每次講解SQL Server裡的鎖和阻塞(Locking & Blocking)都會碰到的問題:在SQL Server裡,為什麼我們需要更新鎖?在我們講解具體需要的原因前,首先我想給你介紹下當更新鎖(Update(U)Lock)獲得時,根據它的兼容性鎖本身是如何應對的。
一般來說,當執行UPDATE語句時,SQL Server會用到更新鎖(Update Lock)。如果你查看對應的執行計劃,你會看到它包含3個部分:
讀取數據
計算新值
寫入數據
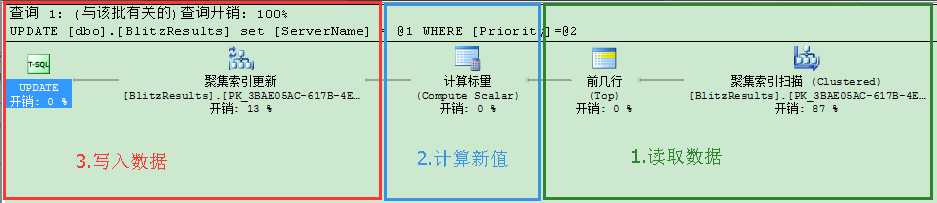
在查詢計劃的第1部分,SQL Server初始讀取要修改的數據,在各個記錄上會獲得更新鎖(Update Locks)。在查詢計劃的最後第3部分,當數據被修改時,這些更新鎖(Update Locks)轉化為排它鎖(Exclusive(X))。用這個方法產生的問題都是一樣的:在第1個階段,SQL Server為什麼要獲得更新鎖(Update Locks),而不是共享鎖(Shared(S) Locks)。平常當你通過SELECT語句讀取數據,共享鎖(Shared(S) Locks)已經夠用了。現在的更新查詢計劃為什麼有這個區別?我們來詳細分析下。
回避死鎖(Deadlock Avoidance)
首先在更新查詢計劃裡,更新鎖用來避免死鎖情形。假設在計劃的第1階段,有多個更新查詢計劃獲得共享鎖(Shared(S)Locks),然後在查詢計劃的第3階段,當數據最後被修改時,這些共享鎖(Shared Locks)轉化為排它鎖(Exclusive Loks),會發生什麼:
第1個查詢不能轉化共享鎖為排它鎖,因為第2個查詢已經獲得了共享鎖。
第2個查詢不能轉化共享鎖為排它鎖,因為第1個查詢已經獲得了共享鎖。
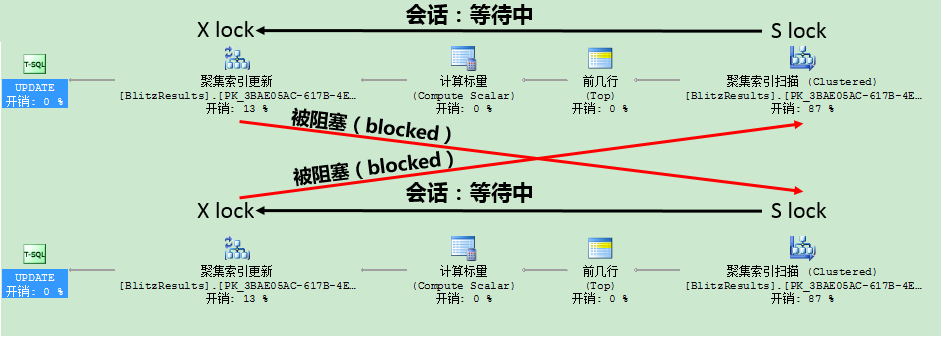
這是其中一個主要原因,為什麼關系數據庫引擎引入更新鎖來實現避免特定的死鎖情形。一個更新鎖只與一個共享鎖兼容,但不與另一個更新或排它鎖兼容。因此死鎖情形可以被避免,應為2個更新查詢計劃不可能同時並發運行。在查詢的第1階段,第2個查詢會一直等到獲得更新鎖。System R的一個未公開研究也展示如何避免這類顯著的死鎖。System R不實用任何更新鎖來實現避免死鎖。
提升的並發
在第1階段不獲得更新鎖,在這個階段直接獲得排它鎖也是可見選項。這會克服死鎖問題,因為排它鎖與另一個排它鎖不兼容。但這個方法的問題是並發受限制,因為同時沒有其他的SELECT查詢可以讀取當前有排它鎖的數據。因此需要更新鎖,因為這個特定鎖與傳統的共享鎖兼容。這樣的話其他的SELECT查詢可以讀取數據,只要這個更新鎖還沒轉化為排它鎖。作為副作用,這會提高我們並發運行查詢的並發性。
在以前關系學術上,更新鎖是所謂的非對稱鎖(Asymmetric Lock)。在更新鎖的上下文裡,這個更新鎖與共享鎖兼容,但反之就不是:共享鎖與更新鎖不兼容。但SQL Server並不把共享鎖作為非對稱鎖實現。更新鎖是個對稱(symmetric)的,就是說更新鎖和共享鎖是彼此雙向兼容的。這會提供系統的整體並發,因為在2個鎖類型鍵不會引入阻塞情形。
小結
在今天的文章裡我給你介紹了共享鎖,還有為什麼需要共享鎖。如你所見在關系數據庫,是強烈需要更新鎖的,因為不然的就會帶來死鎖並降低並發。我希望現在你已經很好的理解了更新鎖,還有在SQL Server裡它們是如何使用的。
以上就是本文的全部內容了,希望大家可以喜歡。