESC LIMIT 1;