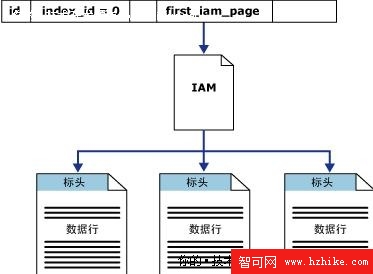
那麼堆表是如何存儲數據的呢?出於簡化的目的,我們先來構造不含任何索引的一張堆數據表,然後從簡單到復雜逐步深入探討。
--創建一張數據表,從系統表生成測試數據
查詢結果如下:
total_pages used_pages data_pages first_page_address root_address IAM_address 25 18 17 1:224 0:0 1:119即SQL Server為該表分配了總計25個頁面,實際使用了18個頁面,扣除1個IAM管理頁面,實際數據頁面為17個,IAM管理頁面地址為第一個文件的第119頁面,數據頁面的第一個頁面為第一個文件的第224頁面。
那麼如何查看到該表的頁面詳細分配情況呢?
首先通過dbcc page(testdb,1,119,3)可以粗略看到頁面分配情況

即SQL Server首先分配了8個混合區頁面,其次因為該對象已經超過8頁,SQL Server又分配了從第472頁到第487頁的頁面,共計16個頁面,然後包括本身的IAM頁面,共計25個頁面。
其次SQL Server還提供了一個更為友好的命令以找到各個類型的頁面分布和它們的所在的文件號和頁號。DBCC IND({'dbname'|dbid},{'objectname'|objectID},
{nonclustered indid|1|0|-1|-2}[,partition_number])
{'dbname'|dbid}表示數據庫名或者數據庫ID
{'objectname'|objectID}表示對象名或者對象ID
{nonclustered indid|1|0|-1|-2}表示顯示行內數據分頁及指定對象的行內IAM分頁信息
1 :顯示所有分頁的信息,包括IAM分頁,數據分頁,所有存在的LOB分頁和行溢出頁,索引分頁
-1: 顯示所有IAM、數據分頁、及指定對象上全部索引的索引分頁.
-2: 顯示指定對象的所有IAM分頁
nonclustered indid:顯示所有的IAM、數據分頁以及一個索引的索引分頁信息。
{partition_number}->可選,為了與中的DBCC IND命令向前兼容.它指定了一個特定分區號,如果不指定,顯示所有分區的信息。
以下是DBCC IND命令輸出結果的字段描述:
字段名稱 字段描述 PageFID 索引文件的ID PageFID 索引文件的ID IAMFID 管理該分頁的IAM分頁所在的文件ID IAMFID 管理該分頁的IAM分頁的ID ObjectID 對象ID IndexID 索引ID,0 代表堆, 1 代表聚集索引, 2-250 代表非聚集索引 PartitionNumber 表或索引所在的分區號碼 PartitionID 包含該分頁的分區ID iam_chain_type 該頁所屬分配單元類型;行內數據、行溢出數據或Lob數據 PageType 分頁類型:1數據頁面;2索引頁面;3Lob_mixed_page;4Lob_tree_page;10IAM頁面 IndexLevel 索引層級,0 代表葉級別分頁 ;>0 代表非葉級別層次; NULL 代表IAM分頁 NextPageFID 本層下一個分頁所在的文件ID NextPageFID 本層下一個分頁ID PrevPageFID 本層上一個分頁所在的文件ID PrevPageFID 本層上一個分頁ID繼續為了簡化的目的,同時因為模擬的是小型數據表,所以可以忽略相關文件號和iam鏈類型、分區號(該表暫無行內遷移和lob字段),我們只需要看看各個數據頁之間是否有相互聯系、各個頁面的類型即可;所以我們構建了一張數據表用以存放dbcc ind命令輸出的結果,並有選擇性的選擇我們想要的字段。
CREATE TABLE tablepage
最終結果如下:
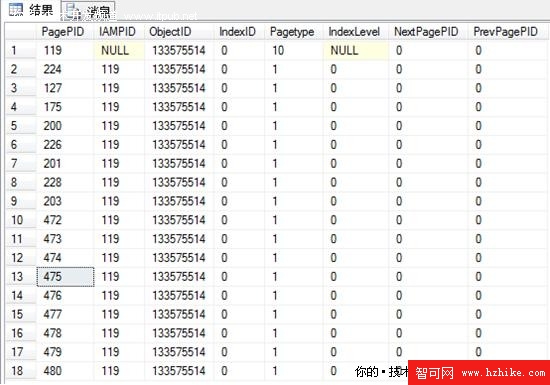
我們可以看到SQL Server為該表所使用的頁面地址,索引ID、頁面類型、索引級別、前後頁的關系等等。
Pagetype=10為IAM頁面,Pagetype=1為數據頁面,即17個數據頁面,1個IAM頁面,與system_internals_allocation_units輸出結果一致,每一個數據頁面都對應該IAM頁面地址,indexid=0表示為堆表,indexlevel=null表示為IAM頁面,indexlevel=0表示為葉子節點;而讓我們感到有些失望的是每一個頁面似乎除了有共同的IAM管理頁面之外,相互之間是缺乏聯系的。
