要知道線程等待時間是制約SQL Server效率的重要原因,這一個隨筆中將學習怎樣收集SQL Server中的線程等待時間,類型等信息,這些信息是進行數據庫優化的依據。
sys.dm_os_wait_stats
這是一個系統視圖,裡面存儲線程所遇到的所有的等待信息,具體的列如下表
列名
數據類型
說明
Wait_type
Nvarchar(60)
等待類型名稱
waiting_tasks_count
Bigint
等待類型的等待數。該計數器在每開始一個等待時便會增加。
Wait_time_ms
Bigint
該等待類型的總等待時間。
Max_wait_time_ms
Bigint
該等待類型的最長等待時間。
Signal_wait_time_ms
Bigint
正在等待的線程從收到信號通知到開始運行之間的時差。
要注意的是,這個視圖的信息每次關閉SQL Server的時候都會自動清除,下次打開SQL Server的時候又會重新開始統計。
新建線程等待信息表
如果想得到連續的信息,在固定時間間隔內收集信息比如一個小時一次,這樣就可以分析系統分配的等待時間,識別出繁忙時間段。這裡我們將這些信息收集到一個數據表中保存並進行分析。使用下面的語句新建一個表:
use AdventureWorks
CREATE TABLE dbo.WaitStats
(
dt DATETIME NOT NULL DEFAULT (CURRENT_TIMESTAMP),
wait_type NVARCHAR(60) NOT NULL,
waiting_tasks_count BIGINT NOT NULL,
wait_time_ms BIGINT NOT NULL,
max_wait_time_ms BIGINT NOT NULL,
signal_wait_time_ms BIGINT NOT NULL
);
CREATE UNIQUE CLUSTERED INDEX idx_dt_type ON dbo.WaitStats(dt, wait_type);
CREATE INDEX idx_type_dt ON dbo.WaitStats(wait_type, dt);
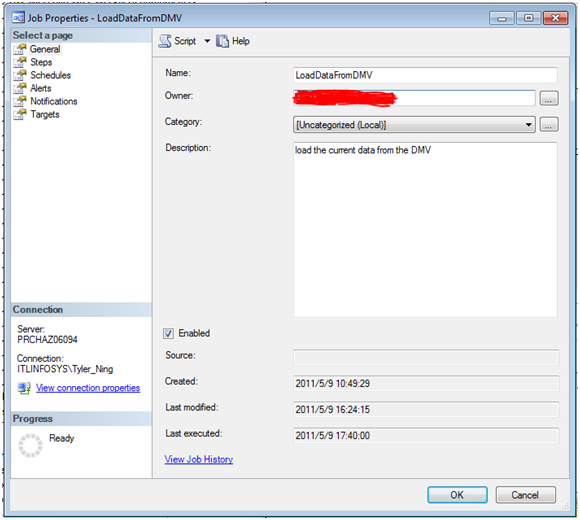
新建job填充數據
要收集信息最好是用一個job來定時地執行insert語句填充數據,下面介紹步驟
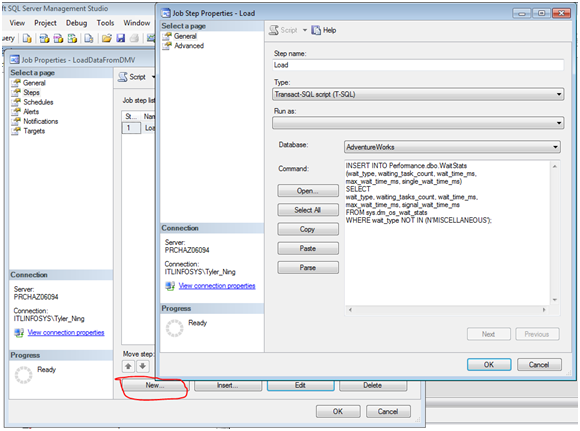
INSERT INTO Performance.dbo.WaitStats
(wait_type, waiting_tasks_count, wait_time_ms,
max_wait_time_ms, signal_wait_time_ms)
SELECT
wait_type, waiting_tasks_count, wait_time_ms,
max_wait_time_ms, signal_wait_time_ms
FROM sys.dm_os_wait_stats
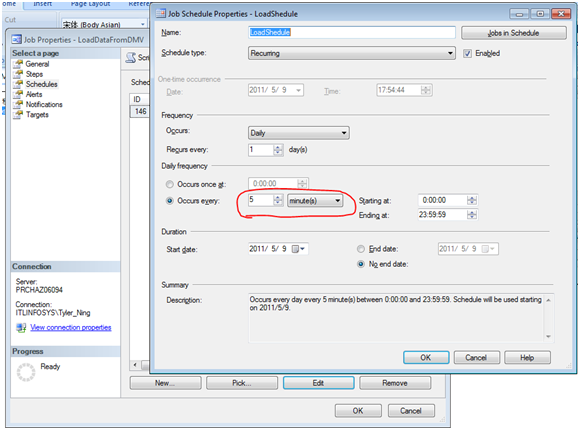
上述步驟包含了新建一個job的主要設置,其他的細節信息沒有包含,遇到具體問題再具體分析吧。
收集等待信息數據
