在今天的文章裡,我想給你展示下,當你想對特定查詢創建索引設計時,如何把你的工作和思考過程傳達給查詢優化器。下面就一起來探討一下吧!
有問題的查詢
我們來看下列查詢:
DECLARE @i INT = 999 SELECT SalesOrderID, SalesOrderDetailID, CarrierTrackingNumber, OrderQty, LineTotal FROM Sales.SalesOrderDetail WHERE ProductID < @i ORDER BY CarrierTrackingNumber GO
如你所見,這裡用了一個本地變量與一個不等於謂語來從Sales.SalesOrderDetail表來獲取一些記錄。當你執行那個查詢,看它的執行計劃時,你會發現它有一些嚴重的問題:

現在我問你——你能改善這個查詢麼?你的建議是什麼?休息下,想個幾分鐘。不修改查詢本身,你如何改善這個查詢?
我們來調試查詢!
當然,我們要做索引相關的調整來改善。沒有支持的非聚集索引,那只能是查詢優化器唯一可以使用計劃來運行我們的查詢。但對這個指定查詢,什麼是好的非聚集索引呢?一般來說,我通過看搜索謂語來考慮可能的非聚集速印。在我們的例子裡,搜索謂語如下:
WHERE ProductID < @i
我們請求在ProductID列過濾的行。因此我們想在那個列創建支持的非聚集索引。我們建立索引:
CREATE NONCLUSTERED INDEX idx_Test ON Sales.SalesOrderDetail(ProductID) GO
在非聚集索引創建後,我們需要驗證下改變,因此我們再次執行剛才的查詢代碼。結果如何捏?查詢優化器並沒有使用我們剛創建的非聚集索引!我們在搜索謂語上創建了支持的非聚集索引,查詢優化器沒有引用它?通常人們對此就無轍了。其實我們可以提示查詢優化器來使用非聚集索引,來更好的理解“為什麼”查詢優化器沒有自動選擇索引:
DECLARE @i INT = 999 SELECT SalesOrderID, SalesOrderDetailID, CarrierTrackingNumber, OrderQty, LineTotal FROM Sales.SalesOrderDetail WITH (INDEX(idx_Test)) WHERE ProductID < @i ORDER BY CarrierTrackingNumber GO
當你現在看執行計劃時,你會看到下列的野性——一個並行計劃:
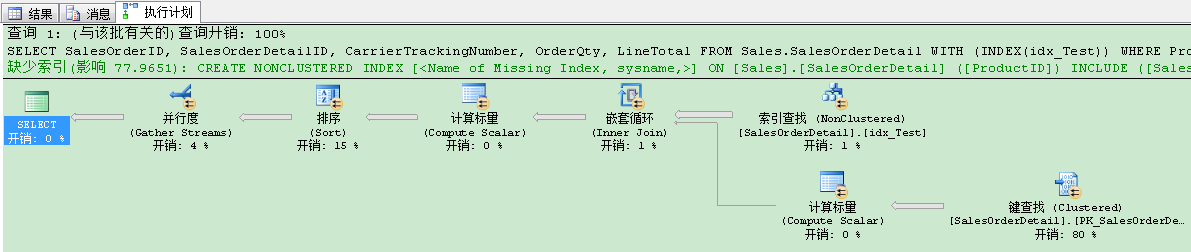

查詢花費了370109個邏輯讀!運行時間基本和剛才的一樣。這裡到底發生了什麼?當你仔細看執行計劃,你會發現查詢優化器引入了書簽查找,因為剛才創建的非聚集索引,對於查詢來說,不是一個覆蓋非聚集索引。查詢越過了所謂的臨界點(Tipping Point),因為我們用當前的搜索謂語來獲得幾乎所有行。因此用非聚集索引和書簽查找來組合沒有意義。
不去想為什麼查詢優化器不選擇剛才創建的非聚集索引,我們已經把自己的思路表達給了查詢優化器本身,通過查詢提示進行了詢問了查詢優化器,為什麼非聚集索引沒被自動選擇。如我剛開始說的:我不想考慮太多。
使用非聚集索引解決這個問題,在非聚集索引的葉子層,我們必須對從SELECT列表的請求的額外列進行包含。你可以再次看下書簽查找來看下在葉子層哪些列當前丟失:
我們重建那個非聚集索引:
CREATE NONCLUSTERED INDEX idx_Test ON Sales.SalesOrderDetail(ProductID) INCLUDE (CarrierTrackingNumber, OrderQty, UnitPrice, UnitPriceDiscount) WITH ( DROP_EXISTING = ON ) GO
我們已經做出了另1個改變,因此我們可以重新運行了查詢來驗證下。但是這次我們不加查詢提示,因為現在查詢優化器會自動選擇非聚集索引。結果如何捏?當你看執行計劃時,索引現在已被選擇。
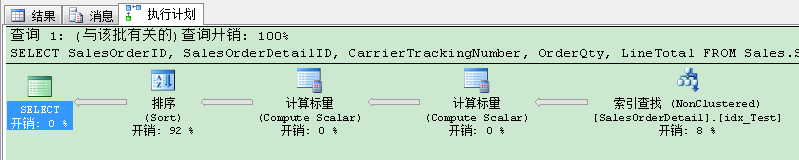