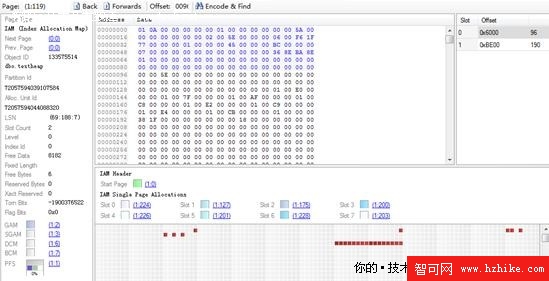
而且從dbcc ind運行的結果來看,每個頁面好像也是不連續的,那麼首先通過Internals VIEwer插件讓我們看一下IAM頁的情況吧,前八頁是斷斷續續的分散分布的,而後面的16頁卻是連續的,再回頭看一下tablepage表也印證了這個現象。既然頁面與頁面之間缺乏聯系,那麼對堆表數據的訪問只能靠IAM頁來管理和定位了。
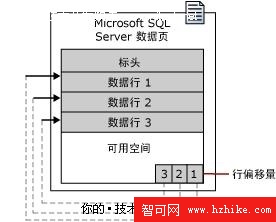
SQL Server數據頁的結構大體包括三個部分,即標頭、數據行和行偏移量。
現在讓我們正式進入數據頁面去看一下數據頁面的構造,讓我們首先去訪問一下該表的數據首頁即第224個頁面。
Dbcc page(testdb,1,224,2)
PAGE HEADER部分,即該頁面的前96個字節。
m_pageId = (1:224)
當前頁面號碼
m_headerVersion = 1
版本號,始終為1
m_type = 1
當前頁面類型,m_type=1表示數據頁面
m_typeFlagBits = 0x4
數據頁和索引頁為4,其他頁為0
m_level = 0
該頁在索引頁(B樹)中的級數,0表示為葉子節點
m_flagBits = 0x8200
頁面標志
m_objId (AllocUnitId.idObj) = 94
m_indexId (AllocUnitId.idInd) = 256
Metadata: AllocUnitId = 72057594044088320
存儲單元的ID,sys.allocation_units.allocation_unit_id
Metadata: PartitionId = 72057594039107584
數據頁所在的分區號,sys.partitions.partition_id
Metadata: IndexId = 0
對象的索引號,sys.objects.object_id&sys.indexes.index_id
Metadata: ObjectId = 133575514
該頁面所屬的對象的id,sys.objects.object_id
m_prevPage = (0:0)
該數據頁的前一頁面
m_nextPage = (0:0)
該數據頁的後一頁面
pminlen = 108
定長數據所占的字節數為108個字節
ID INT IDENTITY(1,1) NOT NULL,
type CHAR(100) NOT NULL,
共計104個字節,每個定長字段需要2個字節的管理字節
m_slotCnt = 62
頁面中的數據的行數,每頁62條記錄
m_freeCnt = 293
頁面中剩余的空間,還剩293字節的空間
m_freeData = 7775
從第一個字節到最後一個字節的空間字節數(包括96字節的文件頭的長度)
m_reservedCnt = 0
活動事務釋放的字節數
m_lsn = (67:272:3)
日志記錄號
m_xactReserved = 0
最新加入到m_reservedCnt領域的字節數
m_xdesId = (0:0)
添加到m_reservedCnt的最近的事務id
m_GhostRecCnt = 0
幻影數據的行數
m_tornBits = 1213019927
頁的校驗位或者被由數據庫頁面保護形式決定分頁保護位取代
上在頁的尾部還有個行偏移矩陣,記錄了每條記錄的起始位置,每條記錄需要2個字節來記錄該位置,所以62條記錄共計124個維護字節,加上293個剩余空間和實際已使用的7775個字節,剛好8192個字節,即一頁。

從Offset table和page結構可以知道,第一條記錄從第96個字節開始。
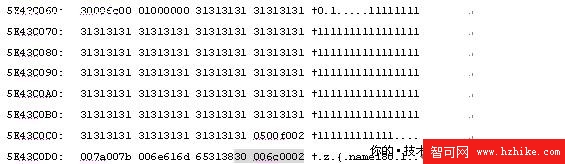
ID name Type other describle 1 name1 1111111111111111111111111111111111. 8 NULL
如前文所說,關於數據的存儲從第96個字節開始
關於數據行的結構我們還可以采用稍微宏觀一些的視角來查看。