過一段時間之後在表WaitStats中就會有一些數據,每隔5分鐘就會在這個表中寫入一些數據,這些數據會不斷的增加。這裡為了得到相鄰間隔之間 線程等待時間的變化就要使用自連接,連接條件是等待類型相同,當前行號等於上一個的行號加上1,然後就可以用上一次等待時間減去這一次的等待時間得到這個 變化值,下面使用一個函數來實現這個邏輯:
IF OBJECT_ID('dbo.IntervalWaits', 'IF') IS NOT NULL
DROP FUNCTION dbo.IntervalWaits;
GO
CREATE FUNCTION dbo.IntervalWaits
(@fromdt AS DATETIME, @todt AS DATETIME)
RETURNS TABLE
AS
RETURN
WITH Waits AS
(
SELECT dt, wait_type, wait_time_ms,
ROW_NUMBER() OVER(PARTITION BY wait_type
ORDER BY dt) AS rn
FROM dbo.WaitStats
)
SELECT Prv.wait_type, Prv.dt AS start_time,
CAST((Cur.wait_time_ms - Prv.wait_time_ms)
/ 1000. AS NUMERIC(12, 2)) AS interval_wait_s
FROM Waits AS Cur
JOIN Waits AS Prv
ON Cur.wait_type = Prv.wait_type
AND Cur.rn = Prv.rn + 1
AND Prv.dt >= @fromdt
AND Prv.dt < DATEADD(day, 1, @todt)
GO
這個函數接受兩個參數,開始統計時間,結束統計時間,返回等待變化的時間,並按照類型排序。調用這個函數如下:
SELECT wait_type, start_time, interval_wait_s
FROM dbo.IntervalWaits('20110509', '20110510') AS F
ORDER BY SUM(interval_wait_s) OVER(PARTITION BY wait_type) DESC,wait_type,start_time;
但是我們不能每次都去調用這個函數,所以可以吧這個查詢放在一個視圖裡面,外部只需要使用視圖來查詢數據就可以了:
IF OBJECT_ID('dbo.IntervalWaitsSample', 'V') IS NOT NULL
DROP VIEW dbo.IntervalWaitsSample;
GO
CREATE VIEW dbo.IntervalWaitsSample
AS
SELECT wait_type, start_time, interval_wait_s
FROM dbo.IntervalWaits('20090212', '20090215') AS F;
GO
從視圖中查詢得到的數據就是我們要得到的數據。但是這些並不明顯,先寫到這裡,下一個隨筆我將在EXECL中把這些數據制作成一個直方圖或者連線圖,橫軸 是時間,縱軸是等待間隔時間。這樣就會更加直觀地看到在那些時間SQL Server的線程等待時間最長,也就是最繁忙的時候。