伴隨著時間的增長,公司的數據庫會越來越多,查詢速度也會越來越慢。打開數據庫看到幾十萬條的數據,查詢起來難免不廢時間。
要提升SQL的查詢效能,一般來說大家會以建立索引(index)為第一考慮。其實除了index的建立之外,當我們在下SQL Command時,在語法中加一段WITH (NOLOCK)可以改善在線大量查詢的環境中數據集被LOCK的現象藉此改善查詢的效能。
不過有一點千萬要注意的就是,WITH (NOLOCK)的SQL SELECT有可能會造成Dirty Read,就是讀到無效的數據。
下面對於SQLSERVER的鎖爭用及nolock,rowlock的原理及使用作一個簡單描述:
鎖爭用的描述
那些不僅僅使用行級鎖的數據庫使用一種稱為混和鎖(lock escalation)的技術來獲取較高的性能。除非很明確知道是針對整個數據表,否則這些數據庫的做法是開始使用行級鎖, 然後隨著修改的數據增多,開始使用大范圍的鎖機制。
不幸的是,這種混和鎖的方法會產生和放大新的問題:死鎖。如果兩個用戶以相反的順序修改位於不同表的記錄,而這兩條記錄雖然邏輯上不相關, 但是物理上是相鄰的,操作就會先引發行鎖,然後升級為頁面鎖。這樣, 兩個用戶都需要對方鎖定的東西,就造成了死鎖。
例如:
用戶A修改表A的一些記錄,引發的頁面鎖不光鎖定正在修改的記錄,還會有很多其它記錄也會被鎖定。
用戶B修改表B的一些記錄,引發的頁面鎖鎖定用戶A和其它正在修改的數據。
用戶A想修改用戶B在表B中鎖定(並不一定正在修改的)數據。
用戶B想修改或者僅僅想訪問用戶A在表A中鎖定(並不一定正在修改)的數據。
為了解決該問題,數據庫會經常去檢測是否有死鎖存在,如果有,就把其中的一個事務撤銷,好讓另一個事務能順利完成。一般來說,都是撤銷 那個修改數據量少的事務,這樣回滾的開銷就比較少。使用行級鎖的數據庫 很少會有這個問題,因為兩個用戶同時修改同一條記錄的可能性極小,而且由於極其偶然的修改數據的順序而造成的鎖也少。
而且,數據庫使用鎖超時來避免讓用戶等待時間過長。查詢超時的引入也是為了同樣目的。我們可以重新遞交那些超時的查詢,但是這只會造成數據庫的堵塞。如果經常發生超時,說明用戶使用SQL Server的方式有問題。正常情況是很少會發生超時的。
在服務器負載較高的運行環境下,使用混合鎖的SQL Server鎖機制,表現不會很好。 原因是鎖爭用(Lock Contention)。鎖爭用造成死鎖和鎖等待問題。在一個多用戶系統中,很多用戶會同時在修改數據庫,還有更多的用戶在同時訪問數據庫,隨時會產生鎖,用戶也爭先恐後地獲取鎖以確保自己的操作的正確性,死鎖頻繁發生,這種情形下,用戶的心情可想而知。
確實,如果只有少量用戶,SQL Server不會遇到多少麻煩。內部測試和發布的時候,由於用戶較少,也很難發現那些並發問題。但是當激發幾百個並發,進行持續不斷地INSERT,UPDATE,以及一些 DELETE操作時,如何觀察是否有麻煩出現,那時候你就會手忙腳亂地去解鎖。
鎖爭用的解決方法
SQL Server開始是用行級鎖的,但是經常會擴大為頁面鎖和表鎖,最終造成死鎖。
即使用戶沒有修改數據,SQL Server在SELECT的時候也會遇到鎖。幸運的是,我們可以通過SQL Server 的兩個關鍵字來手工處理:NOLOCK和ROWLOCK。
它們的使用方法如下:
SELECT COUNT(UserID) FROM Users WITH (NOLOCK) WHERE Username LIKE 'football'
