簡介
列存儲索引其實在在SQL Server 2012中就已經存在,但SQL Server 2012中只允許建立非聚集列索引,這意味著列索引是在原有的行存儲索引之上的引用了底層的數據,因此會消耗更多的存儲空間,但2012中的限制最大的還是一旦將非聚集列存儲索引建立在某個表上時,該表將變為只讀,這使得即使在數據倉庫中使用列索引,每次更新數據都變成非常痛苦的事。SQL Server 2014中的可更新聚集列索引則解決了該問題。
可更新聚集列存儲索引?
聚集列存儲索引的概念可以類比於傳統的行存儲,聚集索引既是數據本身,列存儲的概念也是同樣。將數據按照列存儲而不是行存儲則提供了諸多好處,
首先對於大量聚合、掃描、分組等數據倉庫類查詢僅僅需要讀取選擇的列,對於需要Join多個表的星型結構等場景性能提升尤其明顯 其次是列索引可以更新,並且每個表中只需要一個(這是優點也是缺點,因為無法再建非聚集索引)聚集列索引即可,大大節省了空間 列索引由於是按列存儲,同一列中數據類型是一樣的,因此可以更加容易的實現更高的壓縮比率 列存儲的表會占用更少的存儲空間,因此存在更少的IO
那麼列存儲索引有什麼弊端呢?
行存儲對於OLTP操作十分適合,因為每個聚集索引鍵可以標識某一行,該行存儲在物理磁盤上也連續,因此可以利用Seek操作完成大量選擇性非常高的查詢,而列存儲索引同一行的每一列並不在物理上聯系,並且列存儲聚集索引中並沒有“主鍵”的概念,因此並不存在SEEK操作,如果大量OLTP類的查詢,性能將會出現問題。
列存儲索引只支持Scan操作,如圖1所示。

圖1.列存儲索引只支持Scan操作
那麼列索引是如何存儲呢?
列索引存儲可以望文生義,就是按列存儲。這個過程可以分為3個階段,首先將一堆行分組,這就是所謂的“行組”,分組完成後,再按列切分,最後將列壓縮,如圖2所示。

圖2.列存儲的過程
我們注意到其中有一部分不夠分組的,那麼就直接讓這部分數據以傳統行存儲的形式老實呆著吧,這就是所謂的Deltastore,等數據增長到可以分組時再進行分組,目前SQL Server 2014認為10W以下的數據都不夠分組。
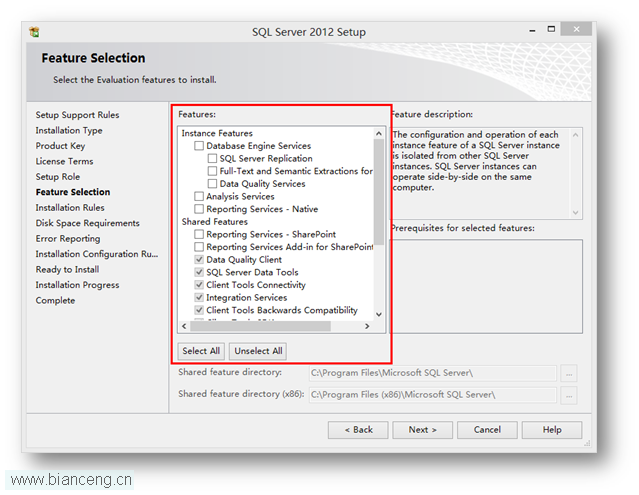
上述列存儲的兩部分我們可以通過2014新引入的DMV進行觀測,如圖3所示。在圖3中,我們隊目前已經存在31465行的聚集列索引插入了1000行新的數據,則SQL Server認為這部分數據不滿10W行,因此以Deltastore的方式存在。

圖3.壓縮後的列和Deltastore
當我們再插入1000數據時,可以觀察到DeltaStore中的數據又增加了1000,達到2000,但依然存在DeltaStore中。如圖4所示。

圖4.再次插入的數據依然在DeltaStore中
那麼我插入大量的行進行觀測,會發現,大批量的數據依然以DeltaStore的方式存儲,如圖5。

圖5.插入大量數據後也無法將數據壓縮
那麼究竟何時會壓縮這些數據呢,根據BOL的說法:http://msdn.microsoft.com/en-us/library/dn223749(v=sql.120).aspx,會有一個後台的線程定期檢測,此外當重建或整理索引時也可以自動歸檔,如圖6所示。

圖6.重建索引後歸檔列存儲索引
空間占用比較
可更新列存儲聚集索引的壓縮比率是最高的,因為同一列往往是同一類數據,因此這類數據有更好的壓縮比。現在我純粹的從傳統聚集索引、頁壓縮、行壓縮、列存儲索引所占用的空間進行比較,當然,如果我們把傳統表的非聚集索引算上,那麼行存儲表將會需要更多的空間。我們用3W多條數據進行簡單比對,如圖7所示。

圖7.不同存儲占用空間
圖7的示例數據很少,但依然可以看到,列存儲比即使沒有非聚集索引的行存儲,占用空間也幾乎少了2/3,提升不可謂不巨大。
性能簡單比較
首先,先按照列存儲,我們選擇所有的列,對於行存儲來說需要選擇整個表才能把一列數據全部讀取出來,但列存儲則只需要讀取被選擇的列,因此如果只選擇特定的列的話,列存儲性能提升巨大,如圖8所示。

圖8.可更新列存儲聚集索引性能提升巨大
但反之,我們嘗試一個典型的OLTP操作,只選擇一行的所有列,則會和圖8的結果大相庭徑了。如圖9所示。

圖9.對於OLTP操作來說,列存儲索引非常乏力
小結
本文闡述了SQL Server 2014中可更新列存儲索引的原理,概念,適用場景、空間使用情況,並舉出兩個OLAP和OLTP極端的例子進行性能比對。列存儲索引對於數據倉庫和類OLAP查詢來說是一個巨大的飛躍。