測試用例
我們分別在用戶數據庫(testpage),tempdb中創建相似對象t1,#t1,並在tempdb中創建創建非臨時表,然後執行相應的insert腳本(用以產生日志),並記錄執行時間用以比較用以比較說明tempdb”快”
Code
用戶數據庫testpage
use testpage go create table t1 ( id int identity(1,1) not null, str1 char(8000) ) declare @t datetime2=sysutcdatetime() declare @i int set @i=1 while (@i<100000) begin insert into t1 select @i,'aa' select @i=@i+1 end select [extime]=DATEDIFF(S,@t,sysutcdatetime())
tempdb
use tempdb go create table #t1 ( id int not null, str1 char(8000) ) declare @t datetime2=sysutcdatetime() declare @i int set @i=1 while (@i<100000) begin insert into #t1 select @i,'aa' select @i=@i+1 end select [extime]=DATEDIFF(S,@t,sysutcdatetime())
非臨時表在tempdb中執行
use tempdb go create table t1 ( id int not null, str1 char(8000) ) declare @t datetime2=sysutcdatetime() declare @i int set @i=1 while (@i<100000) begin insert into t1 select @i,'aa' select @i=@i+1 end select [extime]=DATEDIFF(S,@t,sysutcdatetime())
由圖1-1中我們可以看出,在普通表中執行一分鐘的腳本,tempdb只需執行22s.而普通表在tempdb中也只需27s均大大優於普通表中執行情況.
感興趣的朋友亦可在執行過程中觀察日志相關的性能技術器的運行情況如(Log Bytes Flusged \sec 等)
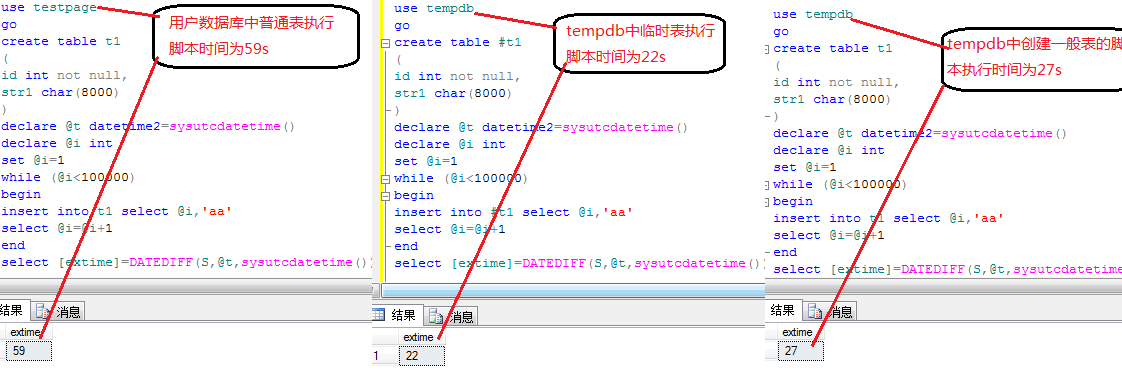
圖1-1
由此測試我們可以看出本文開始提到的”tempdb比其他數據庫快”.
實際並不是tempdb有什麼魔法,而是tempdb的日志機制與其他數據庫大有不同.
Tempdb的日志機制
Tempdb Simple恢復模式(重啟後無需還原操作)
Tempdb使用最小化日志
Tempdb 不受系統CheckPoint影響(系統checkpoint不涉及tempdb,但人為tempdb中執行會落盤)
Tempdb 在刷入數據頁到磁盤前,日志無需落盤(事務提交日志無需落盤)
"快"的原因
可以看到系統檢查點自身會繞過tempdb,tempdb執行時無需日志先落盤.且會最小化日志記錄(關於此一個特性我會稍候陳述)這些都極大的緩解了磁盤IO瓶頸,使得tempdb相比其他DB會快很多.
