1.創建數據庫
啟動命令行,通過輸入如下命令打開Shell模式的CLP:
sqlite3 test.db
雖然我們提供了數據庫名稱,但如果該數據庫不存在,SQLite實際上就未創建該數據庫,直到在數據庫內部創建一些內容時,SQLite才創建該數據庫。
2.創建數據表
sqlite> create table Member(id integer primary key, name text, age integer,addr text);
注:id為主鍵,該列默認具備自動增長的屬性。
3.插入數據
sqlite> insert into Member values(0,'wwl',21,'上海');//id=0的列必須不存在,否則會出錯
或者sqlite> insert into Member(name,age,addr) values('wwl',21,'上海');
3.查詢數據
sqlite>.mode column
sqlite>.headers on
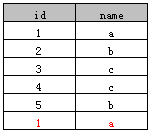
sqlite> select * from Member;
注:select語句前面的兩個命令(.headers和.mode)用於改善顯示格式,可以不要。
4.創建視圖和索引
sqlite> create view schema as select * from Member;
sqlite> create index Member_Idx on Member(id)
5.導出數據
使用.dump命令可以將數據庫對象導出成SQL格式。不帶任何參數時,.dump將整個數據庫導出為數據庫定義語言(DDL)和數據庫操作語言(DML)命令,適合重新創建數據庫對象和其中的數據。如果提供了參數,Shell將參數解析作為表名或視圖,導出任何匹配給定參數的表或視圖,那些不匹配的將被忽略。
默認情況下.dump 命令的輸出定向到屏幕。如:.dump
如果要將輸出重定向到文件,請使用.dump[filename]命令,此命令將所有的輸出重定向到指定的文件中。若要恢復到屏幕的輸出,只需要執行.output stdout命令就OK了。
sqlite>.output file.sql
sqlite>.dump
sqlite>.output stdout
注:如果file.sql不存在,將在當前工作目錄中創建該文件。如果文件存在,它將被覆蓋。
6.導入數據
有兩種方法可以導入數據,用哪種方法取決於要導入的文件格式。如果文件由SQL語句構成,可以使用.read命令導入文件中包含的命令。如果文件中包含由逗號或其他分隔符分割的值(comma-swparated values,CSV)組成,可使用.import[file][table]命令,此命令將解析指定的文件並嘗試將數據插入到指定的表中。
.read命令用來導入.dump命令創建的文件。如果使用前面作為備份文件所導出的file.sql,需要先移除已經存在的數據庫對象,然後用下面的方法重新導入:
sqlite>drop table Member;
sqlite>drop view schema;
sqlite>.read file.sql
7.備份數據庫
有兩種方式可以完成數據庫的備份,具體使用哪一種取決於你希望的備份類型。SQL轉儲許是移植性最好的備份。
生成轉儲的標准方式是使用CLP.dump命令:sqlite3 test.db .dump >test.sql
在Shell中,可以將輸出重定向到外部文件,執行命令,恢復到屏幕輸出,如:
sqlite>.output file.sql
sqlite>.dump
sqlite>.output stdout
sqlite>.exit
同樣,容易將SQL轉儲作為CLP的輸入流實現數據庫導入:
sqlite3 test.db <test.sql
備份二進制數據庫知識比復制文件稍多做一點工作。備份之前需要清理數據庫,這樣可以釋放一些已刪除對象不再使用的空間。這數據庫文件就會變小,因此二進制的副本也會較小:
sqlite3 test.db vacuum
cp test.db test.Backup
8.其它命令
sqlite>select last_insert_rowid(); //獲得最後插入的自動增長量值
sqlite>.tabes //返回所有的表和視圖
sqlite>.indices Member //查看一個表的索引
sqlite>.schema Member //得到一個表或視圖的定義(DDL)語句,如果沒有提供表名,則返回所有數據庫對象(table,view,index,triger)的定義語句