和
UPDATE Users WITH (ROWLOCK) SET Username = 'admin' WHERE Username = 'football'
NOLOCK的使用
NOLOCK可以忽略鎖,直接從數據庫讀取數據。這意味著可以避開鎖,從而提高性能和擴展性。但同時也意味著代碼出錯的可能性存在。你可能會讀取到運行事務正在處理的無須驗證的未遞交數據。 這種風險可以量化。
ROWLOCK的使用
ROWLOCK告訴SQL Server只使用行級鎖。ROWLOCK語法可以使用在SELECT,UPDATE和DELETE語句中,不過 我習慣僅僅在UPDATE和DELETE語句中使用。如果在UPDATE語句中有指定的主鍵,那麼就總是會引發行級鎖的。但是當SQL Server對幾個這種UPDATE進行批處理時,某些數據正好在同一個頁面(page),這種情況在當前情況下 是很有可能發生的,這就象在一個目錄中,創建文件需要較長的時間,而同時你又在更新這些文件。當頁面鎖引發後,事情就開始變得糟糕了。而如果在UPDATE或者DELETE時,沒有指定主鍵,數據庫當然認為很多數據會收到影響,那樣 就會直接引發頁面鎖,事情同樣變得糟糕。
下面寫一個例子,來說明一下NOLOCK的作用,這裡使用一個有一萬多條的數據庫來測試,先不用NOLOCK來看一下:
declare @start DATETIME; declare @end DATETIME; SET @start = getdate(); select * from Captions_t; SET @end = getdate(); select datediff(ms,@start,@end);
這裡為了是效果更加明顯,使用了Select * ,來看一下執行結果,如下圖:
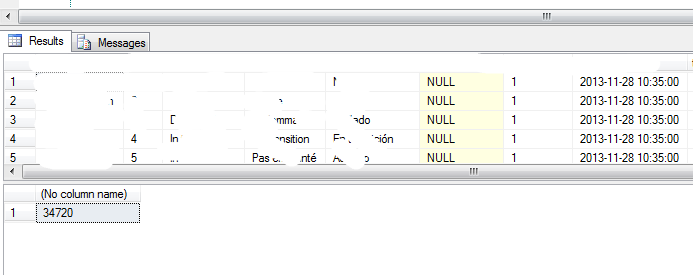
這裡顯示的使用時間是34720ms,下面使用NOLOCK來看一下:
declare @start DATETIME; declare @end DATETIME; SET @start = getdate(); select * from Captions_t18 with (NOLOCK); SET @end = getdate(); select datediff(ms,@start,@end);
運行結果如下圖:
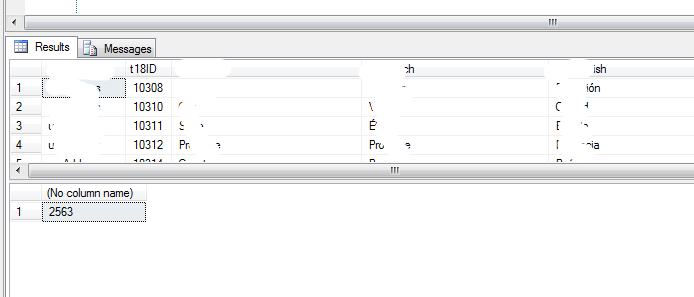
這次使用的時間是2563ms,差距體現出來了吧。個人感覺時間不應該差這麼多,總之性能是提高了不少。
nolock和with(nolock)的幾個小區別:
1.SQL Server 2005中的同義詞,只支持with(nolock);
2.with(nolock)的寫法非常容易再指定索引。
3.跨服務器查詢語句時,不能用with (nolock) 只能用nolock,同一個服務器查詢時則with (nolock)和nolock都可以用。比如:select * from [IP].a.dbo.table1 with (nolock) 這樣會提示錯誤,select * from a.dbo.table1 with (nolock) 這樣就可以成功地查詢。
以上內容就是本文介紹sql server 性能優化之nolock的全部內容,希望對大家有所幫助。