注意:雖然系統checkpoint檢查點會繞過tempdb,但tempdb中人為執行checkpoint還是會起作用,大家只應測試環境中使用,正式環境中慎用!
在上面的實例中我們可以看到無論在表的類型是什麼,在tempdb中速度都會有很大提升,但普通表的執行時間還是略長於臨時表,這是因為普通表的的日志記錄信息還是要略多於臨時表的.
關於tempdb最小化日志
在堆表(heap)中 insert,update操作的的更新信息日志無需記錄.
我們通過簡單實例來看.
USE [tempdb] GO create table #nclst ( id int identity(1,1) primary key nonclustered,---heaptable str1 char(8000) ); create table #clst ( id int identity(1,1) primary key,------clustered str1 char(8000) ); checkpoint-----生產環境慎用! DBCC SHRINKFILE (N'templog' , 0, TRUNCATEONLY) GO insert into #nclst(str1) select 'aa' select [Current LSN],Operation,CONTEXT,[Log Record Length] from fn_dblog(null,null) where AllocUnitId is not null checkpoint-----生產環境慎用! DBCC SHRINKFILE (N'templog' , 0, TRUNCATEONLY) GO insert into #clst(str1) select 'aa' select [Current LSN],Operation,CONTEXT,[Log Record Length] from fn_dblog(null,null) where AllocUnitId is not null
由圖1-2中可以看出堆表中並未記錄Insert中的#ncls.str1的具體信息,而聚集表中則記錄相應信息
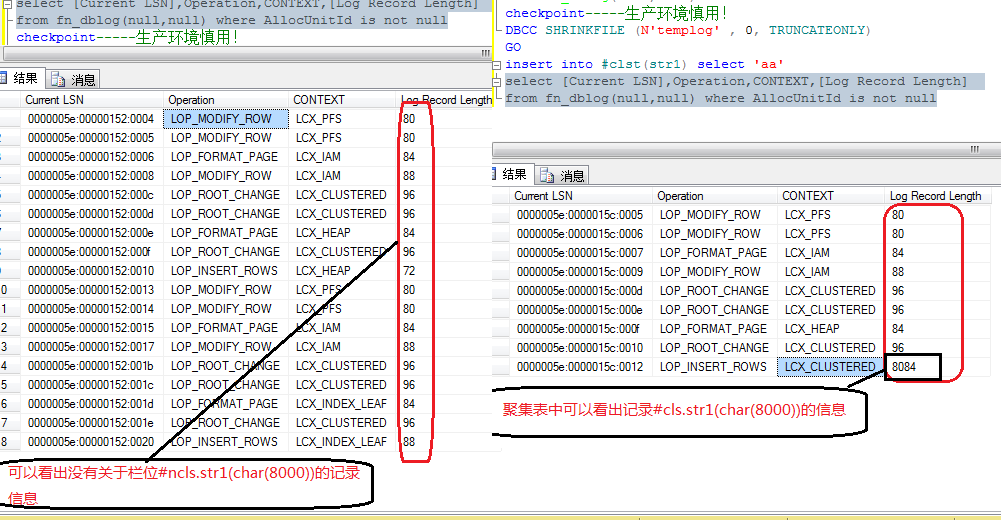
圖1-2
Tempdb為何需要日志
既然tempdb每次重啟都會重新建立,我們無需重做日志,但運行過程中是可能需要回滾的,這也是tempdb日志存在的原因.
Tempdb 不支持重做(Redo)但需支持回滾(rollback).
關於tempdb回滾.
Tempdb中如果日志文件中無足夠空間應用回滾則會引起整個實例就宕機!
Tempdb最佳實踐-日志
a 不要tempdb中checkpoint(消耗巨大引起系統性能下滑)
b 不要tempdb中開啟過長事務(無法截斷日志,造成日志過大,如回滾時無法回滾則宕機)
c 一般需要中間表匹配的過程在tempdb中創建進行(創建速度快,需視具體情況而定.)
d tempdb中使用堆表速度佳.(需視具體情況而定)