SQL Server現在在非聚集索引上進行了查找操作,但在執行計劃裡我們還有排序(Sort)運算符。因為基數計算30%的硬編碼,排序(Sort)還是要蔓延到TempDb。偶滴神!我們的邏輯讀已經降到了757,但運行時間還是近800毫秒。你現在應該怎麼做?
現在我們可以嘗試在非聚集索引的導航結構直接包含CarrierTrackingNumber列。這是SQL Server進行排序運算符的列。當我們在非聚集索引直接加了這列(作為主鍵),我們就物理排序了那列,因此排序(Sort)運算符應該會消失。作為積極的副作用,也不會蔓延到TempDb。在執行計劃裡,現在也沒有運算符關心錯誤的基數計算。因此我們嘗試那個假設,再次重建非聚集索引:
CREATE NONCLUSTERED INDEX idx_Test ON Sales.SalesOrderDetail(CarrierTrackingNumber, ProductID) INCLUDE (OrderQty, UnitPrice, UnitPriceDiscount) WITH ( DROP_EXISTING = ON ) GO
從索引定義可以看到,現在我們已經對CarrierTrackingNumber和ProductID列的數據物理預排序。當你再次重新執行查詢,在你查看執行計劃時,你會看到排序(Sort)運算符已經消失,SQL Server掃描了非聚集索引的整個葉子層(使用剩余謂語(residual predicate)作為搜索謂語)。
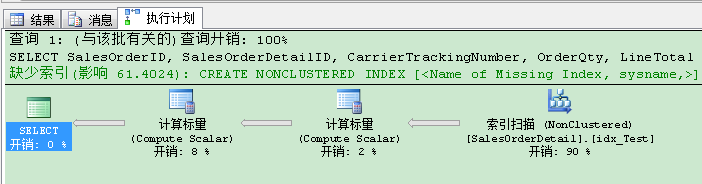

這個執行計劃並不壞!我們只需要763個邏輯讀,現在的運行時間已經降至600毫秒。和剛才的相比已經有25%的改善!但是:查詢優化器建議我們一個更好的非聚集索引,通過缺少索引建議(Missing Index Recommendations)!暫且相信下,我們創建建議的非聚集索引:
CREATE NONCLUSTERED INDEX [SQL Server doesn't care about names, why I should care about names?] ON [Sales].[SalesOrderDetail] ([ProductID]) INCLUDE ([SalesOrderID],[SalesOrderDetailID],[CarrierTrackingNumber],[OrderQty],[LineTotal]) GO
當你現在重新執行最初的查詢,你會發現令人驚訝的事情:查詢優化器使用“我們”剛才創建的非聚集索引,缺少索引建議已經消失!
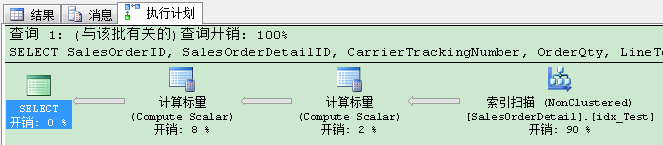
你剛剛創建了SQL Server從不使用的索引——除了INSERT,UPDATE和DELETE語句,SQL Server都要去維護你的非聚集索引。對於你的數據庫,你剛創建了“單純”浪費空間的索引。當另一方面,你已經通過消除丟失索引建議,滿足了查詢優化器。但這不是目的:目的是創建會被再次使用的索引。
結論:永不相信查詢優化器!
小結
今天的文章有點爭議性,但我想你向你展示下,但你在創建索引時,查詢優化器如何幫助你,還有查詢優化器如何愚弄你。因此做出小的調整,就立即運行你的查詢,驗證改變非常重要。
以上就是本文的全部內容,希望對大家的學習有所幫助。