來點廢話,最近裸辭,投了一批簡歷,陸陸續續接到很多面試電話,說來也巧,剛回北京,昨 天去面試了第一家,跟研發經理聊了十幾分鐘,就把工作落實下來了,實在是出乎我所料,實在感激他的知遇之恩。於是我就琢磨著下邊的一篇關於數據庫查詢性能 調優的筆記,有問題請大家一起指正。
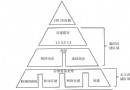
查詢性能調優是個很大的話題,這裡邊涉及到的技術非常廣泛,但是我們一般可以把它大致分為以下幾個層次:
1.減少數據訪問。相關的技術就是建立合適的索引,將全表掃描、索引掃描(scan)等耗時的操作轉化為索引查找(seek)。建立正確的索引,能 讓數據庫查詢性能提升100-1000倍甚至更高,就好比一本非常厚的詞典,如果沒有任何索引,你要查一個東西,那可是相當費盡,需要整本書查一遍,有索 引就可以直接根據索引定位了。這是最重要的改善性能的途徑。
2.減少返回的數據。在網絡中傳輸數據,帶寬是有限的,如果能按需提取最少量的數據,會起到不錯的作用。這裡需要注意的是,在SQL中,不要出現select *,而是需要什麼字段,就提取什麼字段。
3.減少與數據庫交互次數。網絡資源有限,顯然,頻繁與數據庫交互,也是制約性能的一個因素。一個良好的建議就是,使用存儲過程,或者批處理語句,這樣能減少與數據庫的交互,提升一部分性能。
4.減少CPU的負荷。這裡,主要是使用緩存計劃。在查詢中,盡量使用參數化的查詢。這樣的話,數據庫會對查詢參數進行緩存,從而復用查詢計劃。
5.提升硬件性能。這是最後一招了,如果其他方面都已經做得非常不錯了,性能瓶頸在CPU,內存和磁盤上,那采取提升硬件性能的方案就會顯得比較合適了,否則還是先去優化其他的地方吧。
以上5個層次的優化帶來的性能改善,是依次下降的,是一個倒置的金字塔。
下邊詳細討論一下索引的那些事。
百度百科上對索引的描述是:“數據庫索引是對數據庫表中一列或多列的值進行排序的一種結構,使用索引可快速訪問數據庫表中的特定信息。”
索引,分為聚集索引(clustered index)和非聚集索引(nonclustered index)兩種。
a.聚集索引
含有聚集索引的表,叫做聚集表,它的數據行的組織方式,是跟聚集索引的順序是一致的。聚集索引覆蓋的列,叫做聚集鍵。
用新華字典來比喻的話,正文的每一個字就是一個數據行,他們的組織順序是根據拼音,如果拼音相同,就會根據筆畫(不一定准確,見諒),因此,新華字典裡的聚集索引覆蓋的列就是拼音和筆畫。
很容易理解的是,正文只能按照一種既定的順序去排序,同理,在一張表裡,只能有一個聚集索引,從而決定著數據行的組織方式。
b.非聚集索引
非聚集索引,用新華字典來比喻的話,就是字典正文之前的那些按拼音查找,按部首查找,按筆畫查找的附錄。它們描述了正文中的文字的排序位置,但是他們跟正文是分開的。非聚集索引,它跟數據的組織順序是毫無關系的,它用一系列指針來指向數據行,從而來描述數據行的位置。
不含有聚集索引的表,叫做堆表,它的數據行組織順序,是沒有特定順序的,類似於一堆書,增加一本書就放在這堆書的上面(在堆表中,具體實現方式可能不一樣)。
聚集索引對查詢性能影響非常大。聚集表中,非聚集索引是根據聚集鍵來定位的,而堆表中,非聚集索引是根據數據行號來定位的。這將有很大的性能區別,前者的性能大大優於後者。所以,建立合適的聚集索引,是非常必要的。一個好的建議是,使用小字段的且值唯一的列來建立索引,而且最好是單列,可以是代理鍵。因為如果字段太大太多,用來進行排序的開銷將會很大,得不償失;如果列值不唯一,數據庫會為該重復值附加4字節的信息來標識重復值,增加了不必要的開銷。
通常,我們在創建表的時候會指定主鍵,如果不顯式指定索引類型的話,將默認創建聚集 索引。比如:add constraint pk_tbl primary key (sid),將創建以sid為序的聚集索引。可以顯式指定主鍵上的索引類型,比如,add constraint pk_tbl primary key nonclustered (sid),將創建一個非聚集索引的主鍵。所以,在創建主鍵的時候,一定得小心了,有多主鍵的情況,要注意顯式指定索引類型。
索引能大幅度提高查詢和排序性能,但是,在插入,刪除,以及修改了主鍵的操作中,是需要維護索引順序的。如果一張頻繁變更的表,是不宜建立過多的索引的,索引帶來的負面性能影響,將會得不償失。
索引優化,是一個很考究的事情,它需要找到一個平衡點。
一般來說,有以下幾個建議來創建合適的索引:
1.超過300行的數據表要創建索引
2.聚集索引字段不能過多,最好是單字段,而且列值唯一
3.對於數據字段特別多的表,而且這些字段有很多出現在where中,不宜在每一個 字段上建立單獨的索引,而是創建組合索引。組合索引中,列的順序是很講究的,越是選擇性大而且唯一的列要放在前面,這對查詢優化器優化有很大的幫助。不宜 在那些大量重復的列值上建立索引,比如在一個true,false的列上建索引,是毫無意義的。
4.如果查詢中,查詢的字段不多,可以考慮建立覆蓋索引,將字段都包含在索引裡,可以僅僅訪問索引就能查詢到所有數據,而不用表掃描。
查詢語句性能調優,下篇會繼續講。