其中狀態A為如下說明:
bit0:版本信息,在SQL Server 2005/08總是為0
bit1-3: 0=(primary record);1=(forwarded record);2=(forwarding stud);3=(index record);4=(溢出數據);5=(ghost索引記錄);6=(Ghost數據記錄)
bit4:表示存在NULL位圖(在數據行裡SQL2005/08總存在NULL位圖)
bit5:表示存在變長列
bit6:未啟用
bit7:表示存在幽靈記錄
本例中30->00110000 它是一個行屬性的位圖 從高位存到地位(右邊第一位是bit0),bit4為1即存在變長列的字段,因為在SQLServer2005/2008中總存在NULL位圖,所以bit5也為1。
狀態位B在SQLServer2005//2008中未啟用,所以為00
記錄定長部分的長度為2個字節,是所有定長字段的長度之和加4,該處為int類型4個字節,char(100)為100個字節,再加上4,所以為108,換算成16進制即6c。
緊跟其後的為定長字段的內容,即ID字段的4個字節和TYPE字段的100個字節。
固定長度的字段數據之後,是該表的總字段數,用兩個字節表示,本表包括5個字段所以為05 00。
NULL位圖:f0->11110000 因為該表只有列 所以只需要看後面個,1表示該行的對應列為NULL或者該位圖未使用。本表前4個字段不為空,第5個為空,第6-8未使用。
接下來是行內存儲數據的變長列的數目:0200->00000000 00000010=2 表示該行存儲了列name和other字段的數據。
第一變長列數據終止位置為:7a00->00000000 01111010=122=1+1+2+(4+100)+2+ceiling(5/8)+2+2+2+len(“name1”)
第二變長列數據終止位置:7b00->00000000 01111011=123 實際上就是在前者的基礎上加了第二個變長列的字段長度。
1+1+2+(4+100)+2+ceiling(5/8)+2+2+2+len(“name1”)+len(“8”)
第一列變長列的數據: 6e616d 6531換算成字符即'name1'
第二列變長列的數據:38換算成字符即8
下面讓我們將該記錄的describle字段更新為非空值後,再看看該記錄存儲結構相應的變化。
UPDATE testheap SET describle='abc' WHERE id=1再次使用dbcc page(testdb,1,224,1)命令
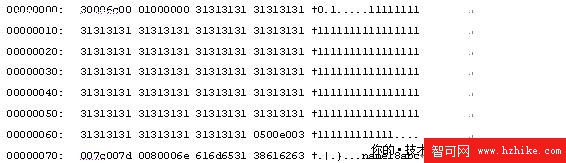
我們不難發現狀態A,狀態B,定長長度、定長內容和字段總數是沒有發生任何變化的。
NULL位圖部分變成了e0即11100000,表示describle字段即第五個字段不為空了
第一個和第二個變長列數據終止位置分別加了2個長度,這是因為當第三個變長列變更為非空後,自動添加了2個字節的第三個字段的維護字段
第一個變長列數據終止位置從7a00變更為7c00
第二個變長列數據終止位置從7b00變更為7d00
新增加的第三個變長列終止位置為8000
同時在第一、二列變長列的數據後面新增加了616263,即字符串”abc”
還有一個最顯著的區別就是該記錄的偏移位置顯然轉到了尾部,即5F1E的位置;但很奇怪的是該記錄原來的位置上還保留著原值,並沒有刪除掉。也就是說對於該記錄而言,應該是先刪除,然後又添加了一條新紀錄,只是把指針指向了新的偏移地址而已。
最後觀察一下記錄是如何刪除的
DELETE FROM testheap WHERE ID IN (2,3)
當我們對比一下刪除前後兩條記錄的信息,發現基本上原來的位置上數據沒有發生任何變化,只是原來的slot1和slot2已經不存在了。即SQL Server認為該數據已經不存在了。

