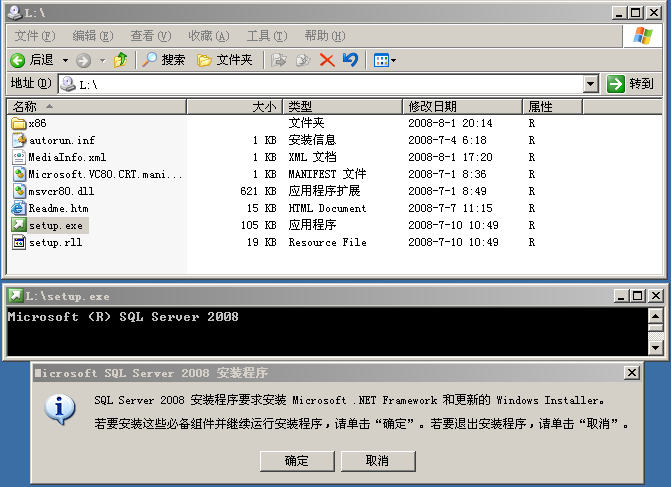
在大數編程語言中,代碼按編碼順序被處理,但是在SQL語言中,第一個被處理的子句是FROM子句,盡管SELECT語句第一個出現,但是幾乎總是最後被處理。
每個步驟都會產生一個虛擬表,該虛擬表被用作下一個步驟的輸入。這些虛擬表對調用者(客戶端應用程序或者外部查詢)不可用。只是最後一步生成的表才會返回 給調用者。如果沒有在查詢中指定某一子句,將跳過相應的步驟。下面是對應用於SQL server 2000和SQL Server 2005的各個邏輯步驟的簡單描述。
復制代碼 代碼如下:
(8)SELECT (9)DISTINCT (11)<Top Num> <select list>
(1)FROM [left_table]
(3)<join_type> JOIN <right_table>
(2) ON <join_condition>
(4)WHERE <where_condition>
(5)GROUP BY <group_by_list>
(6)WITH <CUBE | RollUP>
(7)HAVING <having_condition>
(10)ORDER BY <order_by_list>
邏輯查詢處理階段簡介
1.FROM:對FROM子句中的前兩個表執行笛卡爾積(Cartesian product)(交叉聯接),生成虛擬表VT1
2.ON:對VT1應用ON篩選器。只有那些使<join_condition>為真的行才被插入VT2。
3.OUTER(JOIN):如 果指定了OUTER JOIN(相對於CROSS JOIN 或(INNER JOIN),保留表(preserved table:左外部聯接把左表標記為保留表,右外部聯接把右表標記為保留表,完全外部聯接把兩個表都標記為保留表)中未找到匹配的行將作為外部行添加到 VT2,生成VT3.如果FROM子句包含兩個以上的表,則對上一個聯接生成的結果表和下一個表重復執行步驟1到步驟3,直到處理完所有的表為止。
4.WHERE:對VT3應用WHERE篩選器。只有使<where_condition>為true的行才被插入VT4.
5.GROUP BY:按GROUP BY子句中的列列表對VT4中的行分組,生成VT5.
6.CUBE|ROLLUP:把超組(Suppergroups)插入VT5,生成VT6.
7.HAVING:對VT6應用HAVING篩選器。只有使<having_condition>為true的組才會被插入VT7.
8.SELECT:處理SELECT列表,處理各種聚積函數,並產生VT8.
9.DISTINCT:將重復的行從VT8中移除,產生VT9.
10.ORDER BY:將VT9中的行按ORDER BY 子句中的列列表排序,生成游標(VC10).
11.TOP:從VC10的開始處選擇指定數量或比例的行,生成表VT11,並返回調用者。
注:步驟10,按ORDER BY子句中的列列表排序上步返回的行,返回游標VC10.這一步是第一步也是唯一一步可以使用SELECT列表中的列別名的步驟。這一步不同於其它步驟的 是,它不返回有效的表,而是返回一個游標。SQL是基於集合理論的。集合不會預先對它的行排序,它只是成員的邏輯集合,成員的順序無關緊要。對表進行排序 的查詢可以返回一個對象,包含按特定物理順序組織的行。ANSI把這種對象稱為游標。理解這一步是正確理解SQL的基礎。
因為這一步不返回表(而是返回游標),使用了ORDER BY子句的查詢不能用作表表達式。表表達式包括:視圖、內聯表值函數、子查詢、派生表和共用表達式。它的結果必須返回給期望得到物理記錄的客戶端應用程序。
例如,下面的派生表查詢無效,並產生一個錯誤:
復制代碼 代碼如下:
select *
from(select orderid,customerid from orders order by orderid)
as d
下面的視圖也會產生錯誤
復制代碼 代碼如下:
create view my_view
as
select *
from orders
order by orderid
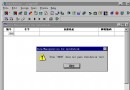
錯誤信息: Msg 1033, Level 15, State 1, Procedure my_viewasselect, Line 2The ORDER BY clause is invalid in views, inline functions, derived tables, subqueries,and common table expressions, unless TOP or FOR XML is also specified. 在SQL中,表表達式中不允許使用帶有ORDER BY子句的查詢,而在T—SQL中卻有一個例外(應用TOP選項)。
所以要記住,不要為表中的行假設任何特定的順序。換句話說,除非你確定要有序行,否則不要指定ORDER BY 子句。排序是需要成本的,SQL Server需要執行有序索引掃描或使用排序運行符。
推薦一段SQL代碼:行列轉置
復制代碼 代碼如下:
/*問題:假設有張學生成績表(tb)如下:
姓名 課程 分數
張三 語文 74
張三 數學 83
張三 物理 93
李四 語文 74
李四 數學 84
李四 物理 94
想變成(得到如下結果):
姓名 語文 數學 物理
---- ---- ---- ----
李四 74 84 94
張三 74 83 93
-------------------
*/
create table tb(姓名 varchar(10),課程 varchar(10),分數 int)
insert into tb values('張三' , '語文' , 74)
insert into tb values('張三' , '數學' , 83)
insert into tb values('張三' , '物理' , 93)
insert into tb values('李四' , '語文' , 74)
insert into tb values('李四' , '數學' , 84)
insert into tb values('李四' , '物理' , 94)
go
--SQL SERVER 2000 靜態SQL,指課程只有語文、數學、物理這三門課程。(以下同)
select 姓名 as 姓名 ,
max(case 課程 when '語文' then 分數 else 0 end) 語文,
max(case 課程 when '數學' then 分數 else 0 end) 數學,
max(case 課程 when '物理' then 分數 else 0 end) 物理
from tb
group by 姓名