行溢出頁面
USE TESTDB在NAME2字段之前和普通的行記錄信息是一致的,我們只從NAME2字段開始就可以了。NAME2字段在NAME1字段之後,保存了以下內容,即改列的溢出列類型、節點類型、數據庫更新次數、字段長度、指向OVERFLOW頁的指針。
0200 0000 0100 00009d75 0000 8813 0000 77cc0000 0100 0000000 溢出列類型 節點類型 Lob數據更新次數 ID 未知 字段長度 行溢出指針 RowOVerFlow 0 1 1973223424 5000 1:52343:0
讓我們再來看一下第52343頁看一下行溢出頁的數據情況,該頁面首先是一個LOB類型的頁面,然後主要包括該字段的長度、關聯ID,和數據行;很顯然行內數據和溢出行數據的關聯是通過一個行溢出指針和ID進行的;因此對某個數據查詢而言,首先要找到該記錄的信息,同時如果發生行溢出,還有根據該列的行溢出指針和關聯ID,才能找到整條記錄。
1個字節 1個字節 2個字節 8個字節 4個字節 2個字節 08 00 9613 00009d75 00000000 0300 狀態A 狀態B 字段長度 ID unkown 類型 即包含行溢出 5014(同變長字段) 1973223424 未知 lob數據行LOB頁面
從SQL Server 2005版本以後中,新增加了大值數據類型varchar(max)、nvarchar(max)、varbinary(max)。大值數據類型最多可以存儲2^30-1個字節的數據。
從行為上來講這幾個數據類型和之前的數據類型 varchar、nvarchar 和 varbinary 相同。
按照微軟的說法是用這個數據類型來代替之前的text、ntext 和 image 數據類型,它們之間的對應關系為:
varchar(max)-------text;
nvarchar(max)-----ntext;
varbinary(max)----image
對大值數據類型的操作更類似於之前的varchar和varbinary之後,因此用法上也比之前的text和image比靈活和便宜。同時觸發器也可以直接引用大值數據類型;而之前的text和image是不行的。
因此varchar(max)與varchar(n)和text有著千絲萬縷的聯系。對於varbinary(max)也一樣。
因為之前我們已經觀察過varchar(n)的行為,那麼讓我們看看這個新的varchar(max)與varchar(n)、text到底有什麼不同。
CREATE TABLE testVARCHARMAX
運行結果如下:

我們很容易發現兩者的共同之處,就是兩個表都包括LOB_DATA數據類型的分配單元,但是testVARCHARMAX表的LOB_DATA並沒有分配頁面,而testTEXT表卻分配了3個頁面;同時testVARCHARMAX表比testTEXT表多了一個數據頁面,這是怎麼回事呢?
讓我們首先看看testVARCHARMAX表的第217個數據頁面

讓我們通過Internals VIEwer插件看一下對該記錄的解讀
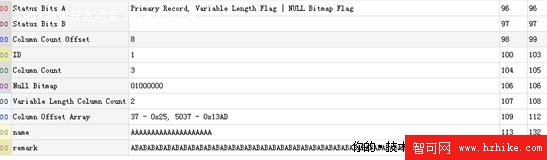
與之前的堆表的介紹相比,基本上我們可以看到與varchar(n)的存儲結構式完全一致的,在此就不多做敘述了。
那麼testTEXT表為什麼會使用到LOB類型頁面呢?我們使用dbcc page命令查看一下。
運行dbcc page(testDB,1,222),我們從第96個字節開始閱讀。
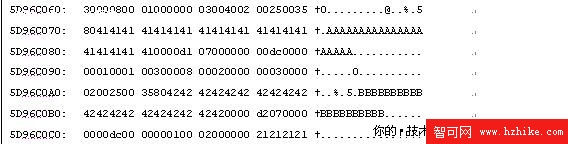
從這個角度,我們看到222頁面類似於前面所講到的行溢出頁面,即在222頁面保留了一個指向行溢出頁面的指針
運行dbcc page(testDB,1,220,2),我們從第96個字節開始閱讀。
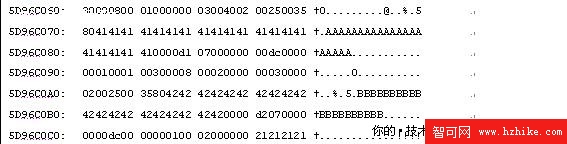
實際上我們從name字段內容之後閱讀就可以了,即0000d1 07000000 00dc0000 00010001 00

是不是有點像縮略版的行溢出信息?
既然有行溢出指針,必然有行溢出頁面,那我們再看看行溢出頁面的數據頁,即220頁面。實際上我們用dbcc page(testdb,1,220,3)閱讀該頁的信息更簡明一些。
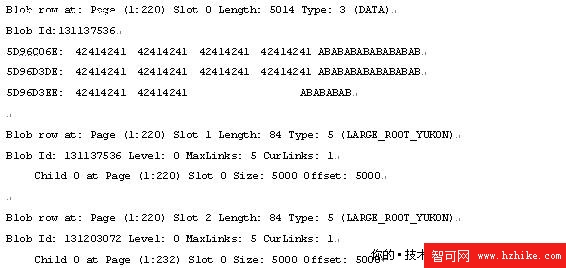
很明顯slot 0記錄了第一條記錄remark字段的長度、數據類型和內容。
Slot 1,slot 2分別為兩個指針,記錄了remark字段的偏移地址和相應的文件號、頁面和槽號
這個與之前的行溢出頁面是有所不同的。